 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Asymmetric Optimization of Reasoning and Perception in Vision-Language Model Post-Training
May 28, 2026Post-training has greatly improved reasoning in frontier vision-language models, yet its gains for perception remain comparatively limited, creating a bottleneck for end-to-end visual reasoning. To investigate this gap, we introduce a controlled diagnostic framework with two synthetic tasks that disentangle perception from reasoning. Our analysis reveals a consistent perception-reasoning asymmetry: posttraining improves reasoning more substantially than perception, though the underlying mechanism differs by training paradigm. For supervised fine-tuning (SFT), this asymmetry stems from token imbalance in chain-of-thought supervision, where perception occupies fewer tokens and thus receives a weaker training signal. Dynamically reweighting the loss mitigates this imbalance and boosts end-to-end performance by up to 18.2. For reinforcement learning (RL), the asymmetry instead arises from reward coupling: outcome rewards correlate more strongly with reasoning than with perception, weakening the signal for perception learning. Adding a perception-aware reward alleviates the imbalance and improves end-to-end accuracy by up to 6.0; even without groundtruth perception rewards, a reliable surrogate reward provide useful signal, yielding gains of 3.2 points. Together, our results comprehensively diagnose asymmetric optimization and suggest concrete interventions to balance perception and reasoning.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025
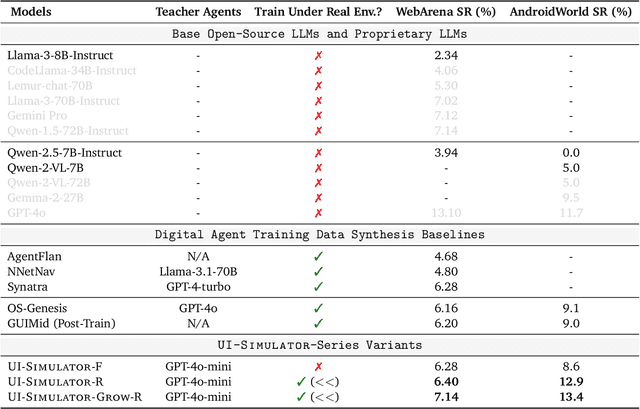

