 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Few-Shot Learning Help LLM Performance in Code Synthesis?
Dec 03, 2024



Large language models (LLMs) have made significant strides at code generation through improved model design, training, and chain-of-thought. However, prompt-level optimizations remain an important yet under-explored aspect of LLMs for coding. This work focuses on the few-shot examples present in most code generation prompts, offering a systematic study on whether few-shot examples improve LLM's coding capabilities, which few-shot examples have the largest impact, and how to select impactful examples. Our work offers 2 approaches for selecting few-shot examples, a model-free method, CODEEXEMPLAR-FREE, and a model-based method, CODEEXEMPLAR-BASED. The 2 methods offer a trade-off between improved performance and reliance on training data and interpretability. Both methods significantly improve CodeLlama's coding ability across the popular HumanEval+ coding benchmark. In summary, our work provides valuable insights into how to pick few-shot examples in code generation prompts to improve LLM code generation capabilities.
Inverse designing metamaterials with programmable nonlinear functional responses in graph space
Aug 12, 2024



Material responses to static and dynamic stimuli, represented as nonlinear curves, are design targets for engineering functionalities like structural support, impact protection, and acoustic and photonic bandgaps. Three-dimensional metamaterials offer significant tunability due to their internal structure, yet existing methods struggle to capture their complex behavior-to-structure relationships. We present GraphMetaMat, a graph-based framework capable of designing three-dimensional metamaterials with programmable responses and arbitrary manufacturing constraints. Integrating graph networks, physics biases, reinforcement learning, and tree search, GraphMetaMat can target stress-strain curves spanning four orders of magnitude and complex behaviors, as well as viscoelastic transmission responses with varying attenuation gaps. GraphMetaMat can create cushioning materials for protective equipment and vibration-damping panels for electric vehicles, outperforming commercial materials, and enabling the automatic design of materials with on-demand functionalities.
Mixture of In-Context Prompters for Tabular PFNs
May 25, 2024Recent benchmarks found In-Context Learning (ICL) outperforms both deep learning and tree-based algorithms on small tabular datasets. However, on larger datasets, ICL for tabular learning cannot run without severely compromising performance, due to its quadratic space and time complexity w.r.t. dataset size. We propose MIXTUREPFN, which both extends nearest-neighbor sampling to the state-of-the-art ICL for tabular learning model and uses bootstrapping to finetune said model on the inference-time dataset. MIXTUREPFN is the Condorcet winner across 36 diverse tabular datasets against 19 strong deep learning and tree-based baselines, achieving the highest mean rank among Top-10 aforementioned algorithms with statistical significance.
A Survey on Self-Supervised Learning for Non-Sequential Tabular Data
Feb 05, 2024


Self-supervised learning (SSL) has been incorporated into many state-of-the-art models in various domains, where SSL defines pretext tasks based on unlabeled datasets to learn contextualized and robust representations. Recently, SSL has been a new trend in exploring the representation learning capability in the realm of tabular data, which is more challenging due to not having explicit relations for learning descriptive representations. This survey aims to systematically review and summarize the recent progress and challenges of SSL for non-sequential tabular data (SSL4NS-TD). We first present a formal definition of NS-TD and clarify its correlation to related studies. Then, these approaches are categorized into three groups -- predictive learning, contrastive learning, and hybrid learning, with their motivations and strengths of representative methods within each direction. On top of this, application issues of SSL4NS-TD are presented, including automatic data engineering, cross-table transferability, and domain knowledge integration. In addition, we elaborate on existing benchmarks and datasets for NS-TD applications to discuss the performance of existing tabular models. Finally, we discuss the challenges of SSL4NS-TD and provide potential directions for future research. We expect our work to be useful in terms of encouraging more research on lowering the barrier to entry SSL for the tabular domain and improving the foundations for implicit tabular data.
