 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
CARPAS: Towards Content-Aware Refinement of Provided Aspects for Summarization in Large Language Models
Oct 08, 2025Aspect-based summarization has attracted significant attention for its ability to generate more fine-grained and user-aligned summaries. While most existing approaches assume a set of predefined aspects as input, real-world scenarios often present challenges where these given aspects may be incomplete, irrelevant, or entirely missing from the document. Users frequently expect systems to adaptively refine or filter the provided aspects based on the actual content. In this paper, we initiate this novel task setting, termed Content-Aware Refinement of Provided Aspects for Summarization (CARPAS), with the aim of dynamically adjusting the provided aspects based on the document context before summarizing. We construct three new datasets to facilitate our pilot experiments, and by using LLMs with four representative prompting strategies in this task, we find that LLMs tend to predict an overly comprehensive set of aspects, which often results in excessively long and misaligned summaries. Building on this observation, we propose a preliminary subtask to predict the number of relevant aspects, and demonstrate that the predicted number can serve as effective guidance for the LLMs, reducing the inference difficulty, and enabling them to focus on the most pertinent aspects. Our extensive experiments show that the proposed approach significantly improves performance across all datasets. Moreover, our deeper analyses uncover LLMs' compliance when the requested number of aspects differs from their own estimations, establishing a crucial insight for the deployment of LLMs in similar real-world applications.
PromptTSS: A Prompting-Based Approach for Interactive Multi-Granularity Time Series Segmentation
Jun 12, 2025Multivariate time series data, collected across various fields such as manufacturing and wearable technology, exhibit states at multiple levels of granularity, from coarse-grained system behaviors to fine-grained, detailed events. Effectively segmenting and integrating states across these different granularities is crucial for tasks like predictive maintenance and performance optimization. However, existing time series segmentation methods face two key challenges: (1) the inability to handle multiple levels of granularity within a unified model, and (2) limited adaptability to new, evolving patterns in dynamic environments. To address these challenges, we propose PromptTSS, a novel framework for time series segmentation with multi-granularity states. PromptTSS uses a unified model with a prompting mechanism that leverages label and boundary information to guide segmentation, capturing both coarse- and fine-grained patterns while adapting dynamically to unseen patterns. Experiments show PromptTSS improves accuracy by 24.49% in multi-granularity segmentation, 17.88% in single-granularity segmentation, and up to 599.24% in transfer learning, demonstrating its adaptability to hierarchical states and evolving time series dynamics.
Time-IMM: A Dataset and Benchmark for Irregular Multimodal Multivariate Time Series
Jun 12, 2025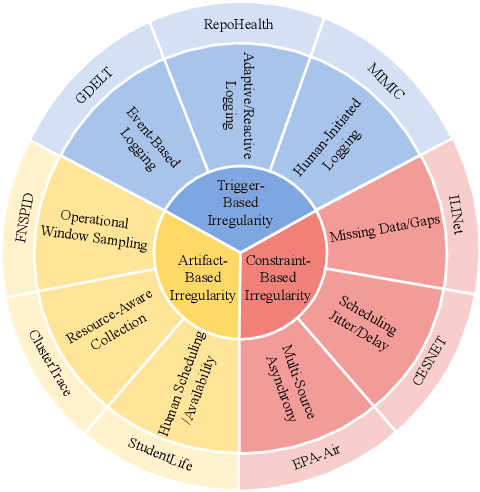
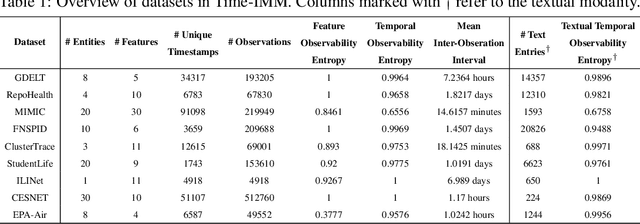