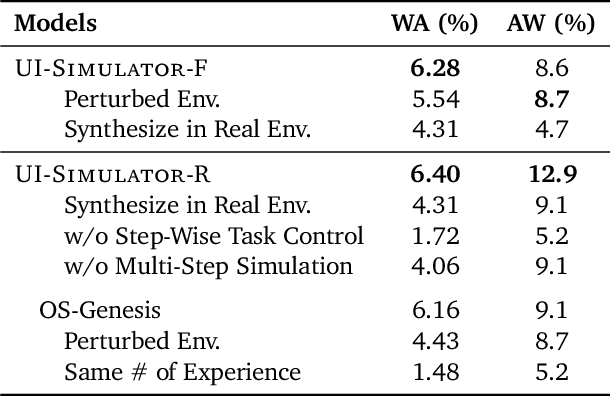
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning
Dec 03, 2024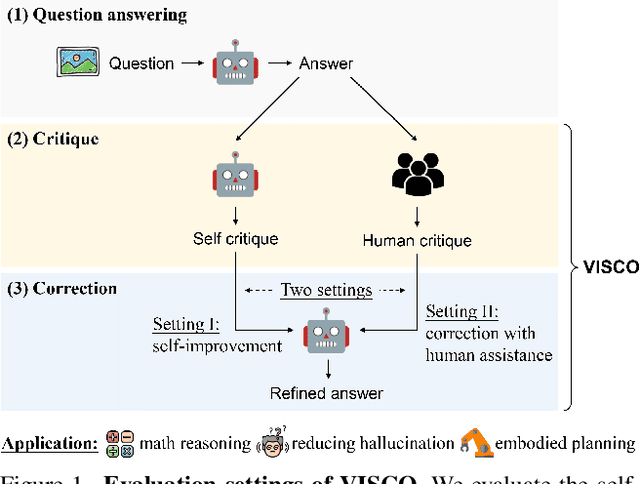
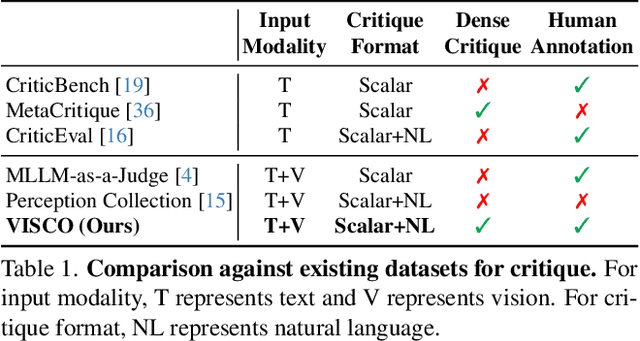
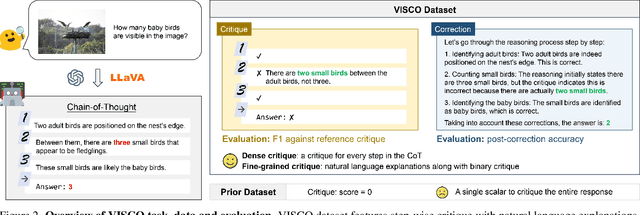
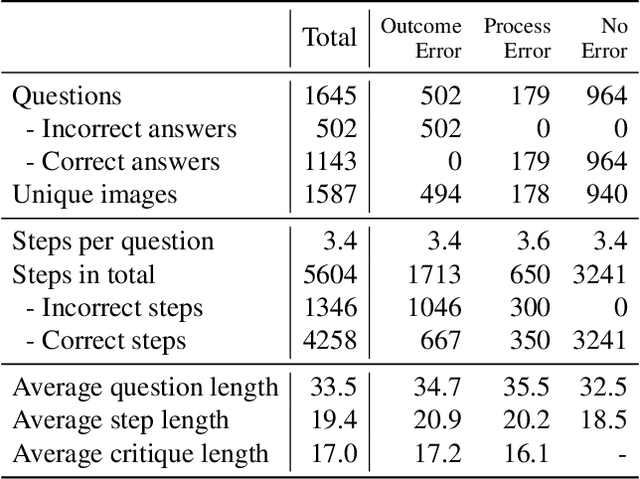
The ability of large vision-language models (LVLMs) to critique and correct their reasoning is an essential building block towards their self-improvement. However, a systematic analysis of such capabilities in LVLMs is still lacking. We propose VISCO, the first benchmark to extensively analyze the fine-grained critique and correction capabilities of LVLMs. Compared to existing work that uses a single scalar value to critique the entire reasoning [4], VISCO features dense and fine-grained critique, requiring LVLMs to evaluate the correctness of each step in the chain-of-thought and provide natural language explanations to support their judgments. Extensive evaluation of 24 LVLMs demonstrates that human-written critiques significantly enhance the performance after correction, showcasing the potential of the self-improvement strategy. However, the model-generated critiques are less helpful and sometimes detrimental to the performance, suggesting that critique is the crucial bottleneck. We identified three common patterns in critique failures: failure to critique visual perception, reluctance to "say no", and exaggerated assumption of error propagation. To address these issues, we propose an effective LookBack strategy that revisits the image to verify each piece of information in the initial reasoning. LookBack significantly improves critique and correction performance by up to 13.5%.
VDebugger: Harnessing Execution Feedback for Debugging Visual Programs
Jun 19, 2024



Visual programs are executable code generated by large language models to address visual reasoning problems. They decompose complex questions into multiple reasoning steps and invoke specialized models for each step to solve the problems. However, these programs are prone to logic errors, with our preliminary evaluation showing that 58% of the total errors are caused by program logic errors. Debugging complex visual programs remains a major bottleneck for visual reasoning. To address this, we introduce VDebugger, a novel critic-refiner framework trained to localize and debug visual programs by tracking execution step by step. VDebugger identifies and corrects program errors leveraging detailed execution feedback, improving interpretability and accuracy. The training data is generated through an automated pipeline that injects errors into correct visual programs using a novel mask-best decoding technique. Evaluations on six datasets demonstrate VDebugger's effectiveness, showing performance improvements of up to 3.2% in downstream task accuracy. Further studies show VDebugger's ability to generalize to unseen tasks, bringing a notable improvement of 2.3% on the unseen COVR task. Code, data and models are made publicly available at https://github.com/shirley-wu/vdebugger/
Reflection-Reinforced Self-Training for Language Agents
Jun 03, 2024



Self-training can potentially improve the performance of language agents without relying on demonstrations from humans or stronger models. The general process involves generating samples from a model, evaluating their quality, and updating the model by training on high-quality samples. However, self-training can face limitations because achieving good performance requires a good amount of high-quality samples, yet relying solely on model sampling for obtaining such samples can be inefficient. In addition, these methods often disregard low-quality samples, failing to leverage them effectively. To address these limitations, we present Reflection-Reinforced Self-Training (Re-ReST), which leverages a reflection model to refine low-quality samples and subsequently uses these improved samples to augment self-training. The reflection model takes both the model output and feedback from an external environment (e.g., unit test results in code generation) as inputs and produces improved samples as outputs. By employing this technique, we effectively enhance the quality of inferior samples, and enrich the self-training dataset with higher-quality samples efficiently. We perform extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. Results demonstrate improvements over self-training baselines across settings. Moreover, ablation studies confirm the reflection model's efficiency in generating quality self-training samples and its compatibility with self-consistency decoding.
DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation
Mar 04, 2024



