 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRTUE: Visual-Interactive Text-Image Universal Embedder
Oct 01, 2025Multimodal representation learning models have demonstrated successful operation across complex tasks, and the integration of vision-language models (VLMs) has further enabled embedding models with instruction-following capabilities. However, existing embedding models lack visual-interactive capabilities to specify regions of interest from users (e.g., point, bounding box, mask), which have been explored in generative models to broaden their human-interactive applicability. Equipping embedding models with visual interactions not only would unlock new applications with localized grounding of user intent, which remains unexplored, but also enable the models to learn entity-level information within images to complement their global representations for conventional embedding tasks. In this paper, we propose a novel Visual-InteRactive Text-Image Universal Embedder (VIRTUE) that extends the capabilities of the segmentation model and the vision-language model to the realm of representation learning. In VIRTUE, the segmentation model can process visual prompts that pinpoint specific regions within an image, thereby enabling the embedder to handle complex and ambiguous scenarios more precisely. To evaluate the visual-interaction ability of VIRTUE, we introduce a large-scale Segmentation-and-Scene Caption Retrieval (SCaR) benchmark comprising 1M samples that aims to retrieve the text caption by jointly considering the entity with a specific object and image scene. VIRTUE consistently achieves a state-of-the-art performance with significant improvements across 36 universal MMEB (3.1%-8.5%) and five visual-interactive SCaR (15.2%-20.3%) tasks.
Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalanced Regression
Jun 08, 2025
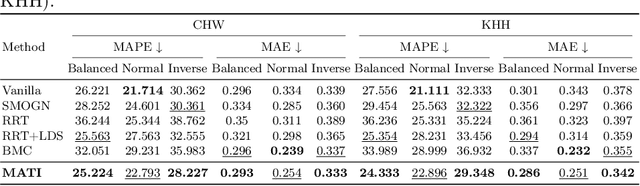
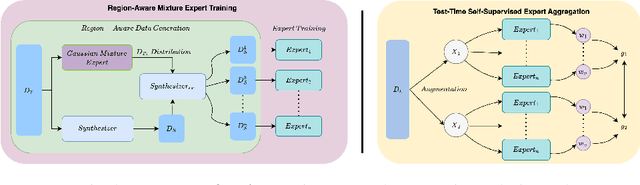
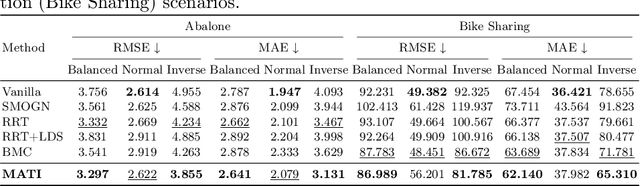
Tabular data serve as a fundamental and ubiquitous representation of structured information in numerous real-world applications, e.g., finance and urban planning. In the realm of tabular imbalanced applications, data imbalance has been investigated in classification tasks with insufficient instances in certain labels, causing the model's ineffective generalizability. However, the imbalance issue of tabular regression tasks is underexplored, and yet is critical due to unclear boundaries for continuous labels and simplifying assumptions in existing imbalance regression work, which often rely on known and balanced test distributions. Such assumptions may not hold in practice and can lead to performance degradation. To address these issues, we propose MATI: Mixture Experts with Test-Time Self-Supervised Aggregation for Tabular Imbalance Regression, featuring two key innovations: (i) the Region-Aware Mixture Expert, which adopts a Gaussian Mixture Model to capture the underlying related regions. The statistical information of each Gaussian component is then used to synthesize and train region-specific experts to capture the unique characteristics of their respective regions. (ii) Test-Time Self-Supervised Expert Aggregation, which dynamically adjusts region expert weights based on test data features to reinforce expert adaptation across varying test distributions. We evaluated MATI on four real-world tabular imbalance regression datasets, including house pricing, bike sharing, and age prediction. To reflect realistic deployment scenarios, we adopted three types of test distributions: a balanced distribution with uniform target frequencies, a normal distribution that follows the training data, and an inverse distribution that emphasizes rare target regions. On average across these three test distributions, MATI achieved a 7.1% improvement in MAE compared to existing methods.
Seeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Mar 04, 2025Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of earlier modalities (e.g., images) to incorporate information from later modalities (e.g., text). To address this problem, we propose AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code is publicly available at https://github.com/sony/aki, and we will release our AKI-4B model to encourage further advancements in MLLMs across various directions.
