 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Apr 08, 2025We address the task of 3D reconstruction in dynamic scenes, where object motions degrade the quality of previous 3D pointmap regression methods, such as DUSt3R, originally designed for static 3D scene reconstruction. Although these methods provide an elegant and powerful solution in static settings, they struggle in the presence of dynamic motions that disrupt alignment based solely on camera poses. To overcome this, we propose D^2USt3R that regresses 4D pointmaps that simultaneiously capture both static and dynamic 3D scene geometry in a feed-forward manner. By explicitly incorporating both spatial and temporal aspects, our approach successfully encapsulates spatio-temporal dense correspondence to the proposed 4D pointmaps, enhancing downstream tasks. Extensive experimental evaluations demonstrate that our proposed approach consistently achieves superior reconstruction performance across various datasets featuring complex motions.
HumanGif: Single-View Human Diffusion with Generative Prior
Feb 17, 2025
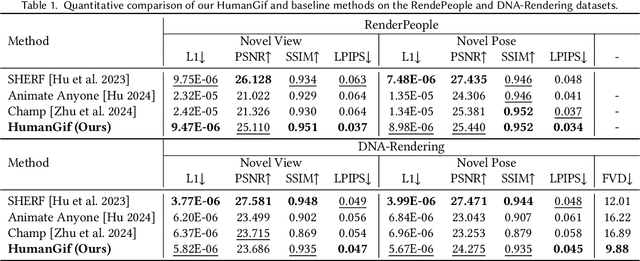
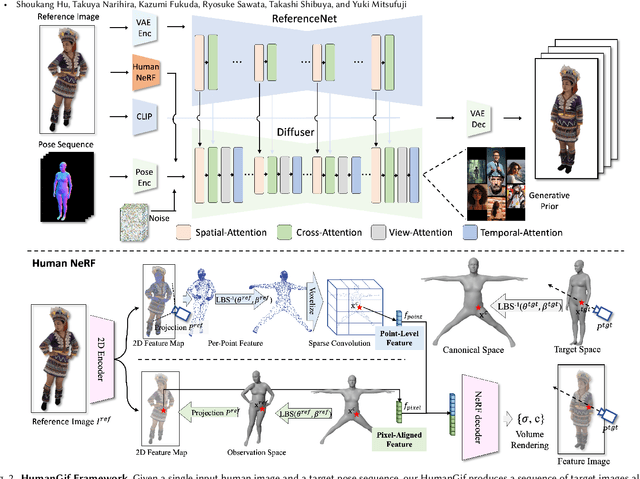

While previous single-view-based 3D human reconstruction methods made significant progress in novel view synthesis, it remains a challenge to synthesize both view-consistent and pose-consistent results for animatable human avatars from a single image input. Motivated by the success of 2D character animation, we propose <strong>HumanGif</strong>, a single-view human diffusion model with generative prior. Specifically, we formulate the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models. To ensure fine-grained and consistent novel view and pose synthesis, we introduce a Human NeRF module in HumanGif to learn spatially aligned features from the input image, implicitly capturing the relative camera and human pose transformation. Furthermore, we introduce an image-level loss during optimization to bridge the gap between latent and image spaces in diffusion models. Extensive experiments on RenderPeople and DNA-Rendering datasets demonstrate that HumanGif achieves the best perceptual performance, with better generalizability for novel view and pose synthesis.
GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping
May 27, 2024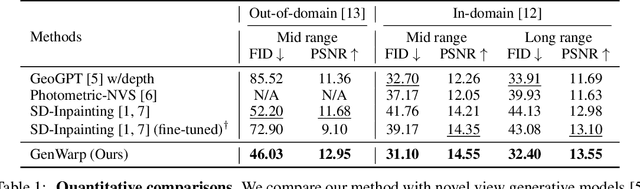
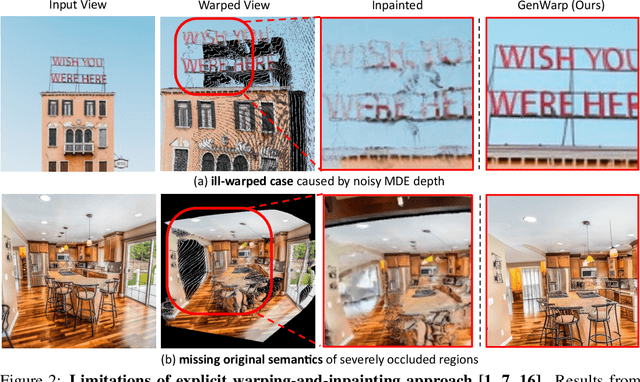

