 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Supervision for Chain-of-Thought Reasoning via Monte Carlo Net Information Gain
Mar 18, 2026Multi-step reasoning improves the capabilities of large language models (LLMs) but increases the risk of errors propagating through intermediate steps. Process reward models (PRMs) mitigate this by scoring each step individually, enabling fine-grained supervision and improved reliability. Existing methods for training PRMs rely on costly human annotations or computationally intensive automatic labeling. We propose a novel approach to automatically generate step-level labels using Information Theory. Our method estimates how each reasoning step affects the likelihood of the correct answer, providing a signal of step quality. Importantly, it reduces computational complexity to $\mathcal{O}(N)$, improving over the previous $\mathcal{O}(N \log N)$ methods. We demonstrate that these labels enable effective chain-of-thought selection in best-of-$K$ evaluation settings across diverse reasoning benchmarks, including mathematics, Python programming, SQL, and scientific question answering. This work enables scalable and efficient supervision of LLM reasoning, particularly for tasks where error propagation is critical.
ConstrainedSQL: Training LLMs for Text2SQL via Constrained Reinforcement Learning
Nov 12, 2025Reinforcement learning (RL) has demonstrated significant promise in enhancing the reasoning capabilities of Text2SQL LLMs, especially with advanced algorithms such as GRPO and DAPO. However, the performance of these methods is highly sensitive to the design of reward functions. Inappropriate rewards can lead to reward hacking, where models exploit loopholes in the reward structure to achieve high scores without genuinely solving the task. This work considers a constrained RL framework for Text2SQL that incorporates natural and interpretable reward and constraint signals, while dynamically balancing trade-offs among them during the training. We establish the theoretical guarantees of our constrained RL framework and our numerical experiments on the well-known Text2SQL datasets substantiate the improvement of our approach over the state-of-the-art RL-trained LLMs.
Rationalization Models for Text-to-SQL
Feb 10, 2025We introduce a framework for generating Chain-of-Thought (CoT) rationales to enhance text-to-SQL model fine-tuning. These rationales consist of intermediate SQL statements and explanations, serving as incremental steps toward constructing the final SQL query. The process begins with manually annotating a small set of examples, which are then used to prompt a large language model in an iterative, dynamic few-shot knowledge distillation procedure from a teacher model. A rationalization model is subsequently trained on the validated decomposed queries, enabling extensive synthetic CoT annotations for text-to-SQL datasets. To evaluate the approach, we fine-tune small language models with and without these rationales on the BIRD dataset. Results indicate that step-by-step query generation improves execution accuracy, especially for moderately and highly complex queries, while also enhancing explainability.
Retrieval-Based Transformer for Table Augmentation
Jun 20, 2023Data preparation, also called data wrangling, is considered one of the most expensive and time-consuming steps when performing analytics or building machine learning models. Preparing data typically involves collecting and merging data from complex heterogeneous, and often large-scale data sources, such as data lakes. In this paper, we introduce a novel approach toward automatic data wrangling in an attempt to alleviate the effort of end-users, e.g. data analysts, in structuring dynamic views from data lakes in the form of tabular data. We aim to address table augmentation tasks, including row/column population and data imputation. Given a corpus of tables, we propose a retrieval augmented self-trained transformer model. Our self-learning strategy consists in randomly ablating tables from the corpus and training the retrieval-based model to reconstruct the original values or headers given the partial tables as input. We adopt this strategy to first train the dense neural retrieval model encoding table-parts to vectors, and then the end-to-end model trained to perform table augmentation tasks. We test on EntiTables, the standard benchmark for table augmentation, as well as introduce a new benchmark to advance further research: WebTables. Our model consistently and substantially outperforms both supervised statistical methods and the current state-of-the-art transformer-based models.
