 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sampling for Predictor-Based Neural Architecture Search
Nov 24, 2020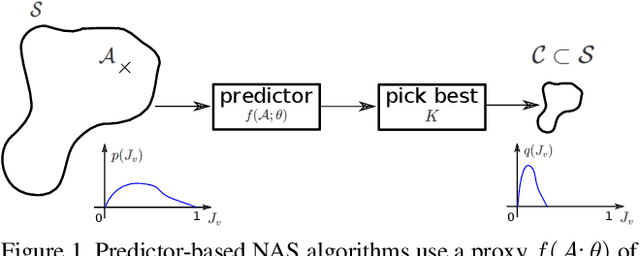

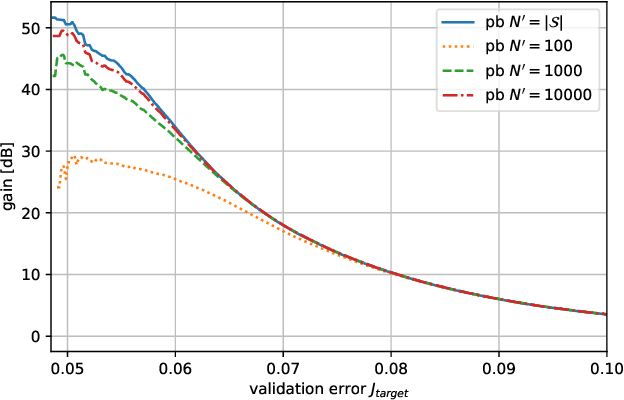
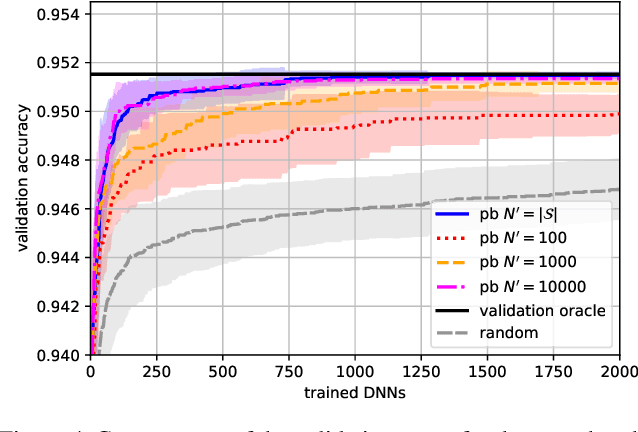
Recently, predictor-based algorithms emerged as a promising approach for neural architecture search (NAS). For NAS, we typically have to calculate the validation accuracy of a large number of Deep Neural Networks (DNNs), what is computationally complex. Predictor-based NAS algorithms address this problem. They train a proxy model that can infer the validation accuracy of DNNs directly from their network structure. During optimization, the proxy can be used to narrow down the number of architectures for which the true validation accuracy must be computed, what makes predictor-based algorithms sample efficient. Usually, we compute the proxy for all DNNs in the network search space and pick those that maximize the proxy as candidates for optimization. However, that is intractable in practice, because the search spaces are often very large and contain billions of network architectures. The contributions of this paper are threefold: 1) We define a sample efficiency gain to compare different predictor-based NAS algorithms. 2) We conduct experiments on the NASBench-101 dataset and show that the sample efficiency of predictor-based algorithms decreases dramatically if the proxy is only computed for a subset of the search space. 3) We show that if we choose the subset of the search space on which the proxy is evaluated in a smart way, the sample efficiency of the original predictor-based algorithm that has access to the full search space can be regained. This is an important step to make predictor-based NAS algorithms useful, in practice.
Iteratively Training Look-Up Tables for Network Quantization
Nov 12, 2019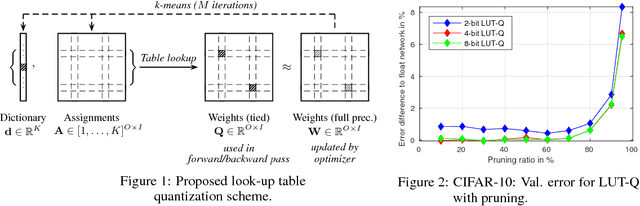

