 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Image Super-Resolution from Training Data Perspectives
Sep 01, 2024
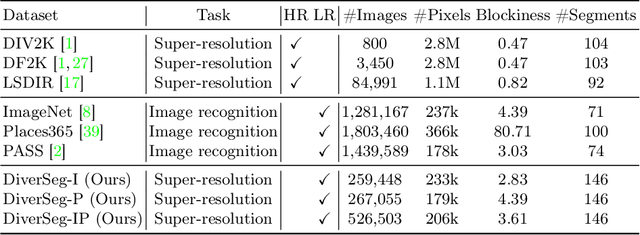

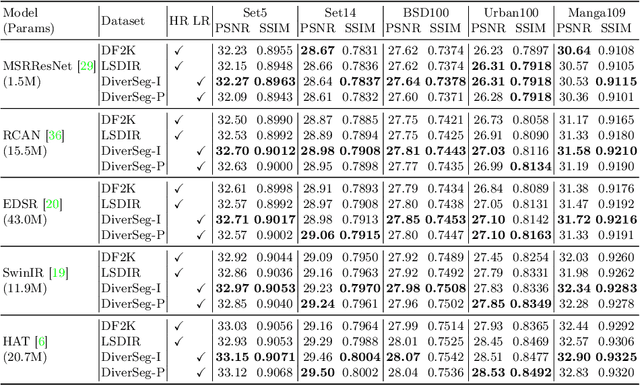
In this work, we investigate the understudied effect of the training data used for image super-resolution (SR). Most commonly, novel SR methods are developed and benchmarked on common training datasets such as DIV2K and DF2K. However, we investigate and rethink the training data from the perspectives of diversity and quality, {thereby addressing the question of ``How important is SR training for SR models?''}. To this end, we propose an automated image evaluation pipeline. With this, we stratify existing high-resolution image datasets and larger-scale image datasets such as ImageNet and PASS to compare their performances. We find that datasets with (i) low compression artifacts, (ii) high within-image diversity as judged by the number of different objects, and (iii) a large number of images from ImageNet or PASS all positively affect SR performance. We hope that the proposed simple-yet-effective dataset curation pipeline will inform the construction of SR datasets in the future and yield overall better models.
Traffic Incident Database with Multiple Labels Including Various Perspective Environmental Information
Dec 19, 2023



A large dataset of annotated traffic accidents is necessary to improve the accuracy of traffic accident recognition using deep learning models. Conventional traffic accident datasets provide annotations on traffic accidents and other teacher labels, improving traffic accident recognition performance. However, the labels annotated in conventional datasets need to be more comprehensive to describe traffic accidents in detail. Therefore, we propose V-TIDB, a large-scale traffic accident recognition dataset annotated with various environmental information as multi-labels. Our proposed dataset aims to improve the performance of traffic accident recognition by annotating ten types of environmental information as teacher labels in addition to the presence or absence of traffic accidents. V-TIDB is constructed by collecting many videos from the Internet and annotating them with appropriate environmental information. In our experiments, we compare the performance of traffic accident recognition when only labels related to the presence or absence of traffic accidents are trained and when environmental information is added as a multi-label. In the second experiment, we compare the performance of the training with only contact level, which represents the severity of the traffic accident, and the performance with environmental information added as a multi-label. The results showed that 6 out of 10 environmental information labels improved the performance of recognizing the presence or absence of traffic accidents. In the experiment on the degree of recognition of traffic accidents, the performance of recognition of car wrecks and contacts was improved for all environmental information. These experiments show that V-TIDB can be used to learn traffic accident recognition models that take environmental information into account in detail and can be used for appropriate traffic accident analysis.