APAR: Modeling Irregular Target Functions in Tabular Regression via Arithmetic-Aware Pre-Training and Adaptive-Regularized Fine-Tuning
Dec 14, 2024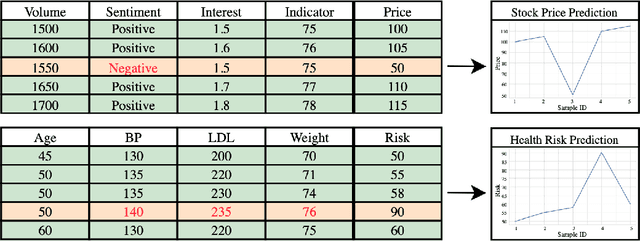
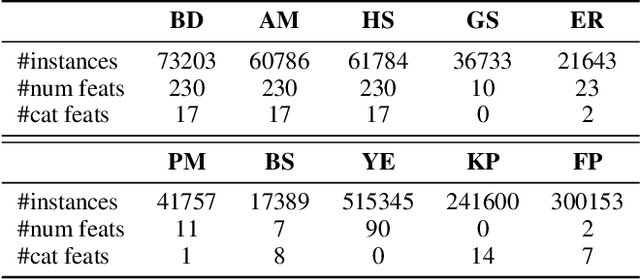
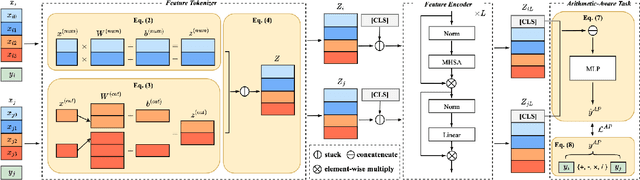
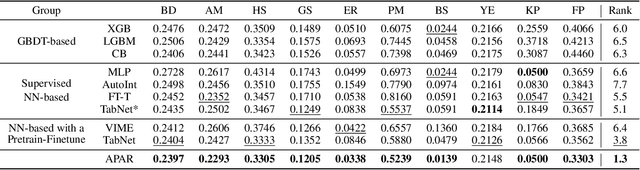
Tabular data are fundamental in common machine learning applications, ranging from finance to genomics and healthcare. This paper focuses on tabular regression tasks, a field where deep learning (DL) methods are not consistently superior to machine learning (ML) models due to the challenges posed by irregular target functions inherent in tabular data, causing sensitive label changes with minor variations from features. To address these issues, we propose a novel Arithmetic-Aware Pre-training and Adaptive-Regularized Fine-tuning framework (APAR), which enables the model to fit irregular target function in tabular data while reducing the negative impact of overfitting. In the pre-training phase, APAR introduces an arithmetic-aware pretext objective to capture intricate sample-wise relationships from the perspective of continuous labels. In the fine-tuning phase, a consistency-based adaptive regularization technique is proposed to self-learn appropriate data augmentation. Extensive experiments across 10 datasets demonstrated that APAR outperforms existing GBDT-, supervised NN-, and pretrain-finetune NN-based methods in RMSE (+9.43% $\sim$ 20.37%), and empirically validated the effects of pre-training tasks, including the study of arithmetic operations. Our code and data are publicly available at https://github.com/johnnyhwu/APAR.
Self-Supervised Learning of Disentangled Representations for Multivariate Time-Series
Oct 16, 2024


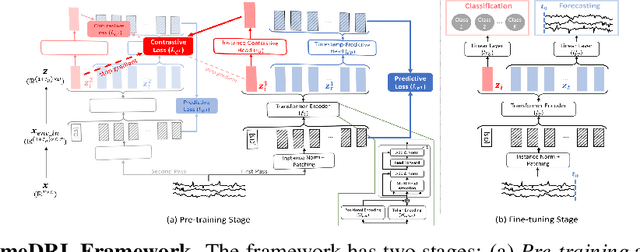
Multivariate time-series data in fields like healthcare and industry are informative but challenging due to high dimensionality and lack of labels. Recent self-supervised learning methods excel in learning rich representations without labels but struggle with disentangled embeddings and inductive bias issues like transformation-invariance. To address these challenges, we introduce TimeDRL, a framework for multivariate time-series representation learning with dual-level disentangled embeddings. TimeDRL features: (i) disentangled timestamp-level and instance-level embeddings using a [CLS] token strategy; (ii) timestamp-predictive and instance-contrastive tasks for representation learning; and (iii) avoidance of augmentation methods to eliminate inductive biases. Experiments on forecasting and classification datasets show TimeDRL outperforms existing methods, with further validation in semi-supervised settings with limited labeled data.
