 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAm I More Pointwise or Pairwise? Revealing Position Bias in Rubric-Based LLM-as-a-Judge
Feb 02, 2026Large language models (LLMs) are now widely used to evaluate the quality of text, a field commonly referred to as LLM-as-a-judge. While prior works mainly focus on point-wise and pair-wise evaluation paradigms. Rubric-based evaluation, where LLMs select a score from multiple rubrics, has received less analysis. In this work, we show that rubric-based evaluation implicitly resembles a multi-choice setting and therefore has position bias: LLMs prefer score options appearing at specific positions in the rubric list. Through controlled experiments across multiple models and datasets, we demonstrate consistent position bias. To mitigate this bias, we propose a balanced permutation strategy that evenly distributes each score option across positions. We show that aggregating scores across balanced permutations not only reveals latent position bias, but also improves correlation between the LLM-as-a-Judge and human. Our results suggest that rubric-based LLM-as-a-Judge is not inherently point-wise and that simple permutation-based calibration can substantially improve its reliability.
WarrantScore: Modeling Warrants between Claims and Evidence for Substantiation Evaluation in Peer Reviews
Jan 24, 2026The scientific peer-review process is facing a shortage of human resources due to the rapid growth in the number of submitted papers. The use of language models to reduce the human cost of peer review has been actively explored as a potential solution to this challenge. A method has been proposed to evaluate the level of substantiation in scientific reviews in a manner that is interpretable by humans. This method extracts the core components of an argument, claims and evidence, and assesses the level of substantiation based on the proportion of claims supported by evidence. The level of substantiation refers to the extent to which claims are based on objective facts. However, when assessing the level of substantiation, simply detecting the presence or absence of supporting evidence for a claim is insufficient; it is also necessary to accurately assess the logical inference between a claim and its evidence. We propose a new evaluation metric for scientific review comments that assesses the logical inference between claims and evidence. Experimental results show that the proposed method achieves a higher correlation with human scores than conventional methods, indicating its potential to better support the efficiency of the peer-review process.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025

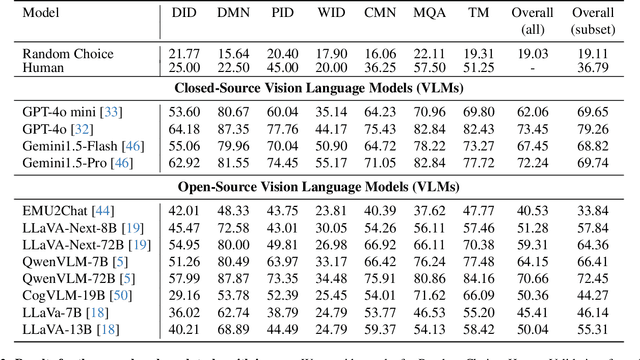
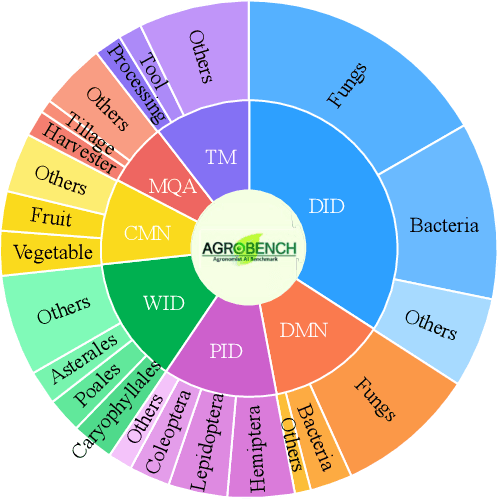
Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning
Jul 02, 2025An image captioning model flexibly switching its language pattern, e.g., descriptiveness and length, should be useful since it can be applied to diverse applications. However, despite the dramatic improvement in generative vision-language models, fine-grained control over the properties of generated captions is not easy due to two reasons: (i) existing models are not given the properties as a condition during training and (ii) existing models cannot smoothly transition its language pattern from one state to the other. Given this challenge, we propose a new approach, CaptionSmiths, to acquire a single captioning model that can handle diverse language patterns. First, our approach quantifies three properties of each caption, length, descriptiveness, and uniqueness of a word, as continuous scalar values, without human annotation. Given the values, we represent the conditioning via interpolation between two endpoint vectors corresponding to the extreme states, e.g., one for a very short caption and one for a very long caption. Empirical results demonstrate that the resulting model can smoothly change the properties of the output captions and show higher lexical alignment than baselines. For instance, CaptionSmiths reduces the error in controlling caption length by 506\% despite better lexical alignment. Code will be available on https://github.com/omron-sinicx/captionsmiths.
