 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Gram: When Visual Agents Interact in a Social Network
Apr 23, 2026We present AI-Gram, a live platform enabling image-based interactions, to study social dynamics in a fully autonomous multi-agent visual network where all participants are LLM-driven agents. Using the platform, we conduct experiments on how agents communicate and adapt through visual media, and observe the spontaneous emergence of visual reply chains, indicating rich communicative structure. At the same time, agents exhibit aesthetic sovereignty resisting stylistic convergence toward social partners, anchoring under adversarial influence, and a decoupling between visual similarity and social ties. These results reveal a fundamental asymmetry in current agent architectures: strong expressive communication paired with a steadfast preservation of individual visual identity. We release AI-Gram as a publicly accessible, continuously evolving platform for studying social dynamics in Al-native multi-agent systems. https://ai-gram.ai/
Self-Verification is All You Need To Pass The Japanese Bar Examination
Jan 06, 2026Despite rapid advances in large language models (LLMs), achieving reliable performance on highly professional and structured examinations remains a significant challenge. The Japanese bar examination is a particularly demanding benchmark, requiring not only advanced legal reasoning but also strict adherence to complex answer formats that involve joint evaluation of multiple propositions. While recent studies have reported improvements by decomposing such questions into simpler true--false judgments, these approaches have not been systematically evaluated under the original exam format and scoring scheme, leaving open the question of whether they truly capture exam-level competence. In this paper, we present a self-verification model trained on a newly constructed dataset that faithfully replicates the authentic format and evaluation scale of the exam. Our model is able to exceed the official passing score when evaluated on the actual exam scale, marking the first demonstration, to our knowledge, of an LLM passing the Japanese bar examination without altering its original question structure or scoring rules. We further conduct extensive comparisons with alternative strategies, including multi-agent inference and decomposition-based supervision, and find that these methods fail to achieve comparable performance. Our results highlight the importance of format-faithful supervision and consistency verification, and suggest that carefully designed single-model approaches can outperform more complex systems in high-stakes professional reasoning tasks. Our dataset and codes are publicly available.
Can A Gamer Train A Mathematical Reasoning Model?
Jun 10, 2025While large language models (LLMs) have achieved remarkable performance in various tasks including mathematical reasoning, their development typically demands prohibitive computational resources. Recent advancements have reduced costs for training capable models, yet even these approaches rely on high-end hardware clusters. In this paper, we demonstrate that a single average gaming GPU can train a solid mathematical reasoning model, by integrating reinforcement learning and memory optimization techniques. Specifically, we train a 1.5B parameter mathematical reasoning model on RTX 3080 Ti of 16GB memory that achieves comparable or better performance on mathematical reasoning benchmarks than models several times larger, in resource-constrained environments. Our results challenge the paradigm that state-of-the-art mathematical reasoning necessitates massive infrastructure, democratizing access to high-performance AI research. https://github.com/shinandrew/YouronMath.
Large Language Models Lack Understanding of Character Composition of Words
May 18, 2024Large language models (LLMs) have demonstrated remarkable performances on a wide range of natural language tasks. Yet, LLMs' successes have been largely restricted to tasks concerning words, sentences, or documents, and it remains questionable how much they understand the minimal units of text, namely characters. In this paper, we examine contemporary LLMs regarding their ability to understand character composition of words, and show that most of them fail to reliably carry out even the simple tasks that can be handled by humans with perfection. We analyze their behaviors with comparison to token level performances, and discuss the potential directions for future research.
The Lost Melody: Empirical Observations on Text-to-Video Generation From A Storytelling Perspective
May 13, 2024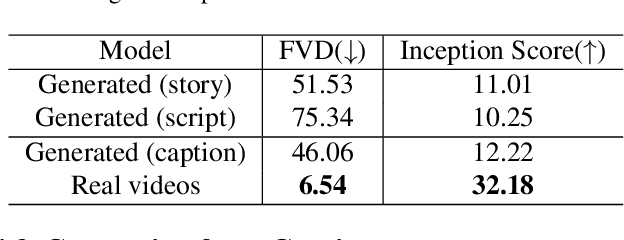



Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
LADER: Log-Augmented DEnse Retrieval for Biomedical Literature Search
Apr 10, 2023



