 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-guided Synthetic Geometric Augmentation for Zero-shot 3D Understanding
Jan 16, 2025



Zero-shot recognition models require extensive training data for generalization. However, in zero-shot 3D classification, collecting 3D data and captions is costly and laborintensive, posing a significant barrier compared to 2D vision. Recent advances in generative models have achieved unprecedented realism in synthetic data production, and recent research shows the potential for using generated data as training data. Here, naturally raising the question: Can synthetic 3D data generated by generative models be used as expanding limited 3D datasets? In response, we present a synthetic 3D dataset expansion method, Textguided Geometric Augmentation (TeGA). TeGA is tailored for language-image-3D pretraining, which achieves SoTA in zero-shot 3D classification, and uses a generative textto-3D model to enhance and extend limited 3D datasets. Specifically, we automatically generate text-guided synthetic 3D data and introduce a consistency filtering strategy to discard noisy samples where semantics and geometric shapes do not match with text. In the experiment to double the original dataset size using TeGA, our approach demonstrates improvements over the baselines, achieving zeroshot performance gains of 3.0% on Objaverse-LVIS, 4.6% on ScanObjectNN, and 8.7% on ModelNet40. These results demonstrate that TeGA effectively bridges the 3D data gap, enabling robust zero-shot 3D classification even with limited real training data and paving the way for zero-shot 3D vision application.
Multimodal Datasets and Benchmarks for Reasoning about Dynamic Spatio-Temporality in Everyday Environments
Aug 21, 2024We used a 3D simulator to create artificial video data with standardized annotations, aiming to aid in the development of Embodied AI. Our question answering (QA) dataset measures the extent to which a robot can understand human behavior and the environment in a home setting. Preliminary experiments suggest our dataset is useful in measuring AI's comprehension of daily life. \end{abstract}
Traffic Incident Database with Multiple Labels Including Various Perspective Environmental Information
Dec 19, 2023



A large dataset of annotated traffic accidents is necessary to improve the accuracy of traffic accident recognition using deep learning models. Conventional traffic accident datasets provide annotations on traffic accidents and other teacher labels, improving traffic accident recognition performance. However, the labels annotated in conventional datasets need to be more comprehensive to describe traffic accidents in detail. Therefore, we propose V-TIDB, a large-scale traffic accident recognition dataset annotated with various environmental information as multi-labels. Our proposed dataset aims to improve the performance of traffic accident recognition by annotating ten types of environmental information as teacher labels in addition to the presence or absence of traffic accidents. V-TIDB is constructed by collecting many videos from the Internet and annotating them with appropriate environmental information. In our experiments, we compare the performance of traffic accident recognition when only labels related to the presence or absence of traffic accidents are trained and when environmental information is added as a multi-label. In the second experiment, we compare the performance of the training with only contact level, which represents the severity of the traffic accident, and the performance with environmental information added as a multi-label. The results showed that 6 out of 10 environmental information labels improved the performance of recognizing the presence or absence of traffic accidents. In the experiment on the degree of recognition of traffic accidents, the performance of recognition of car wrecks and contacts was improved for all environmental information. These experiments show that V-TIDB can be used to learn traffic accident recognition models that take environmental information into account in detail and can be used for appropriate traffic accident analysis.
Diffusion-based Holistic Texture Rectification and Synthesis
Sep 26, 2023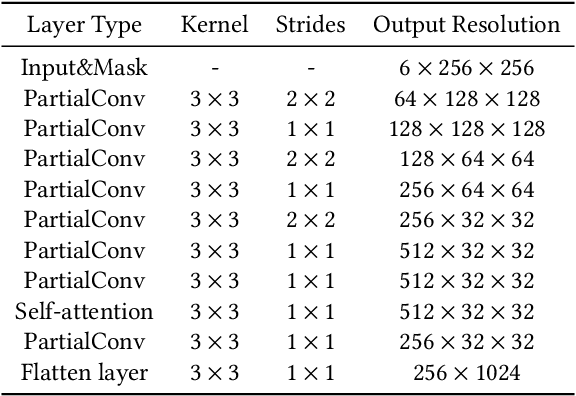
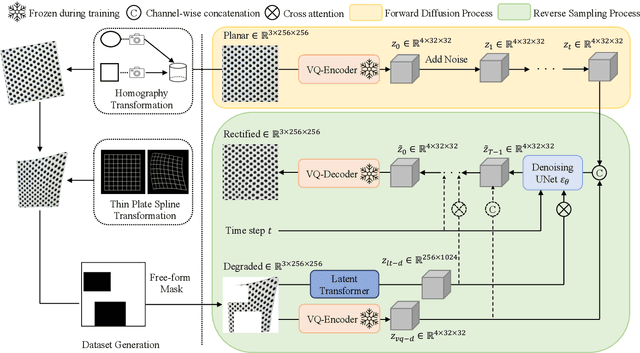
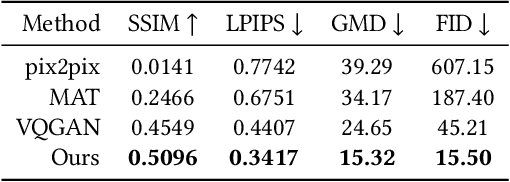