Unveiling Invariances via Neural Network Pruning
Sep 15, 2023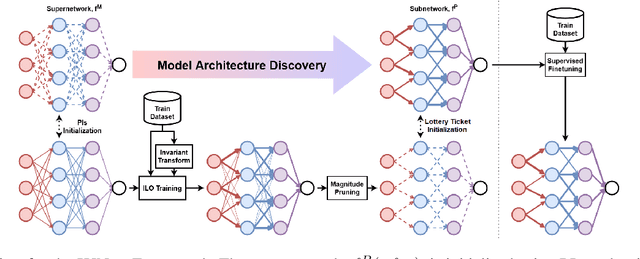
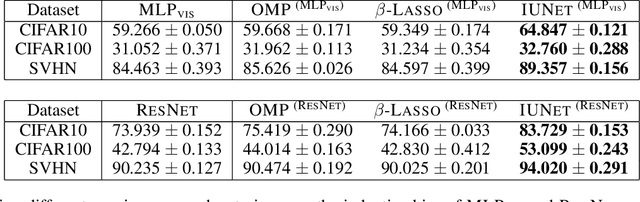

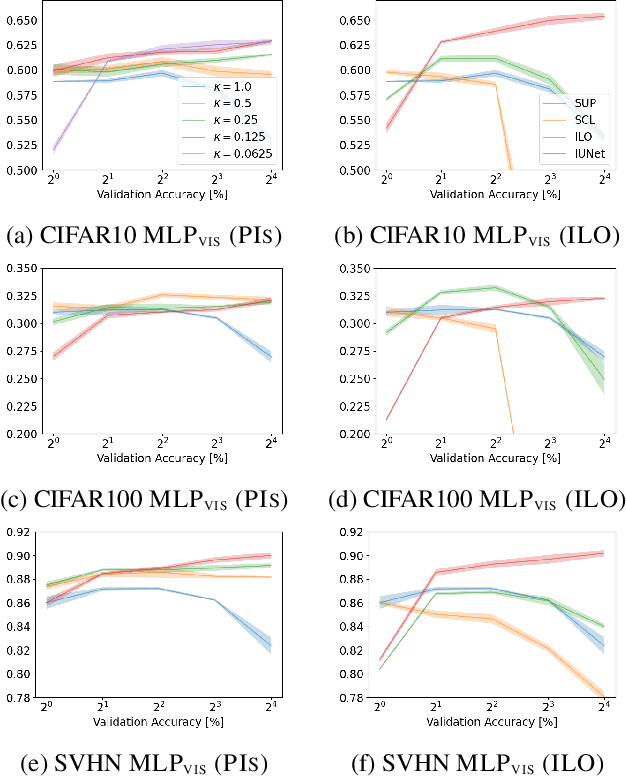
Invariance describes transformations that do not alter data's underlying semantics. Neural networks that preserve natural invariance capture good inductive biases and achieve superior performance. Hence, modern networks are handcrafted to handle well-known invariances (ex. translations). We propose a framework to learn novel network architectures that capture data-dependent invariances via pruning. Our learned architectures consistently outperform dense neural networks on both vision and tabular datasets in both efficiency and effectiveness. We demonstrate our framework on multiple deep learning models across 3 vision and 40 tabular datasets.
Introducing Semantics into Speech Encoders
Nov 15, 2022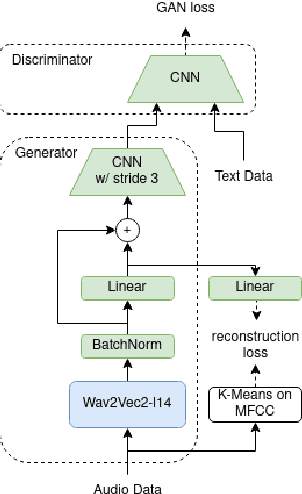
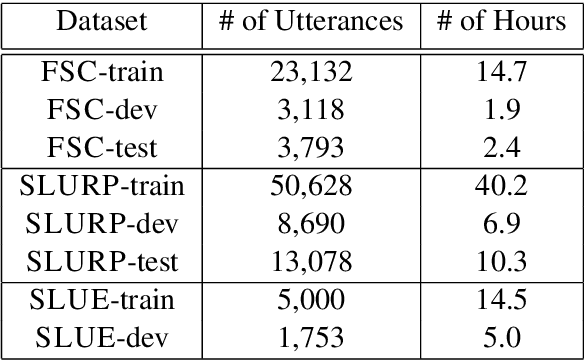
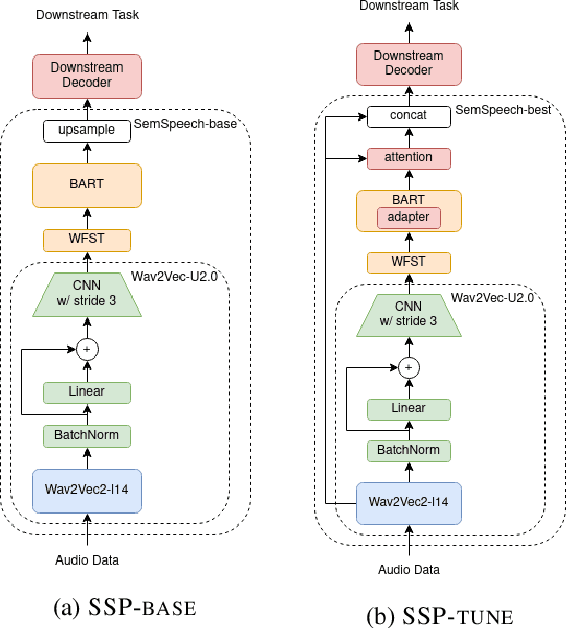
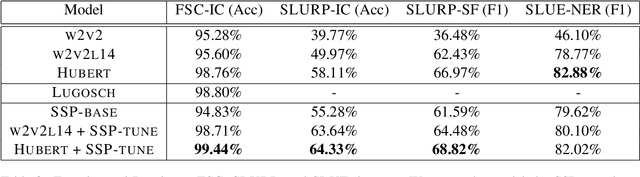
Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
Subgraph Matching via Query-Conditioned Subgraph Matching Neural Networks and Bi-Level Tree Search
Jul 21, 2022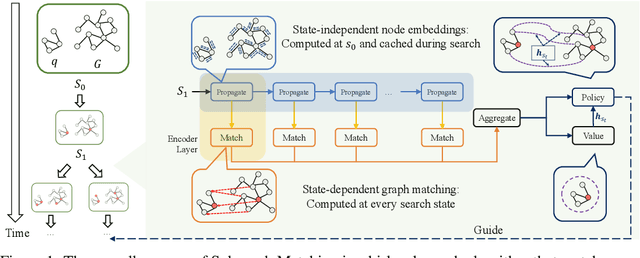
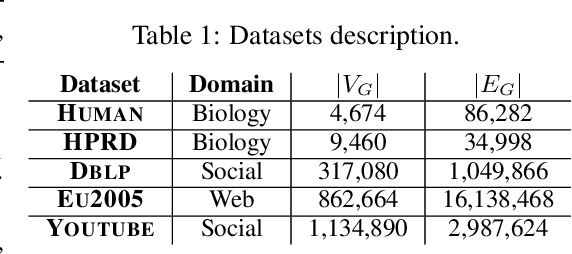
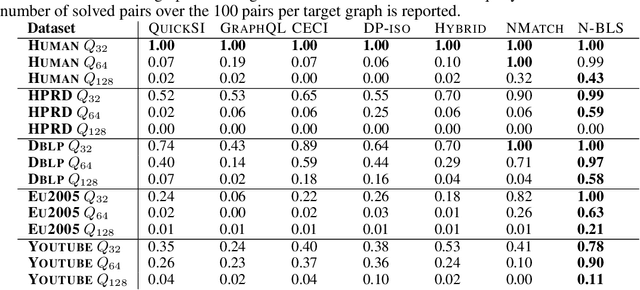
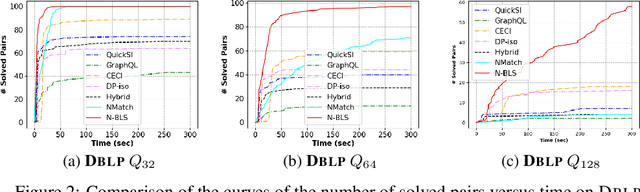
Recent advances have shown the success of using reinforcement learning and search to solve NP-hard graph-related tasks, such as Traveling Salesman Optimization, Graph Edit Distance computation, etc. However, it remains unclear how one can efficiently and accurately detect the occurrences of a small query graph in a large target graph, which is a core operation in graph database search, biomedical analysis, social group finding, etc. This task is called Subgraph Matching which essentially performs subgraph isomorphism check between a query graph and a large target graph. One promising approach to this classical problem is the "learning-to-search" paradigm, where a reinforcement learning (RL) agent is designed with a learned policy to guide a search algorithm to quickly find the solution without any solved instances for supervision. However, for the specific task of Subgraph Matching, though the query graph is usually small given by the user as input, the target graph is often orders-of-magnitude larger. It poses challenges to the neural network design and can lead to solution and reward sparsity. In this paper, we propose N-BLS with two innovations to tackle the challenges: (1) A novel encoder-decoder neural network architecture to dynamically compute the matching information between the query and the target graphs at each search state; (2) A Monte Carlo Tree Search enhanced bi-level search framework for training the policy and value networks. Experiments on five large real-world target graphs show that N-BLS can significantly improve the subgraph matching performance.