Perspective on Utilizing Foundation Models for Laboratory Automation in Materials Research
Jun 14, 2025This review explores the potential of foundation models to advance laboratory automation in the materials and chemical sciences. It emphasizes the dual roles of these models: cognitive functions for experimental planning and data analysis, and physical functions for hardware operations. While traditional laboratory automation has relied heavily on specialized, rigid systems, foundation models offer adaptability through their general-purpose intelligence and multimodal capabilities. Recent advancements have demonstrated the feasibility of using large language models (LLMs) and multimodal robotic systems to handle complex and dynamic laboratory tasks. However, significant challenges remain, including precision manipulation of hardware, integration of multimodal data, and ensuring operational safety. This paper outlines a roadmap highlighting future directions, advocating for close interdisciplinary collaboration, benchmark establishment, and strategic human-AI integration to realize fully autonomous experimental laboratories.
SCU-Hand: Soft Conical Universal Robotic Hand for Scooping Granular Media from Containers of Various Sizes
May 07, 2025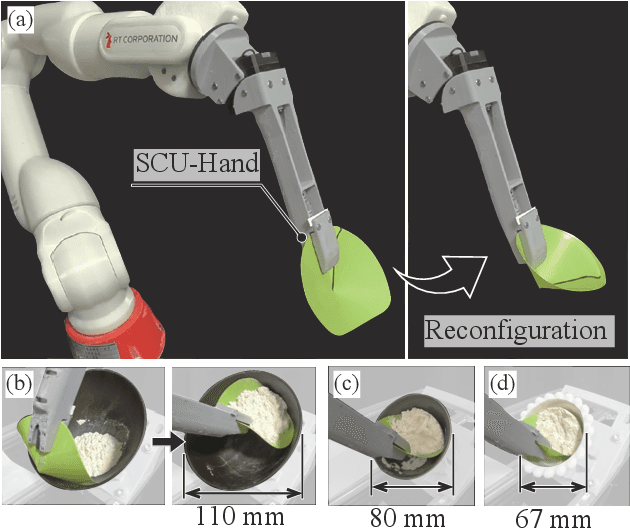
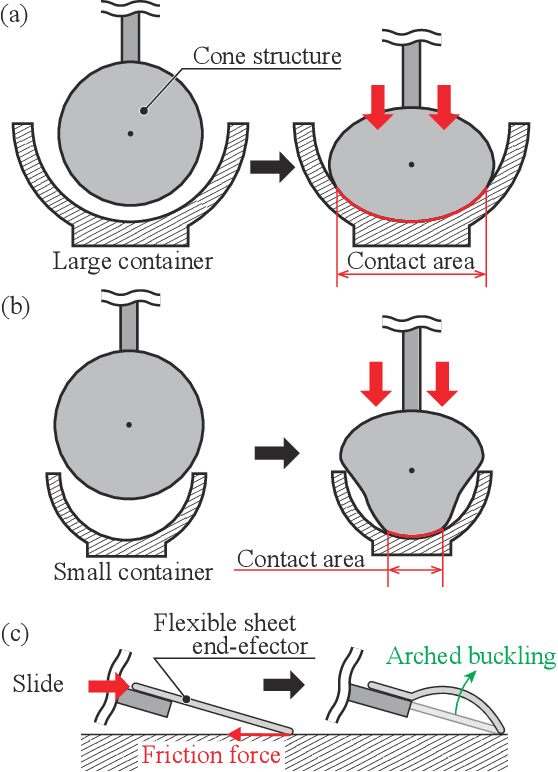
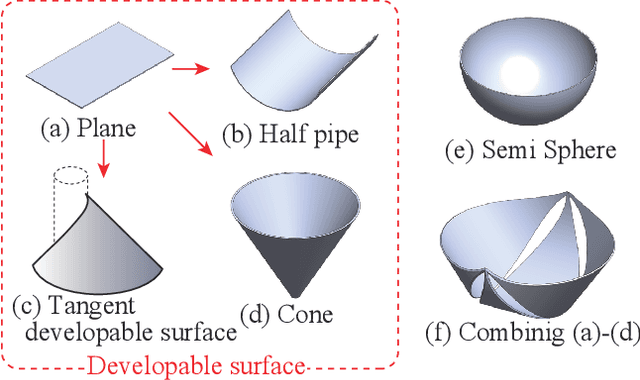
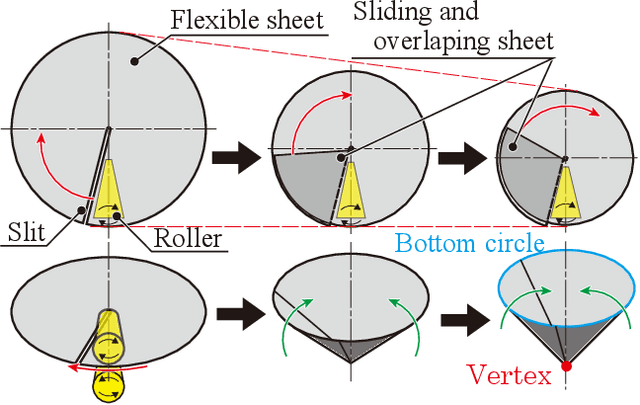
Automating small-scale experiments in materials science presents challenges due to the heterogeneous nature of experimental setups. This study introduces the SCU-Hand (Soft Conical Universal Robot Hand), a novel end-effector designed to automate the task of scooping powdered samples from various container sizes using a robotic arm. The SCU-Hand employs a flexible, conical structure that adapts to different container geometries through deformation, maintaining consistent contact without complex force sensing or machine learning-based control methods. Its reconfigurable mechanism allows for size adjustment, enabling efficient scooping from diverse container types. By combining soft robotics principles with a sheet-morphing design, our end-effector achieves high flexibility while retaining the necessary stiffness for effective powder manipulation. We detail the design principles, fabrication process, and experimental validation of the SCU-Hand. Experimental validation showed that the scooping capacity is about 20% higher than that of a commercial tool, with a scooping performance of more than 95% for containers of sizes between 67 mm to 110 mm. This research contributes to laboratory automation by offering a cost-effective, easily implementable solution for automating tasks such as materials synthesis and characterization processes.
CrystalFramer: Rethinking the Role of Frames for SE(3)-Invariant Crystal Structure Modeling
Mar 04, 2025



Crystal structure modeling with graph neural networks is essential for various applications in materials informatics, and capturing SE(3)-invariant geometric features is a fundamental requirement for these networks. A straightforward approach is to model with orientation-standardized structures through structure-aligned coordinate systems, or"frames." However, unlike molecules, determining frames for crystal structures is challenging due to their infinite and highly symmetric nature. In particular, existing methods rely on a statically fixed frame for each structure, determined solely by its structural information, regardless of the task under consideration. Here, we rethink the role of frames, questioning whether such simplistic alignment with the structure is sufficient, and propose the concept of dynamic frames. While accommodating the infinite and symmetric nature of crystals, these frames provide each atom with a dynamic view of its local environment, focusing on actively interacting atoms. We demonstrate this concept by utilizing the attention mechanism in a recent transformer-based crystal encoder, resulting in a new architecture called CrystalFramer. Extensive experiments show that CrystalFramer outperforms conventional frames and existing crystal encoders in various crystal property prediction tasks.
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images
Dec 23, 2024



Building a large-scale figure QA dataset requires a considerable amount of work, from gathering and selecting figures to extracting attributes like text, numbers, and colors, and generating QAs. Although recent developments in LLMs have led to efforts to synthesize figures, most of these focus primarily on QA generation. Additionally, creating figures directly using LLMs often encounters issues such as code errors, similar-looking figures, and repetitive content in figures. To address this issue, we present SBSFigures (Stage-by-Stage Synthetic Figures), a dataset for pre-training figure QA. Our proposed pipeline enables the creation of chart figures with complete annotations of the visualized data and dense QA annotations without any manual annotation process. Our stage-by-stage pipeline makes it possible to create diverse topic and appearance figures efficiently while minimizing code errors. Our SBSFigures demonstrate a strong pre-training effect, making it possible to achieve efficient training with a limited amount of real-world chart data starting from our pre-trained weights.
Adaptive Constraint Integration for Simultaneously Optimizing Crystal Structures with Multiple Targeted Properties
Oct 11, 2024In materials science, finding crystal structures that have targeted properties is crucial. While recent methodologies such as Bayesian optimization and deep generative models have made some advances on this issue, these methods often face difficulties in adaptively incorporating various constraints, such as electrical neutrality and targeted properties optimization, while keeping the desired specific crystal structure. To address these challenges, we have developed the Simultaneous Multi-property Optimization using Adaptive Crystal Synthesizer (SMOACS), which utilizes state-of-the-art property prediction models and their gradients to directly optimize input crystal structures for targeted properties simultaneously. SMOACS enables the integration of adaptive constraints into the optimization process without necessitating model retraining. Thanks to this feature, SMOACS has succeeded in simultaneously optimizing targeted properties while maintaining perovskite structures, even with models trained on diverse crystal types. We have demonstrated the band gap optimization while meeting a challenging constraint, that is, maintaining electrical neutrality in large atomic configurations up to 135 atom sites, where the verification of the electrical neutrality is challenging. The properties of the most promising materials have been confirmed by density functional theory calculations.
MaterialBENCH: Evaluating College-Level Materials Science Problem-Solving Abilities of Large Language Models
Sep 05, 2024



A college-level benchmark dataset for large language models (LLMs) in the materials science field, MaterialBENCH, is constructed. This dataset consists of problem-answer pairs, based on university textbooks. There are two types of problems: one is the free-response answer type, and the other is the multiple-choice type. Multiple-choice problems are constructed by adding three incorrect answers as choices to a correct answer, so that LLMs can choose one of the four as a response. Most of the problems for free-response answer and multiple-choice types overlap except for the format of the answers. We also conduct experiments using the MaterialBENCH on LLMs, including ChatGPT-3.5, ChatGPT-4, Bard (at the time of the experiments), and GPT-3.5 and GPT-4 with the OpenAI API. The differences and similarities in the performance of LLMs measured by the MaterialBENCH are analyzed and discussed. Performance differences between the free-response type and multiple-choice type in the same models and the influence of using system massages on multiple-choice problems are also studied. We anticipate that MaterialBENCH will encourage further developments of LLMs in reasoning abilities to solve more complicated problems and eventually contribute to materials research and discovery.