Operating deep neural networks (DNNs) on devices with limited resources requires the reduction of their memory as well as computational footprint. Popular reduction methods are network quantization or pruning, which either reduce the word length of the network parameters or remove weights from the network if they are not needed. In this article we discuss a general framework for network reduction which we call `Look-Up Table Quantization` (LUT-Q). For each layer, we learn a value dictionary and an assignment matrix to represent the network weights. We propose a special solver which combines gradient descent and a one-step k-means update to learn both the value dictionaries and assignment matrices iteratively. This method is very flexible: by constraining the value dictionary, many different reduction problems such as non-uniform network quantization, training of multiplierless networks, network pruning or simultaneous quantization and pruning can be implemented without changing the solver. This flexibility of the LUT-Q method allows us to use the same method to train networks for different hardware capabilities.
Differentiable Quantization of Deep Neural Networks
May 27, 2019


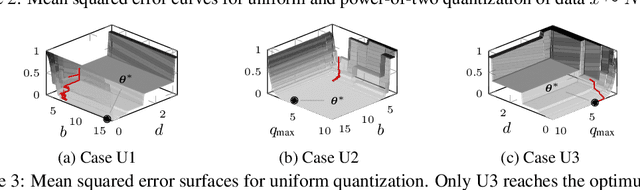
We propose differentiable quantization (DQ) for efficient deep neural network (DNN) inference where gradient descent is used to learn the quantizer's step size, dynamic range and bitwidth. Training with differentiable quantizers brings two main benefits: first, DQ does not introduce hyperparameters; second, we can learn for each layer a different step size, dynamic range and bitwidth. Our experiments show that DNNs with heterogeneous and learned bitwidth yield better performance than DNNs with a homogeneous one. Further, we show that there is one natural DQ parametrization especially well suited for training. We confirm our findings with experiments on CIFAR-10 and ImageNet and we obtain quantized DNNs with learned quantization parameters achieving state-of-the-art performance.
Improving DNN-based Music Source Separation using Phase Features
Jul 16, 2018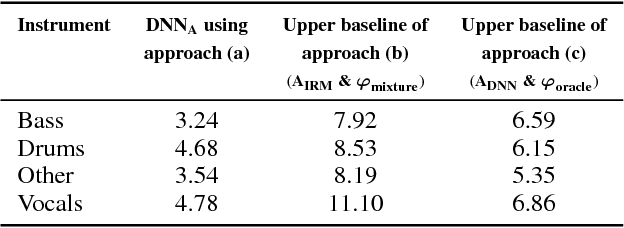
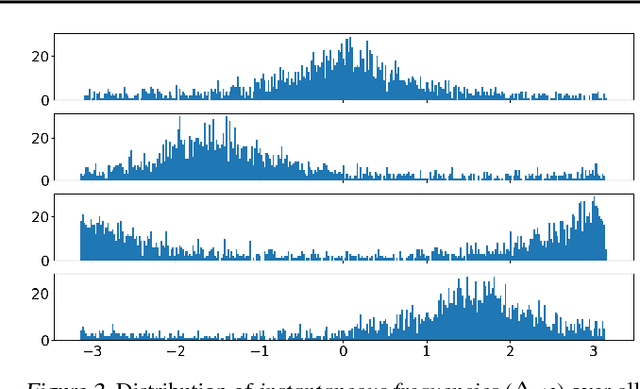
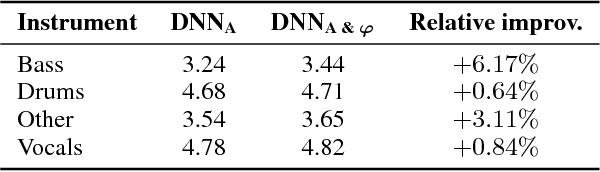
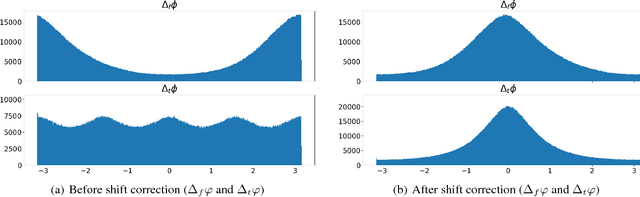
Music source separation with deep neural networks typically relies only on amplitude features. In this paper we show that additional phase features can improve the separation performance. Using the theoretical relationship between STFT phase and amplitude, we conjecture that derivatives of the phase are a good feature representation opposed to the raw phase. We verify this conjecture experimentally and propose a new DNN architecture which combines amplitude and phase. This joint approach achieves a better signal-to distortion ratio on the DSD100 dataset for all instruments compared to a network that uses only amplitude features. Especially, the bass instrument benefits from the phase information.