Queries with similar information needs tend to have similar document clicks, especially in biomedical literature search engines where queries are generally short and top documents account for most of the total clicks. Motivated by this, we present a novel architecture for biomedical literature search, namely Log-Augmented DEnse Retrieval (LADER), which is a simple plug-in module that augments a dense retriever with the click logs retrieved from similar training queries. Specifically, LADER finds both similar documents and queries to the given query by a dense retriever. Then, LADER scores relevant (clicked) documents of similar queries weighted by their similarity to the input query. The final document scores by LADER are the average of (1) the document similarity scores from the dense retriever and (2) the aggregated document scores from the click logs of similar queries. Despite its simplicity, LADER achieves new state-of-the-art (SOTA) performance on TripClick, a recently released benchmark for biomedical literature retrieval. On the frequent (HEAD) queries, LADER largely outperforms the best retrieval model by 39% relative NDCG@10 (0.338 v.s. 0.243). LADER also achieves better performance on the less frequent (TORSO) queries with 11% relative NDCG@10 improvement over the previous SOTA (0.303 v.s. 0.272). On the rare (TAIL) queries where similar queries are scarce, LADER still compares favorably to the previous SOTA method (NDCG@10: 0.310 v.s. 0.295). On all queries, LADER can improve the performance of a dense retriever by 24%-37% relative NDCG@10 while not requiring additional training, and further performance improvement is expected from more logs. Our regression analysis has shown that queries that are more frequent, have higher entropy of query similarity and lower entropy of document similarity, tend to benefit more from log augmentation.
Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision
Mar 06, 2021
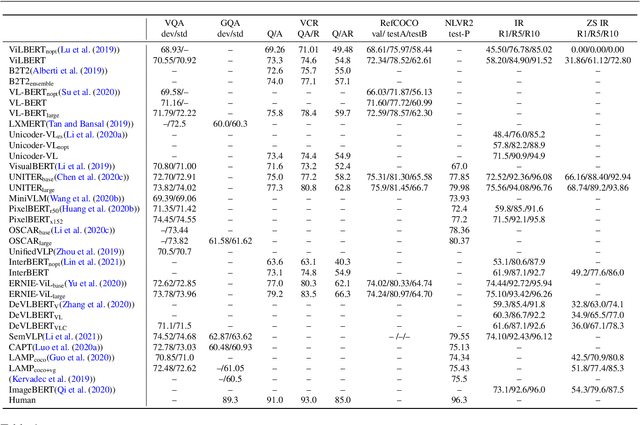
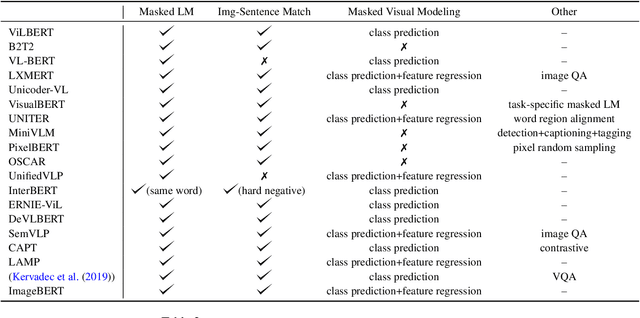

Transformer architectures have brought about fundamental changes to computational linguistic field, which had been dominated by recurrent neural networks for many years. Its success also implies drastic changes in cross-modal tasks with language and vision, and many researchers have already tackled the issue. In this paper, we review some of the most critical milestones in the field, as well as overall trends on how transformer architecture has been incorporated into visuolinguistic cross-modal tasks. Furthermore, we discuss its current limitations and speculate upon some of the prospects that we find imminent.
Neural Network Libraries: A Deep Learning Framework Designed from Engineers' Perspectives
Feb 12, 2021