KnowGL: Knowledge Generation and Linking from Text
Oct 25, 2022
We propose KnowGL, a tool that allows converting text into structured relational data represented as a set of ABox assertions compliant with the TBox of a given Knowledge Graph (KG), such as Wikidata. We address this problem as a sequence generation task by leveraging pre-trained sequence-to-sequence language models, e.g. BART. Given a sentence, we fine-tune such models to detect pairs of entity mentions and jointly generate a set of facts consisting of the full set of semantic annotations for a KG, such as entity labels, entity types, and their relationships. To showcase the capabilities of our tool, we build a web application consisting of a set of UI widgets that help users to navigate through the semantic data extracted from a given input text. We make the KnowGL model available at https://huggingface.co/ibm/knowgl-large.
Knowledge Graph Induction enabling Recommending and Trend Analysis: A Corporate Research Community Use Case
Jul 18, 2022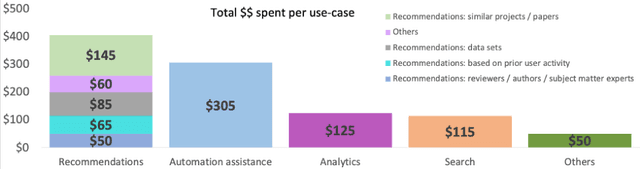

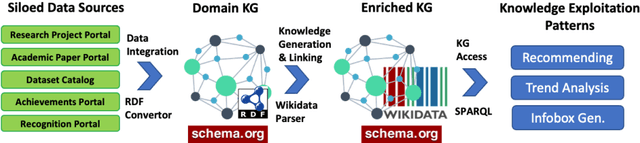
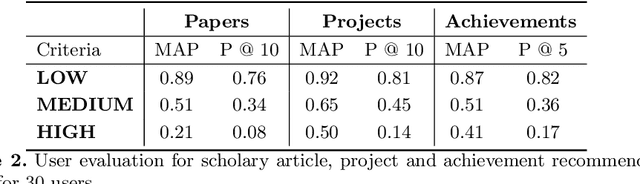
A research division plays an important role of driving innovation in an organization. Drawing insights, following trends, keeping abreast of new research, and formulating strategies are increasingly becoming more challenging for both researchers and executives as the amount of information grows in both velocity and volume. In this paper we present a use case of how a corporate research community, IBM Research, utilizes Semantic Web technologies to induce a unified Knowledge Graph from both structured and textual data obtained