Offline Imitation of Badminton Player Behavior via Experiential Contexts and Brownian Motion
Mar 19, 2024In the dynamic and rapid tactic involvements of turn-based sports, badminton stands out as an intrinsic paradigm that requires alter-dependent decision-making of players. While the advancement of learning from offline expert data in sequential decision-making has been witnessed in various domains, how to rally-wise imitate the behaviors of human players from offline badminton matches has remained underexplored. Replicating opponents' behavior benefits players by allowing them to undergo strategic development with direction before matches. However, directly applying existing methods suffers from the inherent hierarchy of the match and the compounding effect due to the turn-based nature of players alternatively taking actions. In this paper, we propose RallyNet, a novel hierarchical offline imitation learning model for badminton player behaviors: (i) RallyNet captures players' decision dependencies by modeling decision-making processes as a contextual Markov decision process. (ii) RallyNet leverages the experience to generate context as the agent's intent in the rally. (iii) To generate more realistic behavior, RallyNet leverages Geometric Brownian Motion (GBM) to model the interactions between players by introducing a valuable inductive bias for learning player behaviors. In this manner, RallyNet links player intents with interaction models with GBM, providing an understanding of interactions for sports analytics. We extensively validate RallyNet with the largest available real-world badminton dataset consisting of men's and women's singles, demonstrating its ability to imitate player behaviors. Results reveal RallyNet's superiority over offline imitation learning methods and state-of-the-art turn-based approaches, outperforming them by at least 16% in mean rule-based agent normalization score. Furthermore, we discuss various practical use cases to highlight RallyNet's applicability.
A Survey on Self-Supervised Learning for Non-Sequential Tabular Data
Feb 05, 2024


Self-supervised learning (SSL) has been incorporated into many state-of-the-art models in various domains, where SSL defines pretext tasks based on unlabeled datasets to learn contextualized and robust representations. Recently, SSL has been a new trend in exploring the representation learning capability in the realm of tabular data, which is more challenging due to not having explicit relations for learning descriptive representations. This survey aims to systematically review and summarize the recent progress and challenges of SSL for non-sequential tabular data (SSL4NS-TD). We first present a formal definition of NS-TD and clarify its correlation to related studies. Then, these approaches are categorized into three groups -- predictive learning, contrastive learning, and hybrid learning, with their motivations and strengths of representative methods within each direction. On top of this, application issues of SSL4NS-TD are presented, including automatic data engineering, cross-table transferability, and domain knowledge integration. In addition, we elaborate on existing benchmarks and datasets for NS-TD applications to discuss the performance of existing tabular models. Finally, we discuss the challenges of SSL4NS-TD and provide potential directions for future research. We expect our work to be useful in terms of encouraging more research on lowering the barrier to entry SSL for the tabular domain and improving the foundations for implicit tabular data.
Root Cause Analysis In Microservice Using Neural Granger Causal Discovery
Feb 02, 2024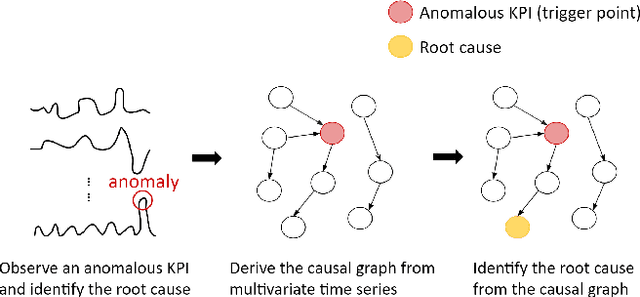
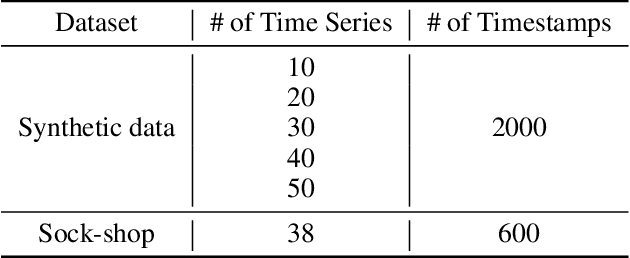
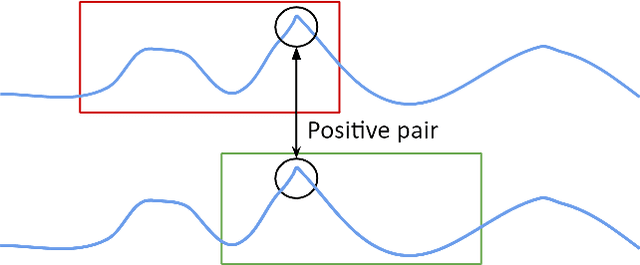
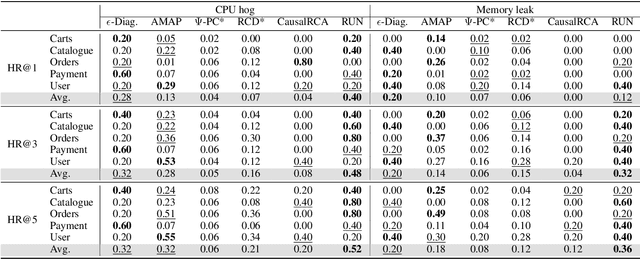