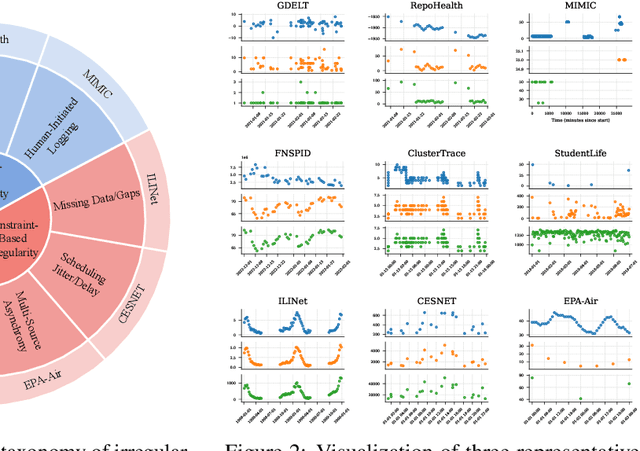
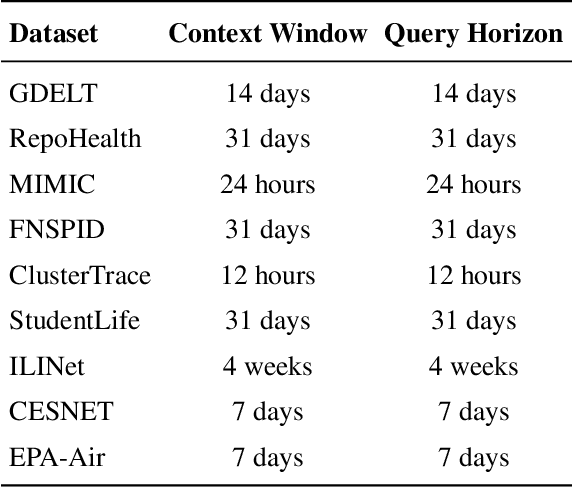
Time series data in real-world applications such as healthcare, climate modeling, and finance are often irregular, multimodal, and messy, with varying sampling rates, asynchronous modalities, and pervasive missingness. However, existing benchmarks typically assume clean, regularly sampled, unimodal data, creating a significant gap between research and real-world deployment. We introduce Time-IMM, a dataset specifically designed to capture cause-driven irregularity in multimodal multivariate time series. Time-IMM represents nine distinct types of time series irregularity, categorized into trigger-based, constraint-based, and artifact-based mechanisms. Complementing the dataset, we introduce IMM-TSF, a benchmark library for forecasting on irregular multimodal time series, enabling asynchronous integration and realistic evaluation. IMM-TSF includes specialized fusion modules, including a timestamp-to-text fusion module and a multimodality fusion module, which support both recency-aware averaging and attention-based integration strategies. Empirical results demonstrate that explicitly modeling multimodality on irregular time series data leads to substantial gains in forecasting performance. Time-IMM and IMM-TSF provide a foundation for advancing time series analysis under real-world conditions. The dataset is publicly available at https://www.kaggle.com/datasets/blacksnail789521/time-imm/data, and the benchmark library can be accessed at https://anonymous.4open.science/r/IMMTSF_NeurIPS2025.
Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalanced Regression
Jun 08, 2025
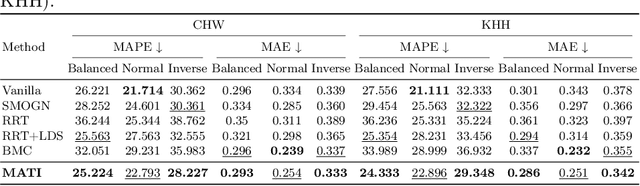
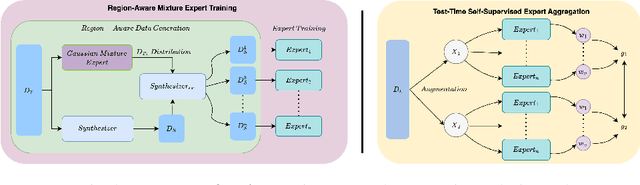
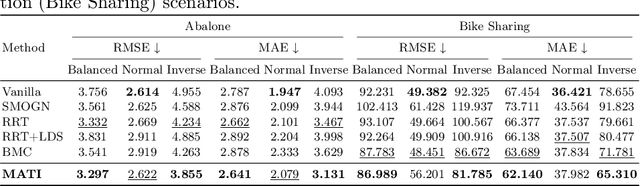
Tabular data serve as a fundamental and ubiquitous representation of structured information in numerous real-world applications, e.g., finance and urban planning. In the realm of tabular imbalanced applications, data imbalance has been investigated in classification tasks with insufficient instances in certain labels, causing the model's ineffective generalizability. However, the imbalance issue of tabular regression tasks is underexplored, and yet is critical due to unclear boundaries for continuous labels and simplifying assumptions in existing imbalance regression work, which often rely on known and balanced test distributions. Such assumptions may not hold in practice and can lead to performance degradation. To address these issues, we propose MATI: Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalance Regression, featuring two key innovations: (i) the Region-Aware Mixture Expert, which adopts a Gaussian Mixture Model to capture the underlying related regions. The statistical information of each Gaussian component is then used to synthesize and train region-specific experts to capture the unique characteristics of their respective regions. (ii) Test-Time Self-Supervised Expert Aggregation, which dynamically adjusts region expert weights based on test data features to reinforce expert adaptation across varying test distributions. We evaluated MATI on four real-world tabular imbalance regression datasets, including house pricing, bike sharing, and age prediction. To reflect realistic deployment scenarios, we adopted three types of test distributions: a balanced distribution with uniform target frequencies, a normal distribution that follows the training data, and an inverse distribution that emphasizes rare target regions. On average across these three test distributions, MATI achieved a 7.1% improvement in MAE compared to existing methods.
