 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEC-Bench: Enumeration and Counting Benchmark for Ultra-Long Videos
Mar 31, 2026Counting in long videos remains a fundamental yet underexplored challenge in computer vision. Real-world recordings often span tens of minutes or longer and contain sparse, diverse events, making long-range temporal reasoning particularly difficult. However, most existing video counting benchmarks focus on short clips and evaluate only the final numerical answer, providing little insight into what should be counted or whether models consistently identify relevant instances across time. We introduce EC-Bench, a benchmark that jointly evaluates enumeration, counting, and temporal evidence grounding in long-form videos. EC-Bench contains 152 videos longer than 30 minutes and 1,699 queries paired with explicit evidence spans. Across 22 multimodal large language models (MLLMs), the best model achieves only 29.98% accuracy on Enumeration and 23.74% on Counting, while human performance reaches 78.57% and 82.97%, respectively. Our analysis reveals strong relationships between enumeration accuracy, temporal grounding, and counting performance. These results highlight fundamental limitations of current MLLMs and establish EC-Bench as a challenging benchmark for long-form quantitative video reasoning.
BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
Mar 25, 2026Understanding animal species from multimodal data poses an emerging challenge at the intersection of computer vision and ecology. While recent biological models, such as BioCLIP, have demonstrated strong alignment between images and textual taxonomic information for species identification, the integration of the audio modality remains an open problem. We propose BioVITA, a novel visual-textual-acoustic alignment framework for biological applications. BioVITA involves (i) a training dataset, (ii) a representation model, and (iii) a retrieval benchmark. First, we construct a large-scale training dataset comprising 1.3 million audio clips and 2.3 million images, covering 14,133 species annotated with 34 ecological trait labels. Second, building upon BioCLIP2, we introduce a two-stage training framework to effectively align audio representations with visual and textual representations. Third, we develop a cross-modal retrieval benchmark that covers all possible directional retrieval across the three modalities (i.e., image-to-audio, audio-to-text, text-to-image, and their reverse directions), with three taxonomic levels: Family, Genus, and Species. Extensive experiments demonstrate that our model learns a unified representation space that captures species-level semantics beyond taxonomy, advancing multimodal biodiversity understanding. The project page is available at: https://dahlian00.github.io/BioVITA_Page/
AnimalCLAP: Taxonomy-Aware Language-Audio Pretraining for Species Recognition and Trait Inference
Mar 23, 2026Animal vocalizations provide crucial insights for wildlife assessment, particularly in complex environments such as forests, aiding species identification and ecological monitoring. Recent advances in deep learning have enabled automatic species classification from their vocalizations. However, classifying species unseen during training remains challenging. To address this limitation, we introduce AnimalCLAP, a taxonomy-aware language-audio framework comprising a new dataset and model that incorporate hierarchical biological information. Specifically, our vocalization dataset consists of 4,225 hours of recordings covering 6,823 species, annotated with 22 ecological traits. The AnimalCLAP model is trained on this dataset to align audio and textual representations using taxonomic structures, improving the recognition of unseen species. We demonstrate that our proposed model effectively infers ecological and biological attributes of species directly from their vocalizations, achieving superior performance compared to CLAP. Our dataset, code, and models will be publicly available at https://dahlian00.github.io/AnimalCLAP_Page/.
PhysQuantAgent: An Inference Pipeline of Mass Estimation for Vision-Language Models
Mar 17, 2026Vision-Language Models (VLMs) are increasingly applied to robotic perception and manipulation, yet their ability to infer physical properties required for manipulation remains limited. In particular, estimating the mass of real-world objects is essential for determining appropriate grasp force and ensuring safe interaction. However, current VLMs lack reliable mass reasoning capabilities, and most existing benchmarks do not explicitly evaluate physical quantity estimation under realistic sensing conditions. In this work, we propose PhysQuantAgent, a framework for real-world object mass estimation using VLMs, together with VisPhysQuant, a new benchmark dataset for evaluation. VisPhysQuant consists of RGB-D videos of real objects captured from multiple viewpoints, annotated with precise mass measurements. To improve estimation accuracy, we introduce three visual prompting methods that enhance the input image with object detection, scale estimation, and cross-sectional image generation to help the model comprehend the size and internal structure of the target object. Experiments show that visual prompting significantly improves mass estimation accuracy on real-world data, suggesting the efficacy of integrating spatial reasoning with VLM knowledge for physical inference.
