 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPAR: Modeling Irregular Target Functions in Tabular Regression via Arithmetic-Aware Pre-Training and Adaptive-Regularized Fine-Tuning
Paper and Code
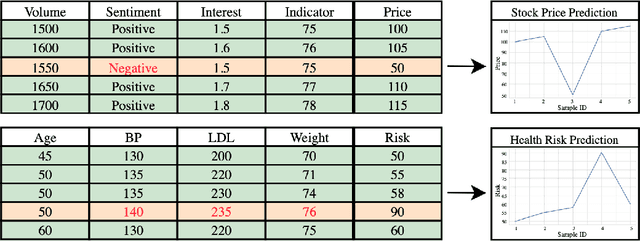
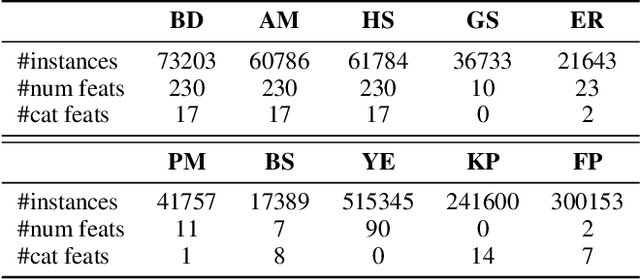
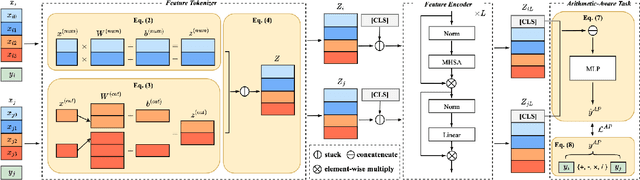
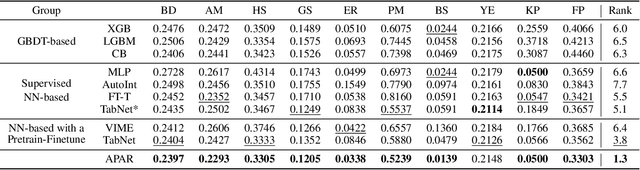
Tabular data are fundamental in common machine learning applications, ranging from finance to genomics and healthcare. This paper focuses on tabular regression tasks, a field where deep learning (DL) methods are not consistently superior to machine learning (ML) models due to the challenges posed by irregular target functions inherent in tabular data, causing sensitive label changes with minor variations from features. To address these issues, we propose a novel Arithmetic-Aware Pre-training and Adaptive-Regularized Fine-tuning framework (APAR), which enables the model to fit irregular target function in tabular data while reducing the negative impact of overfitting. In the pre-training phase, APAR introduces an arithmetic-aware pretext objective to capture intricate sample-wise relationships from the perspective of continuous labels. In the fine-tuning phase, a consistency-based adaptive regularization technique is proposed to self-learn appropriate data augmentation. Extensive experiments across 10 datasets demonstrated that APAR outperforms existing GBDT-, supervised NN-, and pretrain-finetune NN-based methods in RMSE (+9.43% $\sim$ 20.37%), and empirically validated the effects of pre-training tasks, including the study of arithmetic operations. Our code and data are publicly available at https://github.com/johnnyhwu/APAR.