 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sampling for Predictor-Based Neural Architecture Search
Nov 24, 2020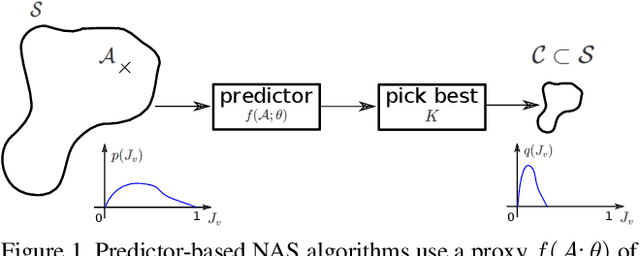

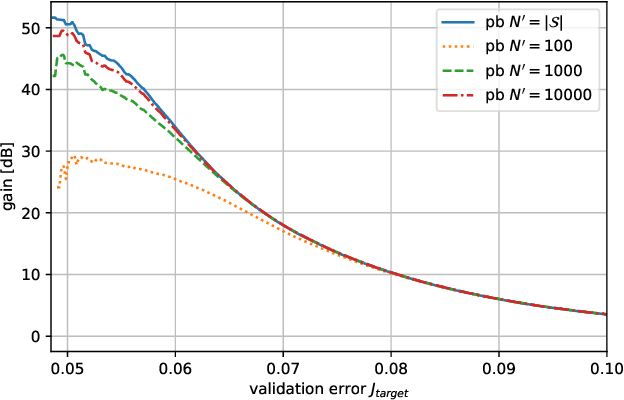
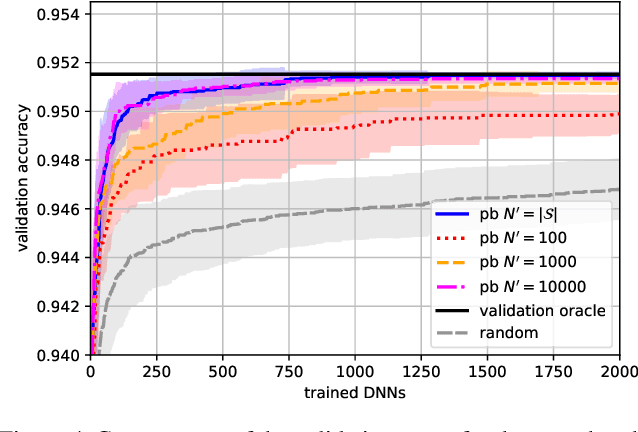
Recently, predictor-based algorithms emerged as a promising approach for neural architecture search (NAS). For NAS, we typically have to calculate the validation accuracy of a large number of Deep Neural Networks (DNNs), what is computationally complex. Predictor-based NAS algorithms address this problem. They train a proxy model that can infer the validation accuracy of DNNs directly from their network structure. During optimization, the proxy can be used to narrow down the number of architectures for which the true validation accuracy must be computed, what makes predictor-based algorithms sample efficient. Usually, we compute the proxy for all DNNs in the network search space and pick those that maximize the proxy as candidates for optimization. However, that is intractable in practice, because the search spaces are often very large and contain billions of network architectures. The contributions of this paper are threefold: 1) We define a sample efficiency gain to compare different predictor-based NAS algorithms. 2) We conduct experiments on the NASBench-101 dataset and show that the sample efficiency of predictor-based algorithms decreases dramatically if the proxy is only computed for a subset of the search space. 3) We show that if we choose the subset of the search space on which the proxy is evaluated in a smart way, the sample efficiency of the original predictor-based algorithm that has access to the full search space can be regained. This is an important step to make predictor-based NAS algorithms useful, in practice.