Autoregressive Direct Preference Optimization
Feb 10, 2026Direct preference optimization (DPO) has emerged as a promising approach for aligning large language models (LLMs) with human preferences. However, the widespread reliance on the response-level Bradley-Terry (BT) model may limit its full potential, as the reference and learnable models are assumed to be autoregressive only after deriving the objective function. Motivated by this limitation, we revisit the theoretical foundations of DPO and propose a novel formulation that explicitly introduces the autoregressive assumption prior to applying the BT model. By reformulating and extending DPO, we derive a novel variant, termed Autoregressive DPO (ADPO), that explicitly integrates autoregressive modeling into the preference optimization framework. Without violating the theoretical foundations, the derived loss takes an elegant form: it shifts the summation operation in the DPO objective outside the log-sigmoid function. Furthermore, through theoretical analysis of ADPO, we show that there exist two length measures to be considered when designing DPO-based algorithms: the token length $μ$ and the feedback length $μ$'. To the best of our knowledge, we are the first to explicitly distinguish these two measures and analyze their implications for preference optimization in LLMs.
From Correspondence to Actions: Human-Like Multi-Image Spatial Reasoning in Multi-modal Large Language Models
Feb 09, 2026While multimodal large language models (MLLMs) have made substantial progress in single-image spatial reasoning, multi-image spatial reasoning, which requires integration of information from multiple viewpoints, remains challenging. Cognitive studies suggest that humans address such tasks through two mechanisms: cross-view correspondence, which identifies regions across different views that correspond to the same physical locations, and stepwise viewpoint transformation, which composes relative viewpoint changes sequentially. However, existing studies incorporate these mechanisms only partially and often implicitly, without explicit supervision for both. We propose Human-Aware Training for Cross-view correspondence and viewpoint cHange (HATCH), a training framework with two complementary objectives: (1) Patch-Level Spatial Alignment, which encourages patch representations to align across views for spatially corresponding regions, and (2) Action-then-Answer Reasoning, which requires the model to generate explicit viewpoint transition actions before predicting the final answer. Experiments on three benchmarks demonstrate that HATCH consistently outperforms baselines of comparable size by a clear margin and achieves competitive results against much larger models, while preserving single-image reasoning capabilities.
DISCODE: Distribution-Aware Score Decoder for Robust Automatic Evaluation of Image Captioning
Dec 16, 2025Large vision-language models (LVLMs) have shown impressive performance across a broad range of multimodal tasks. However, robust image caption evaluation using LVLMs remains challenging, particularly under domain-shift scenarios. To address this issue, we introduce the Distribution-Aware Score Decoder (DISCODE), a novel finetuning-free method that generates robust evaluation scores better aligned with human judgments across diverse domains. The core idea behind DISCODE lies in its test-time adaptive evaluation approach, which introduces the Adaptive Test-Time (ATT) loss, leveraging a Gaussian prior distribution to improve robustness in evaluation score estimation. This loss is efficiently minimized at test time using an analytical solution that we derive. Furthermore, we introduce the Multi-domain Caption Evaluation (MCEval) benchmark, a new image captioning evaluation benchmark covering six distinct domains, designed to assess the robustness of evaluation metrics. In our experiments, we demonstrate that DISCODE achieves state-of-the-art performance as a reference-free evaluation metric across MCEval and four representative existing benchmarks.
