 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Models
Feb 27, 2025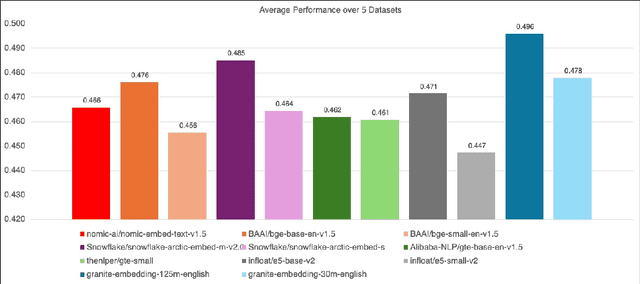



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022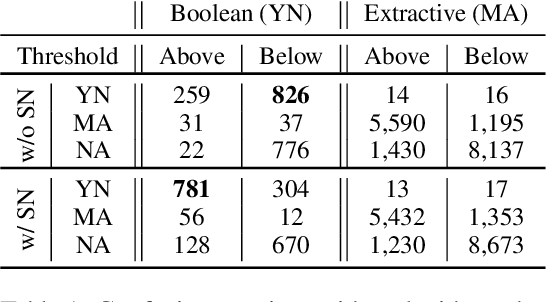
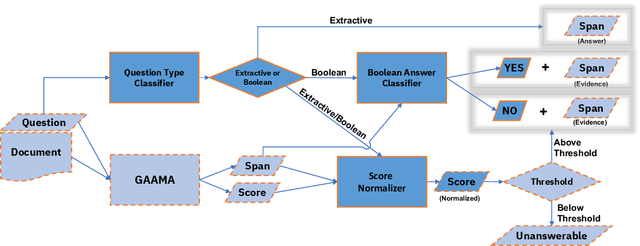


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Do Answers to Boolean Questions Need Explanations? Yes
Dec 14, 2021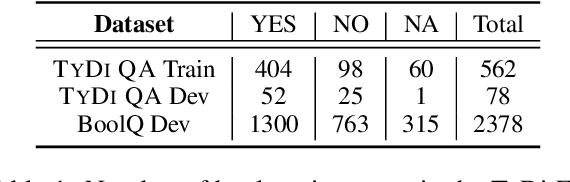


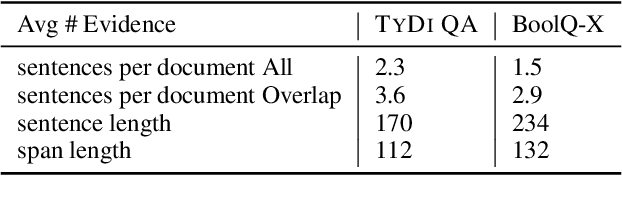
Existing datasets that contain boolean questions, such as BoolQ and TYDI QA , provide the user with a YES/NO response to the question. However, a one word response is not sufficient for an explainable system. We promote explainability by releasing a new set of annotations marking the evidence in existing TyDi QA and BoolQ datasets. We show that our annotations can be used to train a model that extracts improved evidence spans compared to models that rely on existing resources. We confirm our findings with a user study which shows that our extracted evidence spans enhance the user experience. We also provide further insight into the challenges of answering boolean questions, such as passages containing conflicting YES and NO answers, and varying degrees of relevance of the predicted evidence.
Exploring Software Naturalness through Neural Language Models
Jun 24, 2020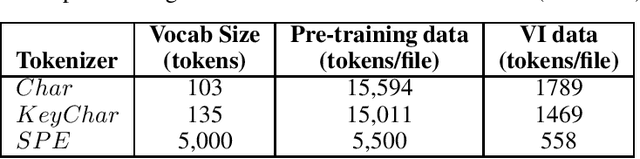
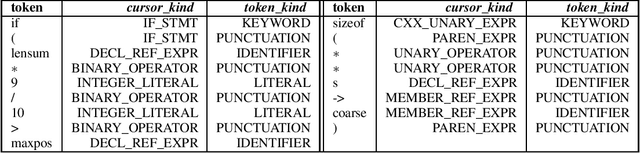
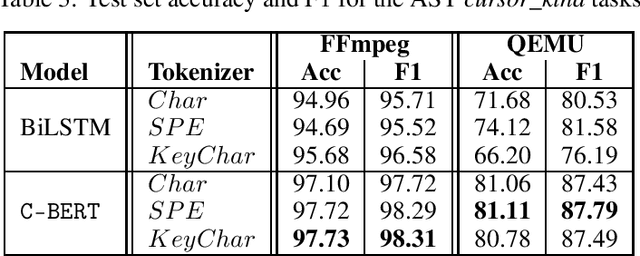
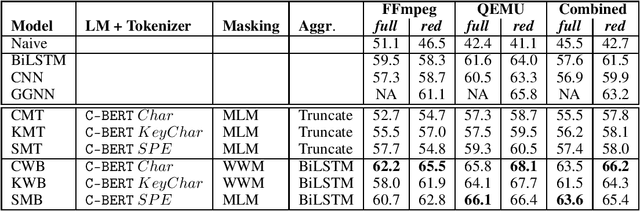
The Software Naturalness hypothesis argues that programming languages can be understood through the same techniques used in natural language processing. We explore this hypothesis through the use of a pre-trained transformer-based language model to perform code analysis tasks. Present approaches to code analysis depend heavily on features derived from the Abstract Syntax Tree (AST) while our transformer-based language models work on raw source code. This work is the first to investigate whether such language models can discover AST features automatically. To achieve this, we introduce a sequence labeling task that directly probes the language models understanding of AST. Our results show that transformer based language models achieve high accuracy in the AST tagging task. Furthermore, we evaluate our model on a software vulnerability identification task. Importantly, we show that our approach obtains vulnerability identification results comparable to graph based approaches that rely heavily on compilers for feature extraction.
The TechQA Dataset
Nov 08, 2019

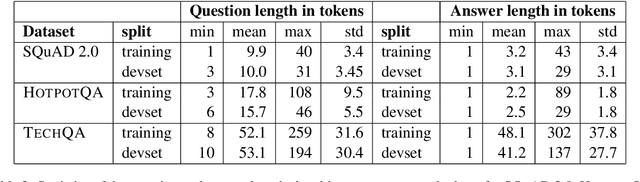
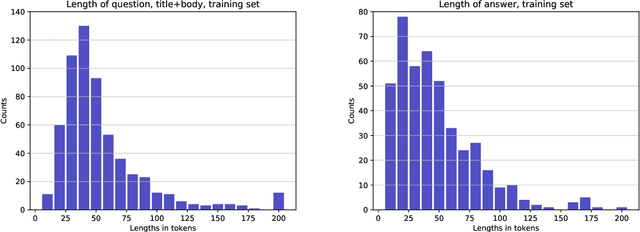
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.