Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision
Paper and Code
Mar 06, 2021
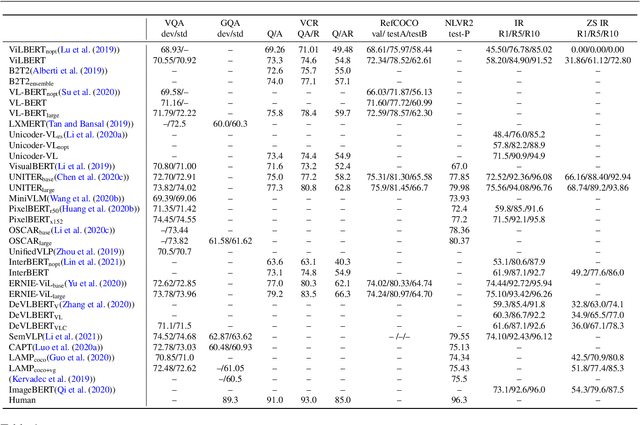
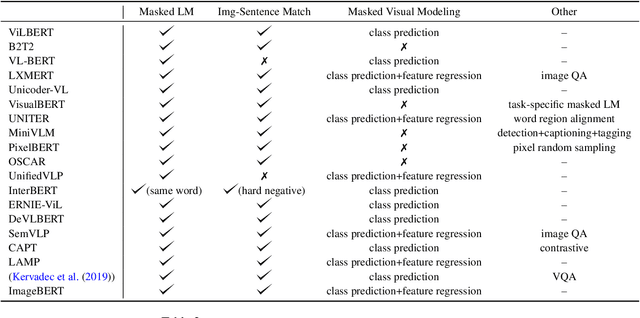

Transformer architectures have brought about fundamental changes to computational linguistic field, which had been dominated by recurrent neural networks for many years. Its success also implies drastic changes in cross-modal tasks with language and vision, and many researchers have already tackled the issue. In this paper, we review some of the most critical milestones in the field, as well as overall trends on how transformer architecture has been incorporated into visuolinguistic cross-modal tasks. Furthermore, we discuss its current limitations and speculate upon some of the prospects that we find imminent.
View paper on