Data analysis is a crucial analytical process to generate in-depth studies and conclusive insights to comprehensively answer a given user query for tabular data. In this work, we aim to propose new resources and benchmarks to inspire future research on this crucial yet challenging and under-explored task. However, collecting data analysis annotations curated by experts can be prohibitively expensive. We propose to automatically generate high-quality answer annotations leveraging the code-generation capabilities of LLMs with a multi-turn prompting technique. We construct the DACO dataset, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k query-answer pairs that can serve as weak supervision for model training, and (3) a concentrated but high-quality test set with human refined annotations that serves as our main evaluation benchmark. We train a 6B supervised fine-tuning (SFT) model on DACO dataset, and find that the SFT model learns reasonable data analysis capabilities. To further align the models with human preference, we use reinforcement learning to encourage generating analysis perceived by human as helpful, and design a set of dense rewards to propagate the sparse human preference reward to intermediate code generation steps. Our DACO-RL algorithm is evaluated by human annotators to produce more helpful answers than SFT model in 57.72% cases, validating the effectiveness of our proposed algorithm. Data and code are released at https://github.com/shirley-wu/daco
Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
Feb 27, 2024


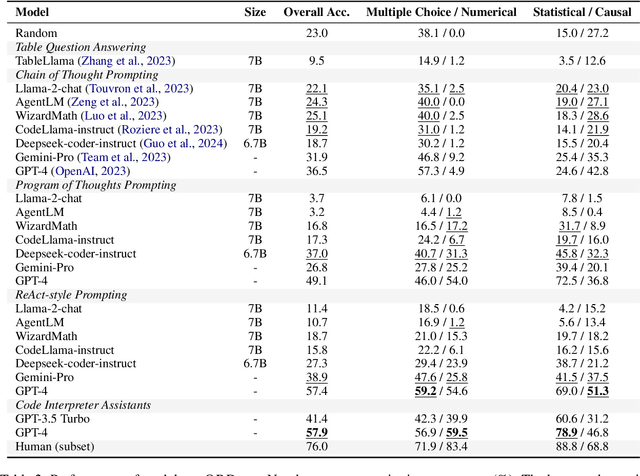
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has a large room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
OpenPI-C: A Better Benchmark and Stronger Baseline for Open-Vocabulary State Tracking
Jun 20, 2023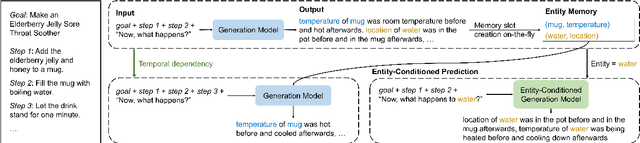
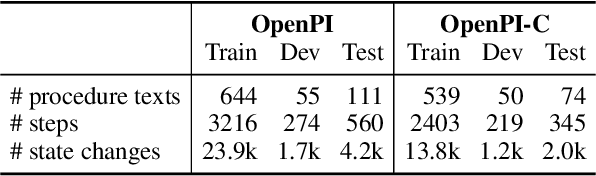