FogROS 2: An Adaptive and Extensible Platform for Cloud and Fog Robotics Using ROS 2
May 19, 2022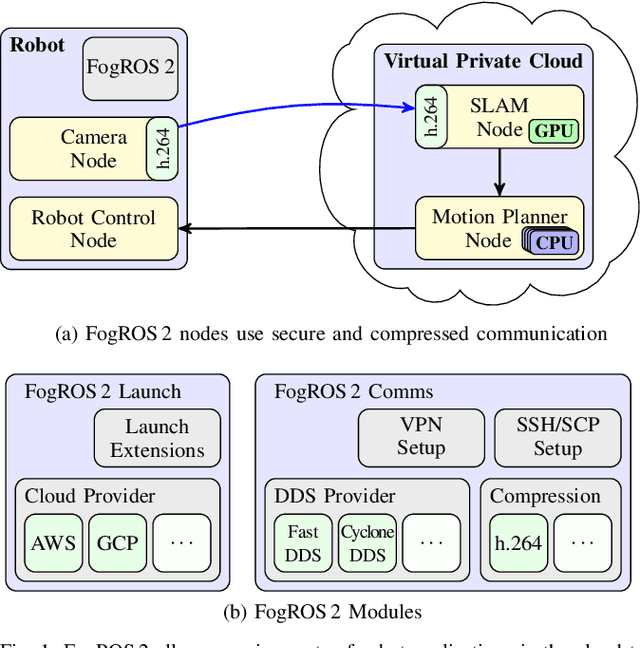
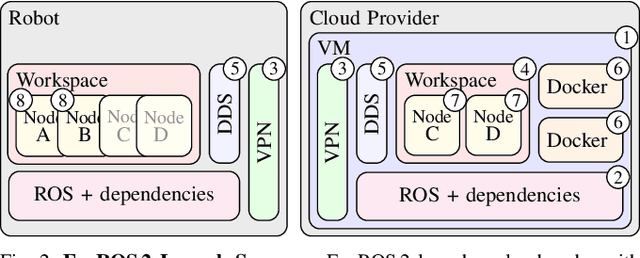
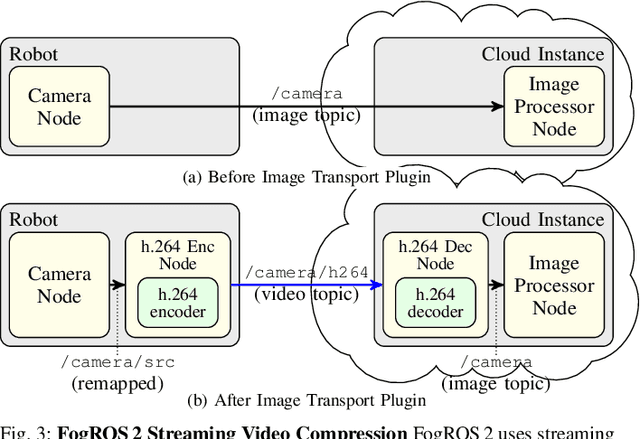
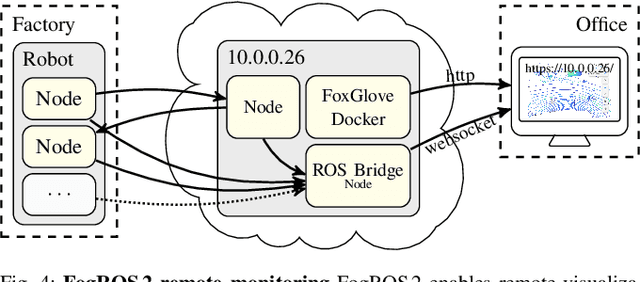
Mobility, power, and price points often dictate that robots do not have sufficient computing power on board to run modern robot algorithms at desired rates. Cloud computing providers such as AWS, GCP, and Azure offer immense computing power on demand, but tapping into that power from a robot is non-trivial. In this paper, we present FogROS 2, an easy-to-use, open-source platform to facilitate cloud and fog robotics compatible with the emerging ROS 2 standard, extending the open-source Robot Operating System (ROS). FogROS 2 provisions a cloud computer, deploys and launches ROS 2 nodes to the cloud computer, sets up secure networking between the robot and cloud, and starts the application running. FogROS 2 is completely redesigned and distinct from its predecessor to support ROS 2 applications, transparent video compression and communication, improved performance and security, support for multiple cloud-computing providers, and remote monitoring and visualization. We demonstrate in example applications that the performance gained by using cloud computers can overcome the network latency to significantly speed up robot performance. In examples, FogROS 2 reduces SLAM latency by 50%, reduces grasp planning time from 14s to 1.2s, and speeds up motion planning 28x. When compared to alternatives, FogROS 2 reduces network utilization by up to 3.8x. FogROS 2, source, examples, and documentation is available at https://github.com/BerkeleyAutomation/FogROS2 .