Template-Based Financial Report Generation in Agentic and Decomposed Information Retrieval
Apr 19, 2025


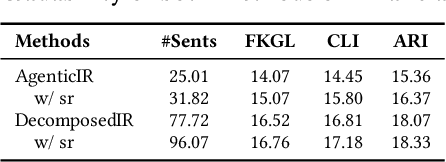
Tailoring structured financial reports from companies' earnings releases is crucial for understanding financial performance and has been widely adopted in real-world analytics. However, existing summarization methods often generate broad, high-level summaries, which may lack the precision and detail required for financial reports that typically focus on specific, structured sections. While Large Language Models (LLMs) hold promise, generating reports adhering to predefined multi-section templates remains challenging. This paper investigates two LLM-based approaches popular in industry for generating templated financial reports: an agentic information retrieval (IR) framework and a decomposed IR approach, namely AgenticIR and DecomposedIR. The AgenticIR utilizes collaborative agents prompted with the full template. In contrast, the DecomposedIR approach applies a prompt chaining workflow to break down the template and reframe each section as a query answered by the LLM using the earnings release. To quantitatively assess the generated reports, we evaluated both methods in two scenarios: one using a financial dataset without direct human references, and another with a weather-domain dataset featuring expert-written reports. Experimental results show that while AgenticIR may excel in orchestrating tasks and generating concise reports through agent collaboration, DecomposedIR statistically significantly outperforms AgenticIR approach in providing broader and more detailed coverage in both scenarios, offering reflection on the utilization of the agentic framework in real-world applications.
EXPRESS: An LLM-Generated Explainable Property Valuation System with Neighbor Imputation
Mar 16, 2025

The demand for property valuation has attracted significant attention from sellers, buyers, and customers applying for loans. Reviews of existing approaches have revealed shortcomings in terms of not being able to handle missing value situations, as well as lacking interpretability, which means they cannot be used in real-world applications. To address these challenges, we propose an LLM-Generated EXplainable PRopErty valuation SyStem with neighbor imputation called EXPRESS, which provides the customizable missing value imputation technique, and addresses the opaqueness of prediction by providing the feature-wise explanation generated by LLM. The dynamic nearest neighbor search finds similar properties depending on different application scenarios by property configuration set by users (e.g., house age as criteria for the house in rural areas, and locations for buildings in urban areas). Motivated by the human appraisal procedure, we generate feature-wise explanations to provide users with a more intuitive understanding of the prediction results.
