 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Mar 04, 2025Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of earlier modalities (e.g., images) to incorporate information from later modalities (e.g., text). To address this problem, we propose AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code is publicly available at https://github.com/sony/aki, and we will release our AKI-4B model to encourage further advancements in MLLMs across various directions.
Data Cleansing for Deep Neural Networks with Storage-efficient Approximation of Influence Functions
Mar 22, 2021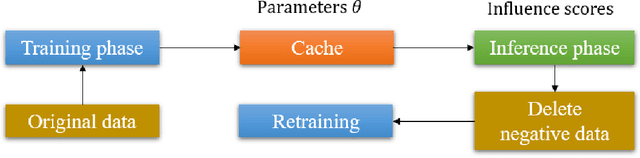
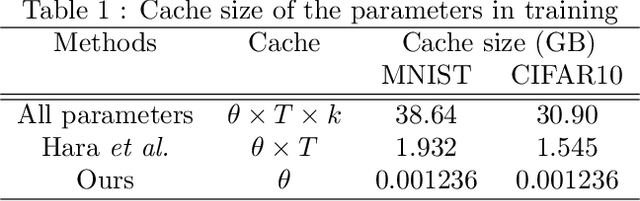
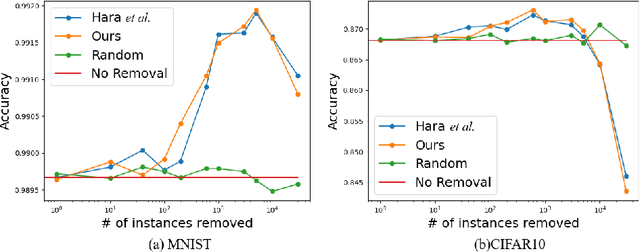

Identifying the influence of training data for data cleansing can improve the accuracy of deep learning. An approach with stochastic gradient descent (SGD) called SGD-influence to calculate the influence scores was proposed, but, the calculation costs are expensive. It is necessary to temporally store the parameters of the model during training phase for inference phase to calculate influence sores. In close connection with the previous method, we propose a method to reduce cache files to store the parameters in training phase for calculating inference score. We only adopt the final parameters in last epoch for influence functions calculation. In our experiments on classification, the cache size of training using MNIST dataset with our approach is 1.236 MB. On the other hand, the previous method used cache size of 1.932 GB in last epoch. It means that cache size has been reduced to 1/1,563. We also observed the accuracy improvement by data cleansing with removal of negatively influential data using our approach as well as the previous method. Moreover, our simple and general proposed method to calculate influence scores is available on our auto ML tool without programing, Neural Network Console. The source code is also available.
Neural Network Libraries: A Deep Learning Framework Designed from Engineers' Perspectives
Feb 12, 2021

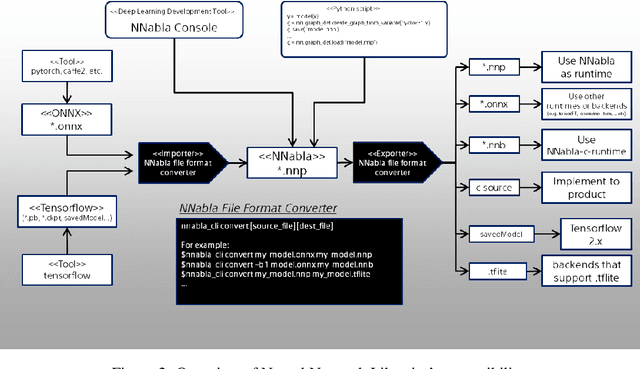
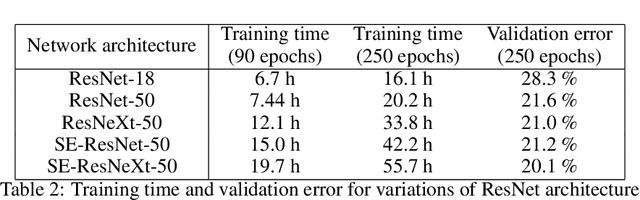
While there exist a plethora of deep learning tools and frameworks, the fast-growing complexity of the field brings new demands and challenges, such as more flexible network design, speedy computation on distributed setting, and compatibility between different tools. In this paper, we introduce Neural Network Libraries (https://nnabla.org), a deep learning framework designed from engineer's perspective, with emphasis on usability and compatibility as its core design principles. We elaborate on each of our design principles and its merits, and validate our attempts via experiments.