by integrating various applications used by the community related to research projects, academic papers, datasets, achievements and recognition. In order to make the Knowledge Graph more accessible to application developers, we identified a set of common patterns for exploiting the induced knowledge and exposed them as APIs. Those patterns were born out of user research which identified the most valuable use cases or user pain points to be alleviated. We outline two distinct scenarios: recommendation and analytics for business use. We will discuss these scenarios in detail and provide an empirical evaluation on entity recommendation specifically. The methodology used and the lessons learned from this work can be applied to other organizations facing similar challenges.
Re2G: Retrieve, Rerank, Generate
Jul 13, 2022
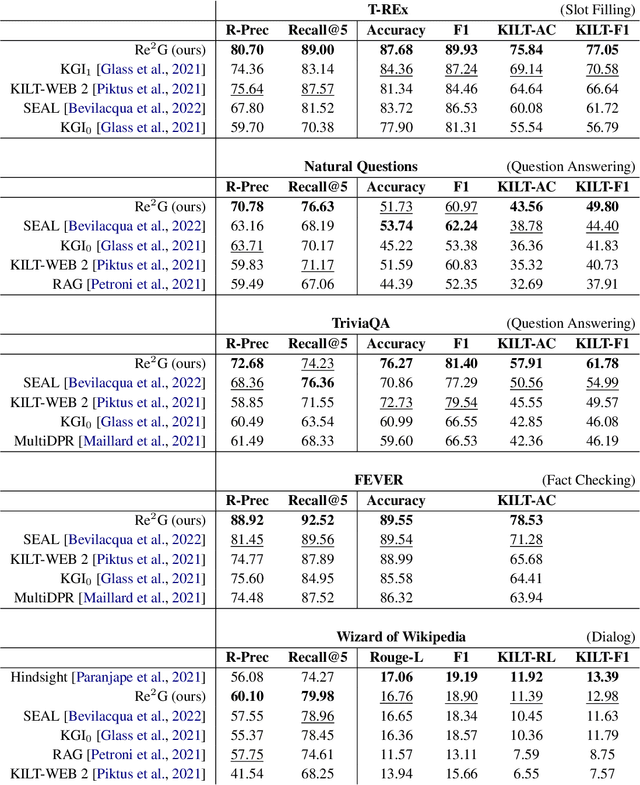
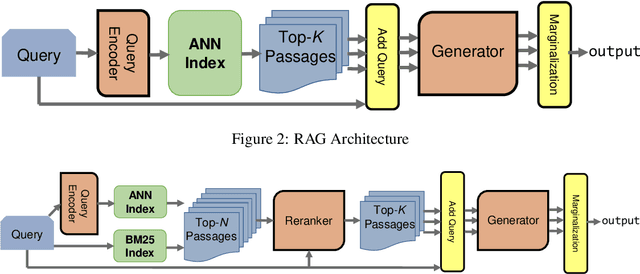
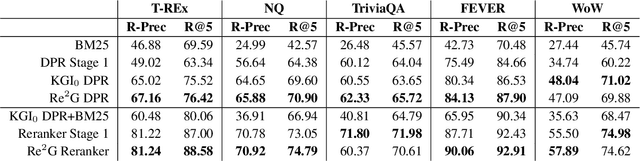
As demonstrated by GPT-3 and T5, transformers grow in capability as parameter spaces become larger and larger. However, for tasks that require a large amount of knowledge, non-parametric memory allows models to grow dramatically with a sub-linear increase in computational cost and GPU memory requirements. Recent models such as RAG and REALM have introduced retrieval into conditional generation. These models incorporate neural initial retrieval from a corpus of passages. We build on this line of research, proposing Re2G, which combines both neural initial retrieval and reranking into a BART-based sequence-to-sequence generation. Our reranking approach also permits merging retrieval results from sources with incomparable