 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Evolution Strategies Using TPUs for Meta-Learning
Jan 01, 2022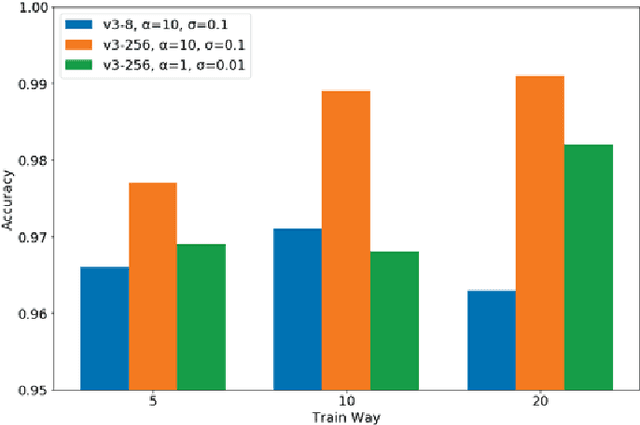
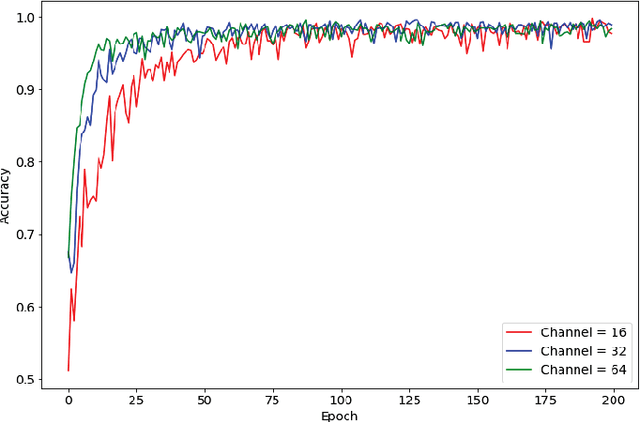
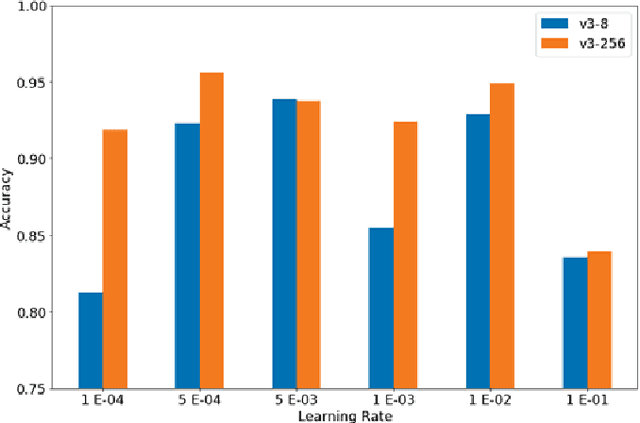
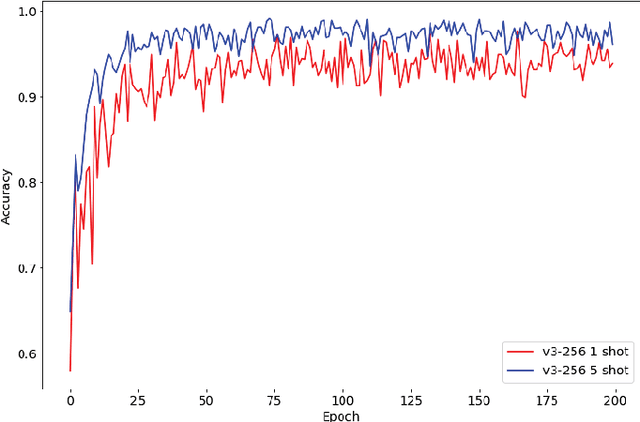
Meta-learning traditionally relies on backpropagation through entire tasks to iteratively improve a model's learning dynamics. However, this approach is computationally intractable when scaled to complex tasks. We propose a distributed evolutionary meta-learning strategy using Tensor Processing Units (TPUs) that is highly parallel and scalable to arbitrarily long tasks with no increase in memory cost. Using a Prototypical Network trained with evolution strategies on the Omniglot dataset, we achieved an accuracy of 98.4% on a 5-shot classification problem. Our algorithm used as much as 40 times less memory than automatic differentiation to compute the gradient, with the resulting model achieving accuracy within 1.3% of a backpropagation-trained equivalent (99.6%). We observed better classification accuracy as high as 99.1% with larger population configurations. We further experimentally validate the stability and performance of ES-ProtoNet across a variety of training conditions (varying population size, model size, number of workers, shot, way, ES hyperparameters, etc.). Our contributions are twofold: we provide the first assessment of evolutionary meta-learning in a supervised setting, and create a general framework for distributed evolution strategies on TPUs.
* Published in Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI)