 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualNet: Domain-Invariant Network for Visual Question Answering
Paper and Code
May 04, 2017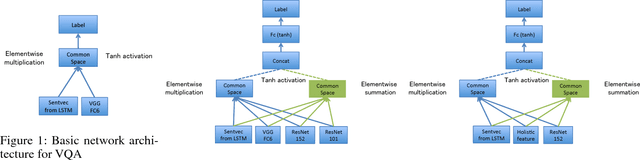
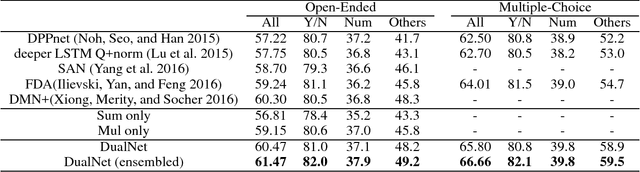
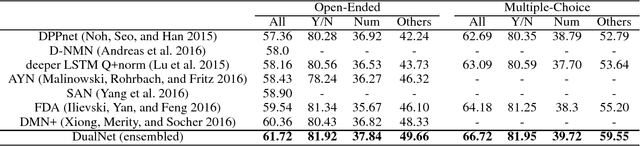

Visual question answering (VQA) task not only bridges the gap between images and language, but also requires that specific contents within the image are understood as indicated by linguistic context of the question, in order to generate the accurate answers. Thus, it is critical to build an efficient embedding of images and texts. We implement DualNet, which fully takes advantage of discriminative power of both image and textual features by separately performing two operations. Building an ensemble of DualNet further boosts the performance. Contrary to common belief, our method proved effective in both real images and abstract scenes, in spite of significantly different properties of respective domain. Our method was able to outperform previous state-of-the-art methods in real images category even without explicitly employing attention mechanism, and also outperformed our own state-of-the-art method in abstract scenes category, which recently won the first place in VQA Challenge 2016.