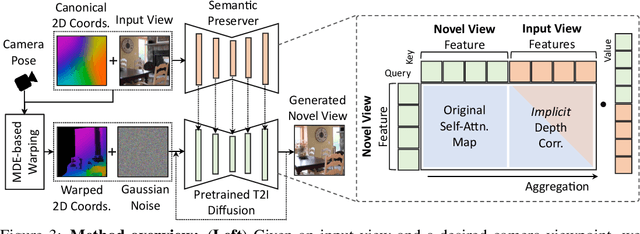
Generating novel views from a single image remains a challenging task due to the complexity of 3D scenes and the limited diversity in the existing multi-view datasets to train a model on. Recent research combining large-scale text-to-image (T2I) models with monocular depth estimation (MDE) has shown promise in handling in-the-wild images. In these methods, an input view is geometrically warped to novel views with estimated depth maps, then the warped image is inpainted by T2I models. However, they struggle with noisy depth maps and loss of semantic details when warping an input view to novel viewpoints. In this paper, we propose a novel approach for single-shot novel view synthesis, a semantic-preserving generative warping framework that enables T2I generative models to learn where to warp and where to generate, through augmenting cross-view attention with self-attention. Our approach addresses the limitations of existing methods by conditioning the generative model on source view images and incorporating geometric warping signals. Qualitative and quantitative evaluations demonstrate that our model outperforms existing methods in both in-domain and out-of-domain scenarios. Project page is available at https://GenWarp-NVS.github.io/.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023



We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
DetOFA: Efficient Training of Once-for-All Networks for Object Detection by Using Pre-trained Supernet and Path Filter
Mar 23, 2023



We address the challenge of training a large supernet for the object detection task, using a relatively small amount of training data. Specifically, we propose an efficient supernet-based neural architecture search (NAS) method that uses transfer learning and search space pruning. First, the supernet is pre-trained on a classification task, for which large datasets are available. Second, the search space defined by the supernet is pruned by removing candidate models that are predicted to perform poorly. To effectively remove the candidates over a wide range of resource constraints, we particularly design a performance predictor, called path filter, which can accurately predict the relative performance of the models that satisfy similar resource constraints. Hence, supernet training is more focused on the best-performing candidates. Our path filter handles prediction for paths with different resource budgets. Compared to once-for-all, our proposed method reduces the computational cost of the optimal network architecture by 30% and 63%, while yielding better accuracy-floating point operations Pareto front (0.85 and 0.45 points of improvement on average precision for Pascal VOC and COCO, respectively).
NDJIR: Neural Direct and Joint Inverse Rendering for Geometry, Lights, and Materials of Real Object
Feb 02, 2023



The goal of inverse rendering is to decompose geometry, lights, and materials given pose multi-view images. To achieve this goal, we propose neural direct and joint inverse rendering, NDJIR. Different from prior works which relies on some approximations of the rendering equation, NDJIR directly addresses the integrals in the rendering equation and jointly decomposes geometry: signed distance function, lights: environment and implicit lights, materials: base color, roughness, specular reflectance using the powerful and flexible volume rendering framework, voxel grid feature, and Bayesian prior. Our method directly uses the physically-based rendering, so we can seamlessly export an extracted mesh with materials to DCC tools and show material conversion examples. We perform intensive experiments to show that our proposed method can decompose semantically well for real object in photogrammetric setting and what factors contribute towards accurate inverse rendering.
Fine-grained Image Editing by Pixel-wise Guidance Using Diffusion Models
Dec 08, 2022