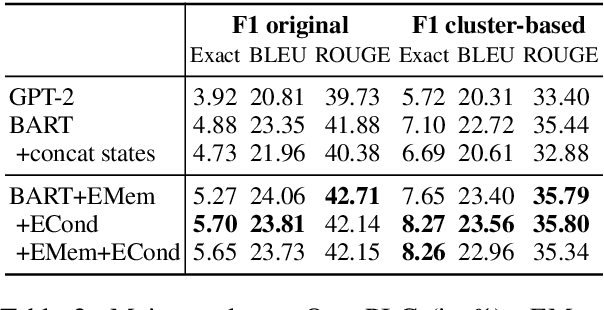
Open-vocabulary state tracking is a more practical version of state tracking that aims to track state changes of entities throughout a process without restricting the state space and entity space. OpenPI is to date the only dataset annotated for open-vocabulary state tracking. However, we identify issues with the dataset quality and evaluation metric. For the dataset, we categorize 3 types of problems on the procedure level, step level and state change level respectively, and build a clean dataset OpenPI-C using multiple rounds of human judgment. For the evaluation metric, we propose a cluster-based metric to fix the original metric's preference for repetition. Model-wise, we enhance the seq2seq generation baseline by reinstating two key properties for state tracking: temporal dependency and entity awareness. The state of the world after an action is inherently dependent on the previous state. We model this dependency through a dynamic memory bank and allow the model to attend to the memory slots during decoding. On the other hand, the state of the world is naturally a union of the states of involved entities. Since the entities are unknown in the open-vocabulary setting, we propose a two-stage model that refines the state change prediction conditioned on entities predicted from the first stage. Empirical results show the effectiveness of our proposed model especially on the cluster-based metric. The code and data are released at https://github.com/shirley-wu/openpi-c
Retrieval-Based Transformer for Table Augmentation
Jun 20, 2023Data preparation, also called data wrangling, is considered one of the most expensive and time-consuming steps when performing analytics or building machine learning models. Preparing data typically involves collecting and merging data from complex heterogeneous, and often large-scale data sources, such as data lakes. In this paper, we introduce a novel approach toward automatic data wrangling in an attempt to alleviate the effort of end-users, e.g. data analysts, in structuring dynamic views from data lakes in the form of tabular data. We aim to address table augmentation tasks, including row/column population and data imputation. Given a corpus of tables, we propose a retrieval augmented self-trained transformer model. Our self-learning strategy consists in randomly ablating tables from the corpus and training the retrieval-based model to reconstruct the original values or headers given the partial tables as input. We adopt this strategy to first train the dense neural retrieval model encoding table-parts to vectors, and then the end-to-end model trained to perform table augmentation tasks. We test on EntiTables, the standard benchmark for table augmentation, as well as introduce a new benchmark to advance further research: WebTables. Our model consistently and substantially outperforms both supervised statistical methods and the current state-of-the-art transformer-based models.
Text-to-Table: A New Way of Information Extraction
Sep 06, 2021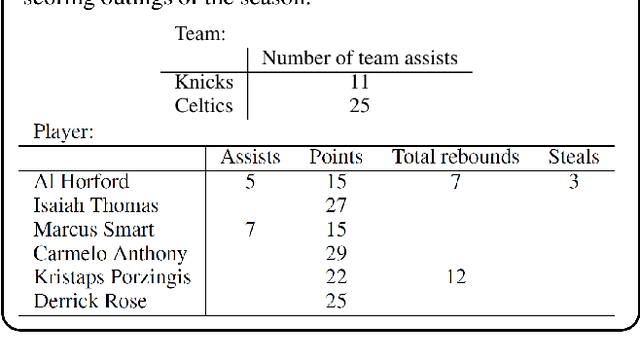

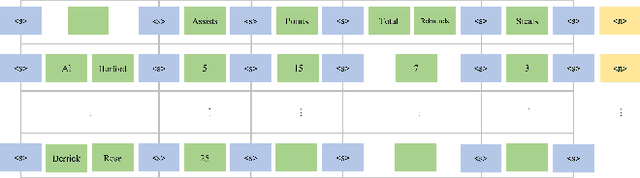
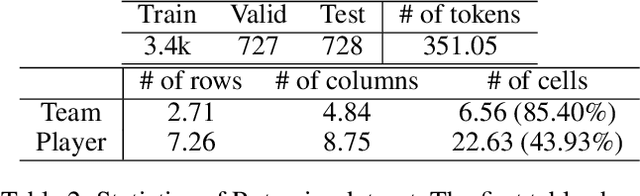
We study a new problem setting of information extraction (IE), referred to as text-to-table, which can be viewed as an inverse problem of the well-studied table-to-text. In text-to-table, given a text, one creates a table or several tables expressing the main content of the text, while the model is learned from text-table pair data. The problem setting differs from those of the existing methods for IE. First, the extraction can be carried out from long texts to large tables with complex structures. Second, the extraction is entirely data-driven, and there is no need to explicitly define the schemas. As far as we know, there has been no previous work that studies the problem. In this work, we formalize text-to-table as a sequence-to-sequence (seq2seq) problem. We first employ a seq2seq model fine-tuned from a pre-trained language model to perform the task. We also develop a new method within the seq2seq approach, exploiting two additional techniques in table generation: table constraint and table relation embeddings. We make use of four existing table-to-text datasets in our experiments on text-to-table. Experimental results show that the vanilla seq2seq model can outperform the baseline methods of using relation extraction and named entity extraction. The results also show that our method can further boost the performances of the vanilla seq2seq model. We further discuss the main challenges of the proposed task. The code and data will be made publicly available.