Team NYCU at Defactify4: Robust Detection and Source Identification of AI-Generated Images Using CNN and CLIP-Based Models
Mar 13, 2025

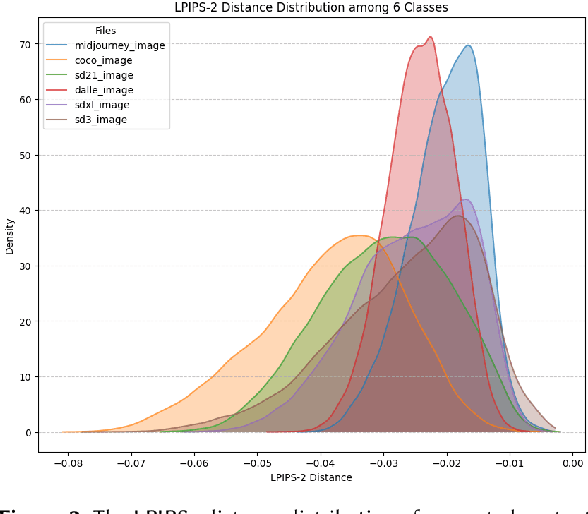

With the rapid advancement of generative AI, AI-generated images have become increasingly realistic, raising concerns about creativity, misinformation, and content authenticity. Detecting such images and identifying their source models has become a critical challenge in ensuring the integrity of digital media. This paper tackles the detection of AI-generated images and identifying their source models using CNN and CLIP-ViT classifiers. For the CNN-based classifier, we leverage EfficientNet-B0 as the backbone and feed with RGB channels, frequency features, and reconstruction errors, while for CLIP-ViT, we adopt a pretrained CLIP image encoder to extract image features and SVM to perform classification. Evaluated on the Defactify 4 dataset, our methods demonstrate strong performance in both tasks, with CLIP-ViT showing superior robustness to image perturbations. Compared to baselines like AEROBLADE and OCC-CLIP, our approach achieves competitive results. Notably, our method ranked Top-3 overall in the Defactify 4 competition, highlighting its effectiveness and generalizability. All of our implementations can be found in https://github.com/uuugaga/Defactify_4
Imitation Learning of Correlated Policies in Stackelberg Games
Mar 11, 2025



Stackelberg games, widely applied in domains like economics and security, involve asymmetric interactions where a leader's strategy drives follower responses. Accurately modeling these dynamics allows domain experts to optimize strategies in interactive scenarios, such as turn-based sports like badminton. In multi-agent systems, agent behaviors are interdependent, and traditional Multi-Agent Imitation Learning (MAIL) methods often fail to capture these complex interactions. Correlated policies, which account for opponents' strategies, are essential for accurately modeling such dynamics. However, even methods designed for learning correlated policies, like CoDAIL, struggle in Stackelberg games due to their asymmetric decision-making, where leaders and followers cannot simultaneously account for each other's actions, often leading to non-correlated policies. Furthermore, existing MAIL methods that match occupancy measures or use adversarial techniques like GAIL or Inverse RL face scalability challenges, particularly in high-dimensional environments, and suffer from unstable training. To address these challenges, we propose a correlated policy occupancy measure specifically designed for Stackelberg games and introduce the Latent Stackelberg Differential Network (LSDN) to match it. LSDN models two-agent interactions as shared latent state trajectories and uses multi-output Geometric Brownian Motion (MO-GBM) to effectively capture joint policies. By leveraging MO-GBM, LSDN disentangles environmental influences from agent-driven transitions in latent space, enabling the simultaneous learning of interdependent policies. This design eliminates the need for adversarial training and simplifies the learning process. Extensive experiments on Iterative Matrix Games and multi-agent particle environments demonstrate that LSDN can better reproduce complex interaction dynamics than existing MAIL methods.
Plan2Align: Predictive Planning Based Test-Time Preference Alignment in Paragraph-Level Machine Translation
Feb 28, 2025Machine Translation (MT) has been predominantly designed for sentence-level translation using transformer-based architectures. While next-token prediction based Large Language Models (LLMs) demonstrate strong capabilities in long-text translation, non-extensive language models often suffer from omissions and semantic inconsistencies when processing paragraphs. Existing preference alignment methods improve sentence-level translation but fail to ensure coherence over extended contexts due to the myopic nature of next-token generation. We introduce Plan2Align, a test-time alignment framework that treats translation as a predictive planning problem, adapting Model Predictive Control to iteratively refine translation outputs. Experiments on WMT24 Discourse-Level Literary Translation show that Plan2Align significantly improves paragraph-level translation, achieving performance surpassing or on par with the existing training-time and test-time alignment methods on LLaMA-3.1 8B.