scores, enabling an ensemble of BM25 and neural initial retrieval. To train our system end-to-end, we introduce a novel variation of knowledge distillation to train the initial retrieval, reranker, and generation using only ground truth on the target sequence output. We find large gains in four diverse tasks: zero-shot slot filling, question answering, fact-checking, and dialog, with relative gains of 9% to 34% over the previous state-of-the-art on the KILT leaderboard. We make our code available as open source at https://github.com/IBM/kgi-slot-filling/tree/re2g.
KGI: An Integrated Framework for Knowledge Intensive Language Tasks
Apr 08, 2022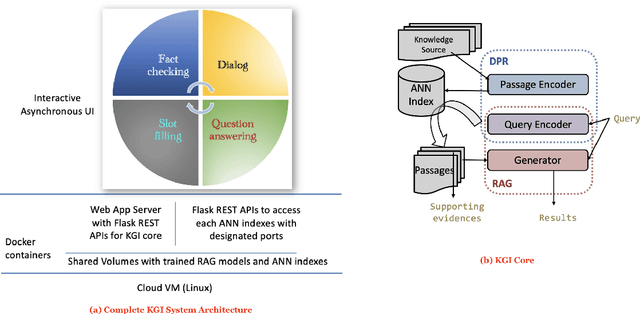
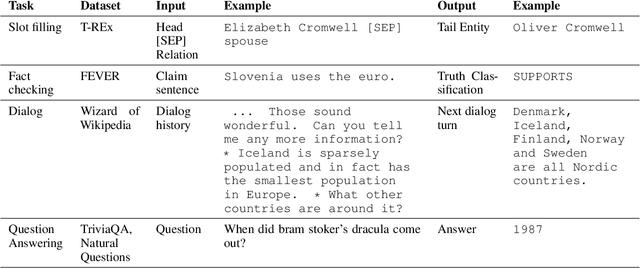
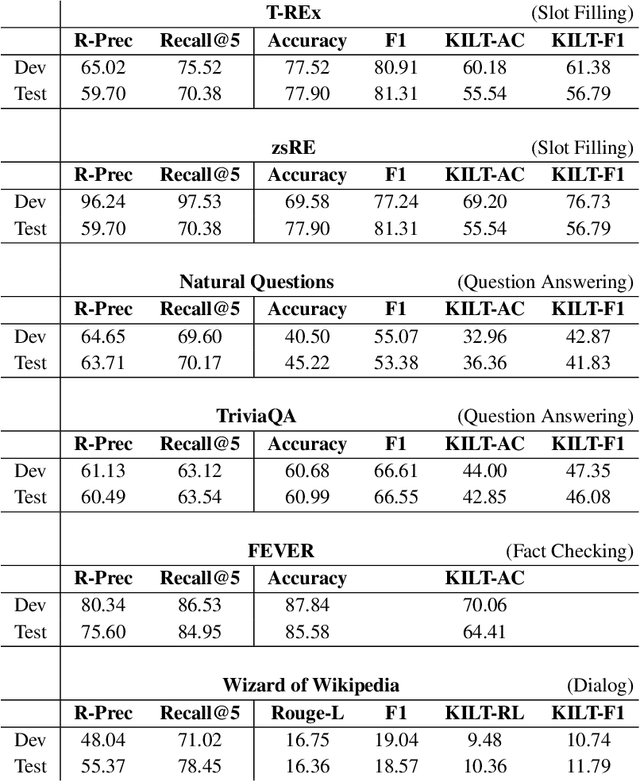
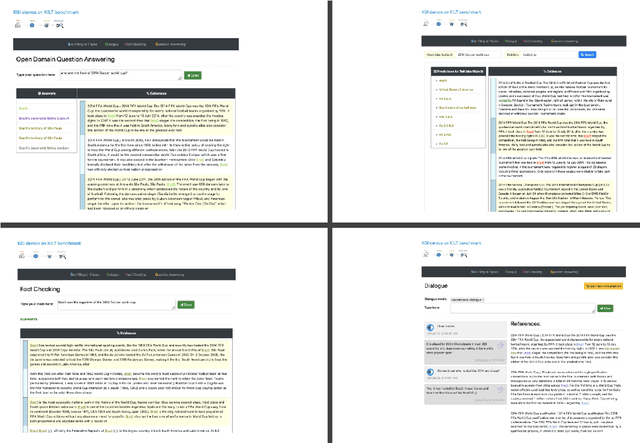
In a recent work, we presented a novel state-of-the-art approach to zero-shot slot filling that extends dense passage retrieval with hard negatives and robust training procedures for retrieval augmented generation models. In this paper, we propose a system based on an enhanced version of this approach where we train task specific models for other knowledge intensive language tasks, such as open domain question answering (QA), dialogue and fact checking. Our system achieves results comparable to the best models in the KILT leaderboards. Moreover, given a user query, we show how the output from these different models can be combined to cross-examine each other. Particularly, we show how accuracy in dialogue can be improved using the QA model. A short video demonstrating the system is available here - \url{https://ibm.box.com/v/kgi-interactive-demo} .