STATUS Bench: A Rigorous Benchmark for Evaluating Object State Understanding in Vision-Language Models
Oct 26, 2025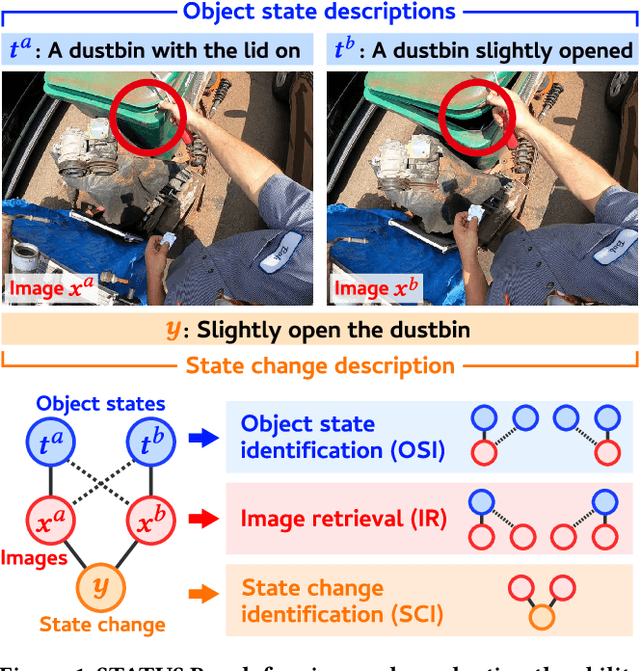



Object state recognition aims to identify the specific condition of objects, such as their positional states (e.g., open or closed) and functional states (e.g., on or off). While recent Vision-Language Models (VLMs) are capable of performing a variety of multimodal tasks, it remains unclear how precisely they can identify object states. To alleviate this issue, we introduce the STAte and Transition UnderStanding Benchmark (STATUS Bench), the first benchmark for rigorously evaluating the ability of VLMs to understand subtle variations in object states in diverse situations. Specifically, STATUS Bench introduces a novel evaluation scheme that requires VLMs to perform three tasks simultaneously: object state identification (OSI), image retrieval (IR), and state change identification (SCI). These tasks are defined over our fully hand-crafted dataset involving image pairs, their corresponding object state descriptions and state change descriptions. Furthermore, we introduce a large-scale training dataset, namely STATUS Train, which consists of 13 million semi-automatically created descriptions. This dataset serves as the largest resource to facilitate further research in this area. In our experiments, we demonstrate that STATUS Bench enables rigorous consistency evaluation and reveal that current state-of-the-art VLMs still significantly struggle to capture subtle object state distinctions. Surprisingly, under the proposed rigorous evaluation scheme, most open-weight VLMs exhibited chance-level zero-shot performance. After fine-tuning on STATUS Train, Qwen2.5-VL achieved performance comparable to Gemini 2.0 Flash. These findings underscore the necessity of STATUS Bench and Train for advancing object state recognition in VLM research.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025

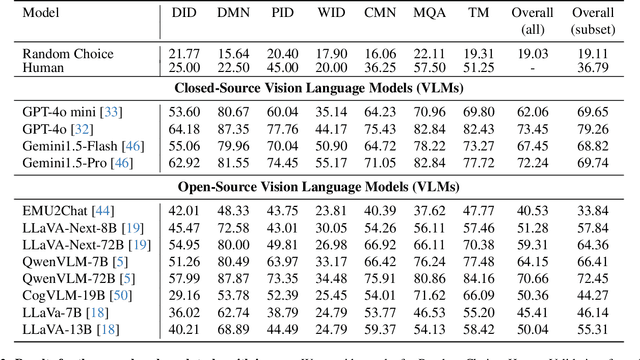
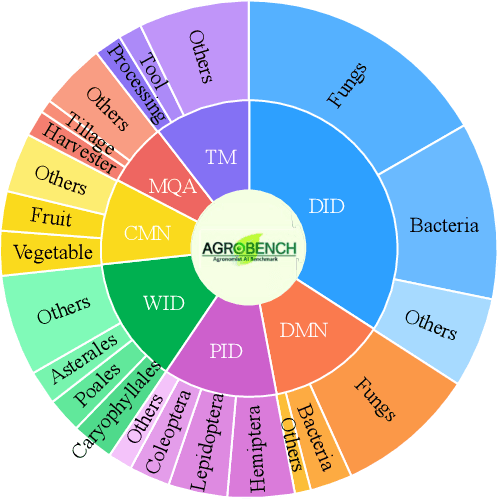
Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025



Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/