In recent years, microservices have gained widespread adoption in IT operations due to their scalability, maintenance, and flexibility. However, it becomes challenging for site reliability engineers (SREs) to pinpoint the root cause due to the complex relationships in microservices when facing system malfunctions. Previous research employed structured learning methods (e.g., PC-algorithm) to establish causal relationships and derive root causes from causal graphs. Nevertheless, they ignored the temporal order of time series data and failed to leverage the rich information inherent in the temporal relationships. For instance, in cases where there is a sudden spike in CPU utilization, it can lead to an increase in latency for other microservices. However, in this scenario, the anomaly in CPU utilization occurs before the latency increase, rather than simultaneously. As a result, the PC-algorithm fails to capture such characteristics. To address these challenges, we propose RUN, a novel approach for root cause analysis using neural Granger causal discovery with contrastive learning. RUN enhances the backbone encoder by integrating contextual information from time series, and leverages a time series forecasting model to conduct neural Granger causal discovery. In addition, RUN incorporates Pagerank with a personalization vector to efficiently recommend the top-k root causes. Extensive experiments conducted on the synthetic and real-world microservice-based datasets demonstrate that RUN noticeably outperforms the state-of-the-art root cause analysis methods. Moreover, we provide an analysis scenario for the sock-shop case to showcase the practicality and efficacy of RUN in microservice-based applications. Our code is publicly available at https://github.com/zmlin1998/RUN.
Style-News: Incorporating Stylized News Generation and Adversarial Verification for Neural Fake News Detection
Jan 27, 2024With the improvements in generative models, the issues of producing hallucinations in various domains (e.g., law, writing) have been brought to people's attention due to concerns about misinformation. In this paper, we focus on neural fake news, which refers to content generated by neural networks aiming to mimic the style of real news to deceive people. To prevent harmful disinformation spreading fallaciously from malicious social media (e.g., content farms), we propose a novel verification framework, Style-News, using publisher metadata to imply a publisher's template with the corresponding text types, political stance, and credibility. Based on threat modeling aspects, a style-aware neural news generator is introduced as an adversary for generating news content conditioning for a specific publisher, and style and source discriminators are trained to defend against this attack by identifying which publisher the style corresponds with, and discriminating whether the source of the given news is human-written or machine-generated. To evaluate the quality of the generated content, we integrate various dimensional metrics (language fluency, content preservation, and style adherence) and demonstrate that Style-News significantly outperforms the previous approaches by a margin of 0.35 for fluency, 15.24 for content, and 0.38 for style at most. Moreover, our discriminative model outperforms state-of-the-art baselines in terms of publisher prediction (up to 4.64%) and neural fake news detection (+6.94% $\sim$ 31.72%).
ShuttleSHAP: A Turn-Based Feature Attribution Approach for Analyzing Forecasting Models in Badminton
Dec 18, 2023Agent forecasting systems have been explored to investigate agent patterns and improve decision-making in various domains, e.g., pedestrian predictions and marketing bidding. Badminton represents a fascinating example of a multifaceted turn-based sport, requiring both sophisticated tactic developments and alternate-dependent decision-making. Recent deep learning approaches for player tactic forecasting in badminton show promising performance partially attributed to effective reasoning about rally-player interactions. However, a critical obstacle lies in the unclear functionality of which features are learned for simulating players' behaviors by black-box models, where existing explainers are not equipped with turn-based and multi-output attributions. To bridge this gap, we propose a turn-based feature attribution approach, ShuttleSHAP, for analyzing forecasting models in badminton based on variants of Shapley values. ShuttleSHAP is a model-agnostic explainer that aims to quantify contribution by not only temporal aspects but also player aspects in terms of multifaceted cues. Incorporating the proposed analysis tool into the state-of-the-art turn-based forecasting model on the benchmark dataset reveals that it is, in fact, insignificant to reason about past strokes, while conventional sequential models have greater impacts. Instead, players' styles influence the models for the future simulation of a rally. On top of that, we investigate and discuss the causal analysis of these findings and demonstrate the practicability with local analysis.