 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Image Super-Resolution from Training Data Perspectives
Paper and Code

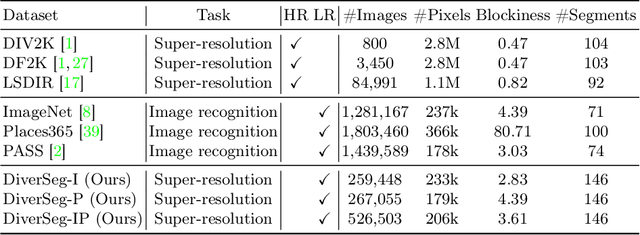

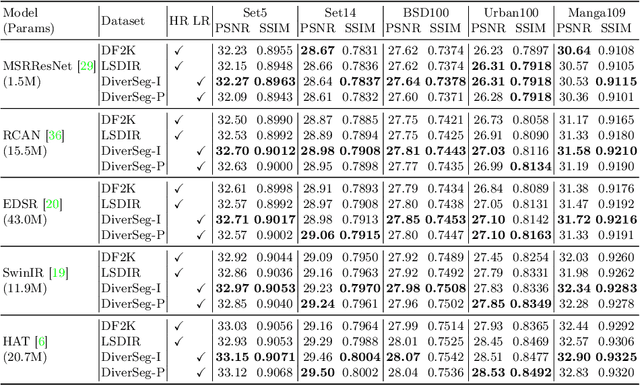
In this work, we investigate the understudied effect of the training data used for image super-resolution (SR). Most commonly, novel SR methods are developed and benchmarked on common training datasets such as DIV2K and DF2K. However, we investigate and rethink the training data from the perspectives of diversity and quality, {thereby addressing the question of ``How important is SR training for SR models?''}. To this end, we propose an automated image evaluation pipeline. With this, we stratify existing high-resolution image datasets and larger-scale image datasets such as ImageNet and PASS to compare their performances. We find that datasets with (i) low compression artifacts, (ii) high within-image diversity as judged by the number of different objects, and (iii) a large number of images from ImageNet or PASS all positively affect SR performance. We hope that the proposed simple-yet-effective dataset curation pipeline will inform the construction of SR datasets in the future and yield overall better models.