A Generative Model for Relation Extraction and Classification
Feb 26, 2022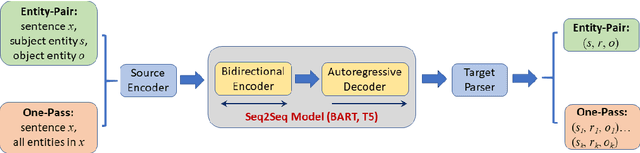
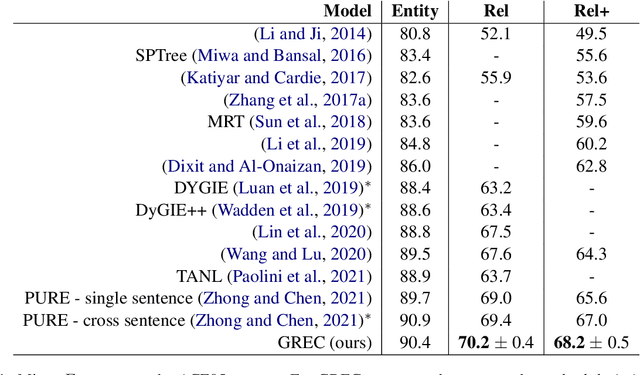
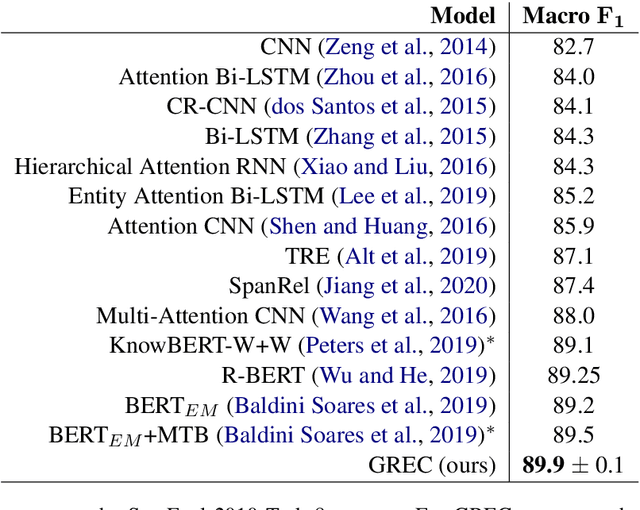
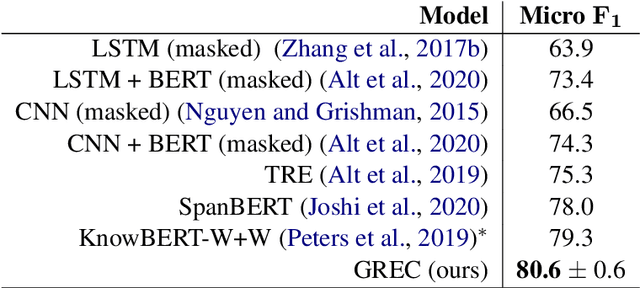
Relation extraction (RE) is an important information extraction task which provides essential information to many NLP applications such as knowledge base population and question answering. In this paper, we present a novel generative model for relation extraction and classification (which we call GREC), where RE is modeled as a sequence-to-sequence generation task. We explore various encoding representations for the source and target sequences, and design effective schemes that enable GREC to achieve state-of-the-art performance on three benchmark RE datasets. In addition, we introduce negative sampling and decoding scaling techniques which provide a flexible tool to tune the precision and recall performance of the model. Our approach can be extended to extract all relation triples from a sentence in one pass. Although the one-pass approach incurs certain performance loss, it is much more computationally efficient.
Applying a Generic Sequence-to-Sequence Model for Simple and Effective Keyphrase Generation
Jan 14, 2022
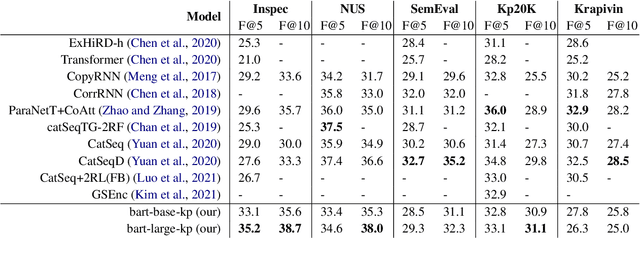
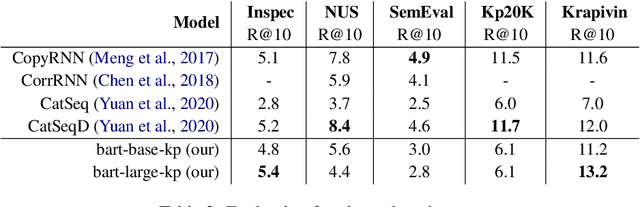
In recent years, a number of keyphrase generation (KPG) approaches were proposed consisting of complex model architectures, dedicated training paradigms and decoding strategies. In this work, we opt for simplicity and show how a commonly used seq2seq language model, BART, can be easily adapted to generate keyphrases from the text in a single batch computation using a simple training procedure. Empirical results on five benchmarks show that our approach is as good as the existing state-of-the-art KPG systems, but using a much simpler and easy to deploy framework.