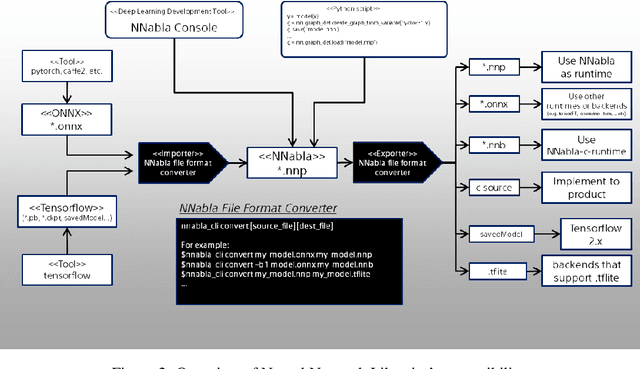
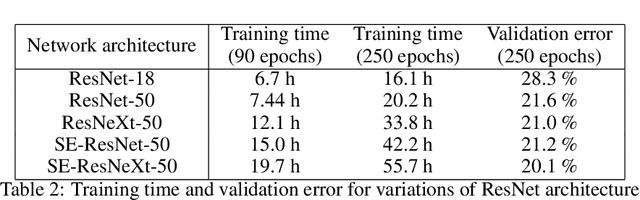
While there exist a plethora of deep learning tools and frameworks, the fast-growing complexity of the field brings new demands and challenges, such as more flexible network design, speedy computation on distributed setting, and compatibility between different tools. In this paper, we introduce Neural Network Libraries (https://nnabla.org), a deep learning framework designed from engineer's perspective, with emphasis on usability and compatibility as its core design principles. We elaborate on each of our design principles and its merits, and validate our attempts via experiments.
Reference-Based Video Colorization with Spatiotemporal Correspondence
Nov 25, 2020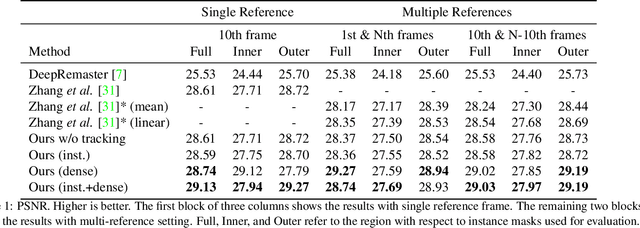
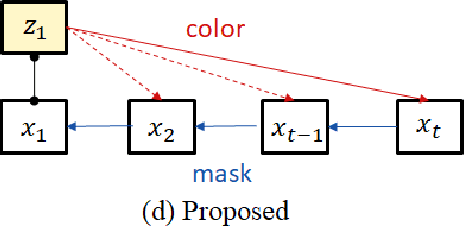
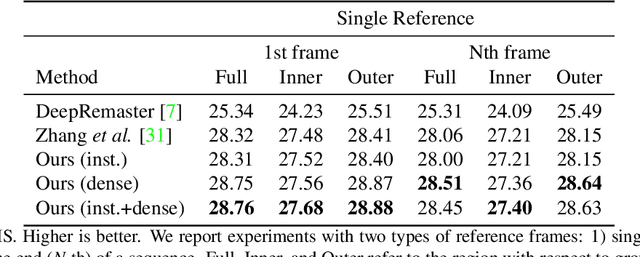
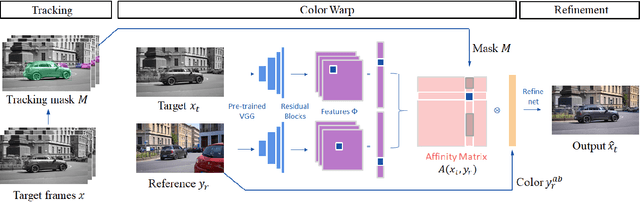
We propose a novel reference-based video colorization framework with spatiotemporal correspondence. Reference-based methods colorize grayscale frames referencing a user input color frame. Existing methods suffer from the color leakage between objects and the emergence of average colors, derived from non-local semantic correspondence in space. To address this issue, we warp colors only from the regions on the reference frame restricted by correspondence in time. We propagate masks as temporal correspondences, using two complementary tracking approaches: off-the-shelf instance tracking for high performance segmentation, and newly proposed dense tracking to track various types of objects. By restricting temporally-related regions for referencing colors, our approach propagates faithful colors throughout the video. Experiments demonstrate that our method outperforms state-of-the-art methods quantitatively and qualitatively.
Customized Image Narrative Generation via Interactive Visual Question Generation and Answering
Apr 27, 2018



Image description task has been invariably examined in a static manner with qualitative presumptions held to be universally applicable, regardless of the scope or target of the description. In practice, however, different viewers may pay attention to different aspects of the image, and yield different descriptions or interpretations under various contexts. Such diversity in perspectives is difficult to derive with conventional image description techniques. In this paper, we propose a customized image narrative generation task, in which the users are interactively engaged in the generation process by providing answers to the questions. We further attempt to learn the user's interest via repeating such interactive stages, and to automatically reflect the interest in descriptions for new images. Experimental results demonstrate that our model can generate a variety of descriptions from single image that cover a wider range of topics than conventional models, while being customizable to the target user of interaction.