 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation with Noisy Labels via Spatially Correlated Distributions
Apr 21, 2025In semantic segmentation, the accuracy of models heavily depends on the high-quality annotations. However, in many practical scenarios such as medical imaging and remote sensing, obtaining true annotations is not straightforward and usually requires significant human labor. Relying on human labor often introduces annotation errors, including mislabeling, omissions, and inconsistency between annotators. In the case of remote sensing, differences in procurement time can lead to misaligned ground truth annotations. These label errors are not independently distributed, and instead usually appear in spatially connected regions where adjacent pixels are more likely to share the same errors. To address these issues, we propose an approximate Bayesian estimation based on a probabilistic model that assumes training data includes label errors, incorporating the tendency for these errors to occur with spatial correlations between adjacent pixels. Bayesian inference requires computing the posterior distribution of label errors, which becomes intractable when spatial correlations are present. We represent the correlation of label errors between adjacent pixels through a Gaussian distribution whose covariance is structured by a Kac-Murdock-Szeg\"{o} (KMS) matrix, solving the computational challenges. Through experiments on multiple segmentation tasks, we confirm that leveraging the spatial correlation of label errors significantly improves performance. Notably, in specific tasks such as lung segmentation, the proposed method achieves performance comparable to training with clean labels under moderate noise levels. Code is available at https://github.com/pfnet-research/Bayesian_SpatialCorr.
Rethinking Image Super-Resolution from Training Data Perspectives
Sep 01, 2024
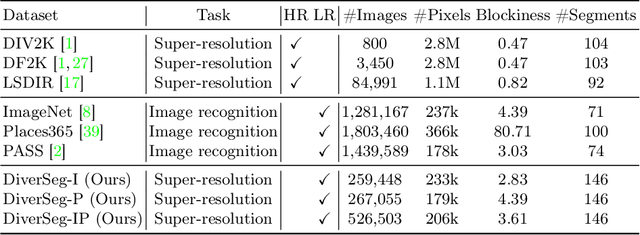

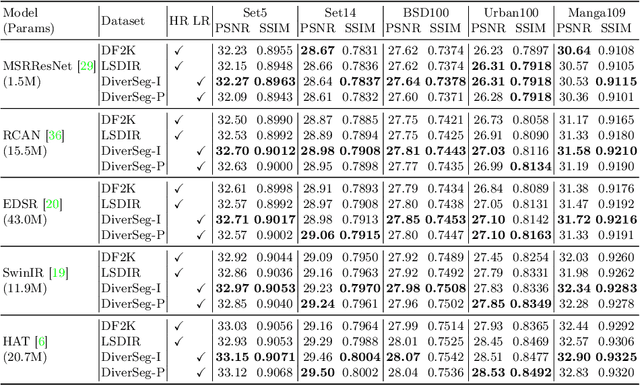
In this work, we investigate the understudied effect of the training data used for image super-resolution (SR). Most commonly, novel SR methods are developed and benchmarked on common training datasets such as DIV2K and DF2K. However, we investigate and rethink the training data from the perspectives of diversity and quality, {thereby addressing the question of ``How important is SR training for SR models?''}. To this end, we propose an automated image evaluation pipeline. With this, we stratify existing high-resolution image datasets and larger-scale image datasets such as ImageNet and PASS to compare their performances. We find that datasets with (i) low compression artifacts, (ii) high within-image diversity as judged by the number of different objects, and (iii) a large number of images from ImageNet or PASS all positively affect SR performance. We hope that the proposed simple-yet-effective dataset curation pipeline will inform the construction of SR datasets in the future and yield overall better models.
Scaling Backwards: Minimal Synthetic Pre-training?
Aug 03, 2024
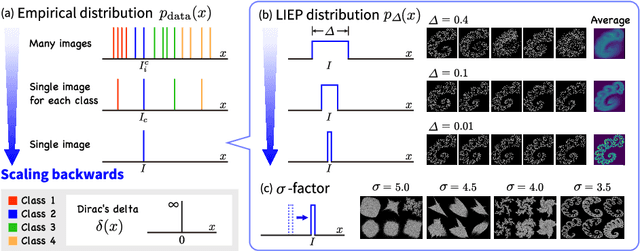
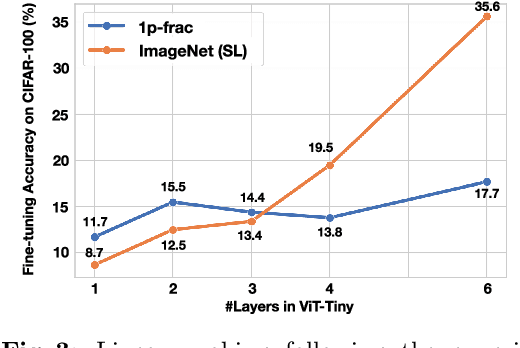

Pre-training and transfer learning are an important building block of current computer vision systems. While pre-training is usually performed on large real-world image datasets, in this paper we ask whether this is truly necessary. To this end, we search for a minimal, purely synthetic pre-training dataset that allows us to achieve performance similar to the 1 million images of ImageNet-1k. We construct such a dataset from a single fractal with perturbations. With this, we contribute three main findings. (i) We show that pre-training is effective even with minimal synthetic images, with performance on par with large-scale pre-training datasets like ImageNet-1k for full fine-tuning. (ii) We investigate the single parameter with which we construct artificial categories for our dataset. We find that while the shape differences can be indistinguishable to humans, they are crucial for obtaining strong performances. (iii) Finally, we investigate the minimal requirements for successful pre-training. Surprisingly, we find that a substantial reduction of synthetic images from 1k to 1 can even lead to an increase in pre-training performance, a motivation to further investigate ''scaling backwards''. Finally, we extend our method from synthetic images to real images to see if a single real image can show similar pre-training effect through shape augmentation. We find that the use of grayscale images and affine transformations allows even real images to ''scale backwards''.
Primitive Geometry Segment Pre-training for 3D Medical Image Segmentation
Jan 08, 2024



The construction of 3D medical image datasets presents several issues, including requiring significant financial costs in data collection and specialized expertise for annotation, as well as strict privacy concerns for patient confidentiality compared to natural image datasets. Therefore, it has become a pressing issue in 3D medical image segmentation to enable data-efficient learning with limited 3D medical data and supervision. A promising approach is pre-training, but improving its performance in 3D medical image segmentation is difficult due to the small size of existing 3D medical image datasets. We thus present the Primitive Geometry Segment Pre-training (PrimGeoSeg) method to enable the learning of 3D semantic features by pre-training segmentation tasks using only primitive geometric objects for 3D medical image segmentation. PrimGeoSeg performs more accurate and efficient 3D medical image segmentation without manual data collection and annotation. Further, experimental results show that PrimGeoSeg on SwinUNETR improves performance over learning from scratch on BTCV, MSD (Task06), and BraTS datasets by 3.7%, 4.4%, and 0.3%, respectively. Remarkably, the performance was equal to or better than state-of-the-art self-supervised learning despite the equal number of pre-training data. From experimental results, we conclude that effective pre-training can be achieved by looking at primitive geometric objects only. Code and dataset are available at https://github.com/SUPER-TADORY/PrimGeoSeg.