 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Libraries: A Deep Learning Framework Designed from Engineers' Perspectives
Feb 12, 2021

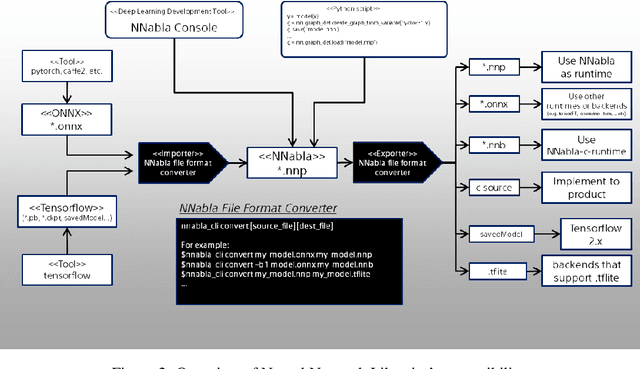
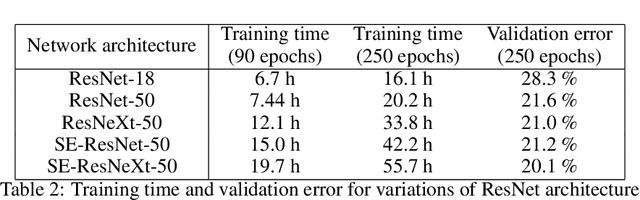
While there exist a plethora of deep learning tools and frameworks, the fast-growing complexity of the field brings new demands and challenges, such as more flexible network design, speedy computation on distributed setting, and compatibility between different tools. In this paper, we introduce Neural Network Libraries (https://nnabla.org), a deep learning framework designed from engineer's perspective, with emphasis on usability and compatibility as its core design principles. We elaborate on each of our design principles and its merits, and validate our attempts via experiments.
Iteratively Training Look-Up Tables for Network Quantization
Nov 12, 2019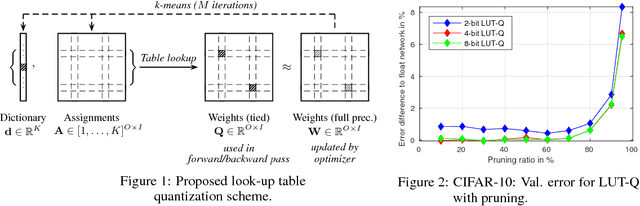

Operating deep neural networks (DNNs) on devices with limited resources requires the reduction of their memory as well as computational footprint. Popular reduction methods are network quantization or pruning, which either reduce the word length of the network parameters or remove weights from the network if they are not needed. In this article we discuss a general framework for network reduction which we call `Look-Up Table Quantization` (LUT-Q). For each layer, we learn a value dictionary and an assignment matrix to represent the network weights. We propose a special solver which combines gradient descent and a one-step k-means update to learn both the value dictionaries and assignment matrices iteratively. This method is very flexible: by constraining the value dictionary, many different reduction problems such as non-uniform network quantization, training of multiplierless networks, network pruning or simultaneous quantization and pruning can be implemented without changing the solver. This flexibility of the LUT-Q method allows us to use the same method to train networks for different hardware capabilities.
Differentiable Quantization of Deep Neural Networks
May 27, 2019


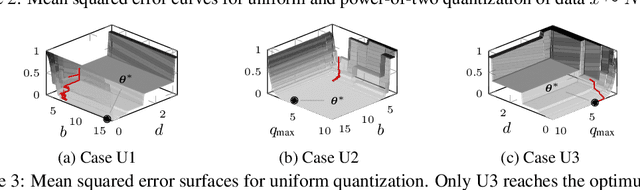
We propose differentiable quantization (DQ) for efficient deep neural network (DNN) inference where gradient descent is used to learn the quantizer's step size, dynamic range and bitwidth. Training with differentiable quantizers brings two main benefits: first, DQ does not introduce hyperparameters; second, we can learn for each layer a different step size, dynamic range and bitwidth. Our experiments show that DNNs with heterogeneous and learned bitwidth yield better performance than DNNs with a homogeneous one. Further, we show that there is one natural DQ parametrization especially well suited for training. We confirm our findings with experiments on CIFAR-10 and ImageNet and we obtain quantized DNNs with learned quantization parameters achieving state-of-the-art performance.