Generative models, particularly GANs, have been utilized for image editing. Although GAN-based methods perform well on generating reasonable contents aligned with the user's intentions, they struggle to strictly preserve the contents outside the editing region. To address this issue, we use diffusion models instead of GANs and propose a novel image-editing method, based on pixel-wise guidance. Specifically, we first train pixel-classifiers with few annotated data and then estimate the semantic segmentation map of a target image. Users then manipulate the map to instruct how the image is to be edited. The diffusion model generates an edited image via guidance by pixel-wise classifiers, such that the resultant image aligns with the manipulated map. As the guidance is conducted pixel-wise, the proposed method can create reasonable contents in the editing region while preserving the contents outside this region. The experimental results validate the advantages of the proposed method both quantitatively and qualitatively.
Thinking the Fusion Strategy of Multi-reference Face Reenactment
Feb 22, 2022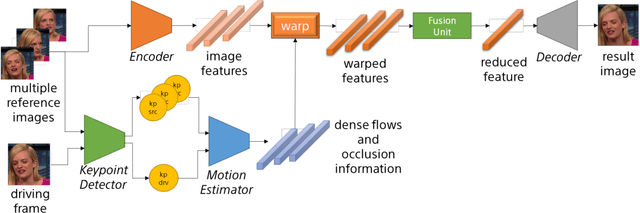



In recent advances of deep generative models, face reenactment -manipulating and controlling human face, including their head movement-has drawn much attention for its wide range of applicability. Despite its strong expressiveness, it is inevitable that the models fail to reconstruct or accurately generate unseen side of the face of a given single reference image. Most of existing methods alleviate this problem by learning appearances of human faces from large amount of data and generate realistic texture at inference time. Rather than completely relying on what generative models learn, we show that simple extension by using multiple reference images significantly improves generation quality. We show this by 1) conducting the reconstruction task on publicly available dataset, 2) conducting facial motion transfer on our original dataset which consists of multi-person's head movement video sequences, and 3) using a newly proposed evaluation metric to validate that our method achieves better quantitative results.
Data Cleansing for Deep Neural Networks with Storage-efficient Approximation of Influence Functions
Mar 22, 2021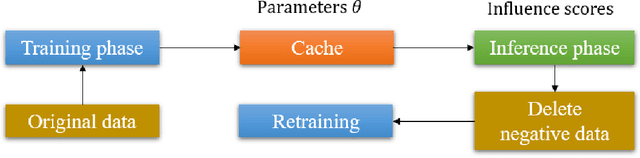
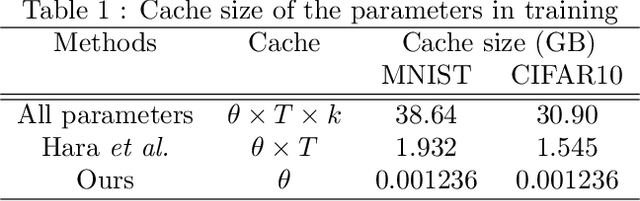
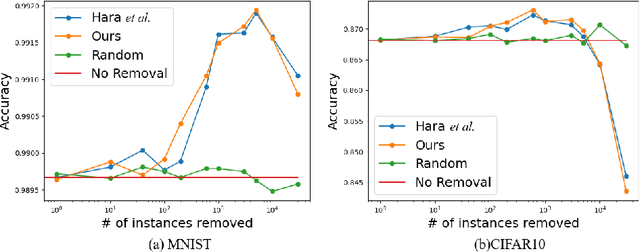

Identifying the influence of training data for data cleansing can improve the accuracy of deep learning. An approach with stochastic gradient descent (SGD) called SGD-influence to calculate the influence scores was proposed, but, the calculation costs are expensive. It is necessary to temporally store the parameters of the model during training phase for inference phase to calculate influence sores. In close connection with the previous method, we propose a method to reduce cache files to store the parameters in training phase for calculating inference score. We only adopt the final parameters in last epoch for influence functions calculation. In our experiments on classification, the cache size of training using MNIST dataset with our approach is 1.236 MB. On the other hand, the previous method used cache size of 1.932 GB in last epoch. It means that cache size has been reduced to 1/1,563. We also observed the accuracy improvement by data cleansing with removal of negatively influential data using our approach as well as the previous method. Moreover, our simple and general proposed method to calculate influence scores is available on our auto ML tool without programing, Neural Network Console. The source code is also available.