 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Quantization of Deep Neural Networks
Paper and Code



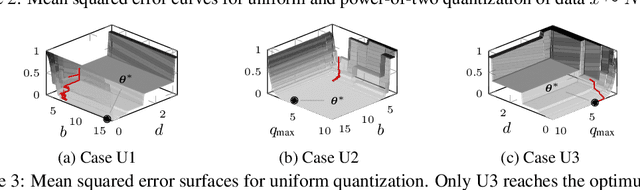
We propose differentiable quantization (DQ) for efficient deep neural network (DNN) inference where gradient descent is used to learn the quantizer's step size, dynamic range and bitwidth. Training with differentiable quantizers brings two main benefits: first, DQ does not introduce hyperparameters; second, we can learn for each layer a different step size, dynamic range and bitwidth. Our experiments show that DNNs with heterogeneous and learned bitwidth yield better performance than DNNs with a homogeneous one. Further, we show that there is one natural DQ parametrization especially well suited for training. We confirm our findings with experiments on CIFAR-10 and ImageNet and we obtain quantized DNNs with learned quantization parameters achieving state-of-the-art performance.