Ray Based Distributed Autonomous Vehicle Research Platform
Jan 18, 2022My project tackles the question of whether Ray can be used to quickly train autonomous vehicles using a simulator (Carla), and whether a platform robust enough for further research purposes can be built around it. Ray is an open-source framework that enables distributed machine learning applications. Distributed computing is a technique which parallelizes computational tasks, such as training a model, among many machines. Ray abstracts away the complex coordination of these machines, making it rapidly scalable. Carla is a vehicle simulator that generates data used to train a model. The bulk of the project was writing the training logic that Ray would use to train my distributed model. Imitation learning is the best fit for autonomous vehicles. Imitation learning is an alternative to reinforcement learning and it works by trying to learn the optimal policy by imitating an expert (usually a human) given a set of demonstrations. A key deliverable for the project was showcasing my trained agent in a few benchmark tests, such as navigating a complex turn through traffic. Beyond that, the broader ambition was to develop a research platform where others could quickly train and run experiments on huge amounts of Carla vehicle data. Thus, my end product is not a single model, but a large-scale, open-source research platform (RayCarla) for autonomous vehicle researchers to utilize.
Fast Detection of Maximum Common Subgraph via Deep Q-Learning
Feb 20, 2020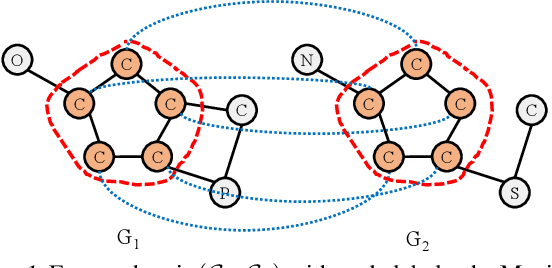

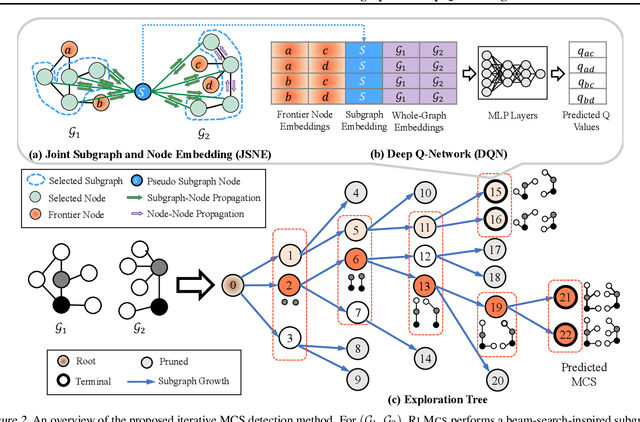
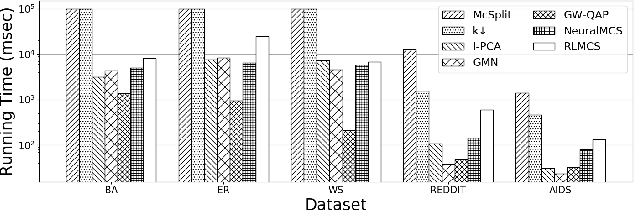
Detecting the Maximum Common Subgraph (MCS) between two input graphs is fundamental for applications in biomedical analysis, malware detection, cloud computing, etc. This is especially important in the task of drug design, where the successful extraction of common substructures in compounds can reduce the number of experiments needed to be conducted by humans. However, MCS computation is NP-hard, and state-of-the-art exact MCS solvers do not have worst-case time complexity guarantee and cannot handle large graphs in practice. Designing learning based models to find the MCS between two graphs in an approximate yet accurate way while utilizing as few labeled MCS instances as possible remains to be a challenging task. Here we propose RLMCS, a Graph Neural Network based model for MCS detection through reinforcement learning. Our model uses an exploration tree to extract subgraphs in two graphs one node pair at a time, and is trained to optimize subgraph extraction rewards via Deep Q-Networks. A novel graph embedding method is proposed to generate state representations for nodes and extracted subgraphs jointly at each step. Experiments on real graph datasets demonstrate that our model performs favorably to exact MCS solvers and supervised neural graph matching network models in terms of accuracy and efficiency.