We present a novel framework for rectifying occlusions and distortions in degraded texture samples from natural images. Traditional texture synthesis approaches focus on generating textures from pristine samples, which necessitate meticulous preparation by humans and are often unattainable in most natural images. These challenges stem from the frequent occlusions and distortions of texture samples in natural images due to obstructions and variations in object surface geometry. To address these issues, we propose a framework that synthesizes holistic textures from degraded samples in natural images, extending the applicability of exemplar-based texture synthesis techniques. Our framework utilizes a conditional Latent Diffusion Model (LDM) with a novel occlusion-aware latent transformer. This latent transformer not only effectively encodes texture features from partially-observed samples necessary for the generation process of the LDM, but also explicitly captures long-range dependencies in samples with large occlusions. To train our model, we introduce a method for generating synthetic data by applying geometric transformations and free-form mask generation to clean textures. Experimental results demonstrate that our framework significantly outperforms existing methods both quantitatively and quantitatively. Furthermore, we conduct comprehensive ablation studies to validate the different components of our proposed framework. Results are corroborated by a perceptual user study which highlights the efficiency of our proposed approach.
Estimation of Human Condition at Disaster Site Using Aerial Drone Images
Aug 08, 2023

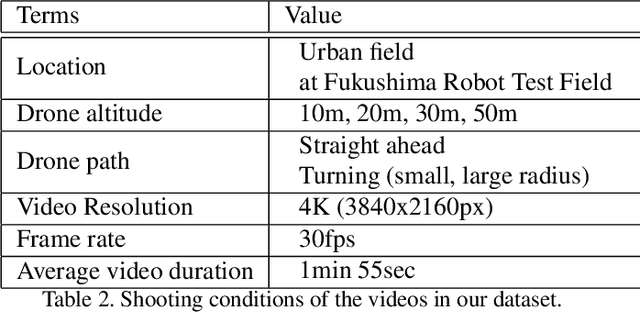
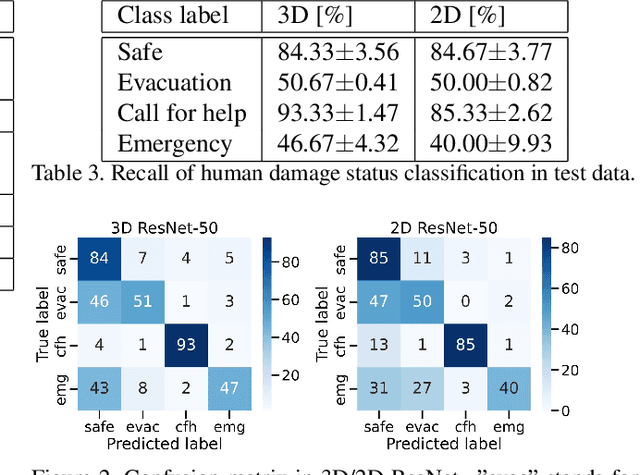
Drones are being used to assess the situation in various disasters. In this study, we investigate a method to automatically estimate the damage status of people based on their actions in aerial drone images in order to understand disaster sites faster and save labor. We constructed a new dataset of aerial images of human actions in a hypothetical disaster that occurred in an urban area, and classified the human damage status using 3D ResNet. The results showed that the status with characteristic human actions could be classified with a recall rate of more than 80%, while other statuses with similar human actions could only be classified with a recall rate of about 50%. In addition, a cloud-based VR presentation application suggested the effectiveness of using drones to understand the disaster site and estimate the human condition.
Retrieving and Highlighting Action with Spatiotemporal Reference
May 19, 2020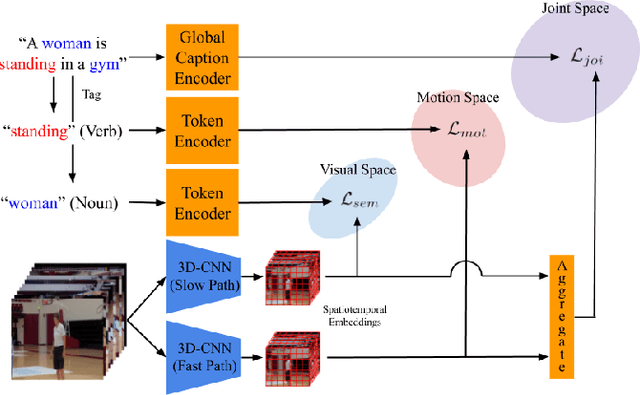
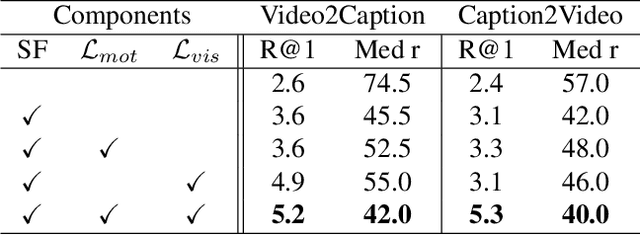
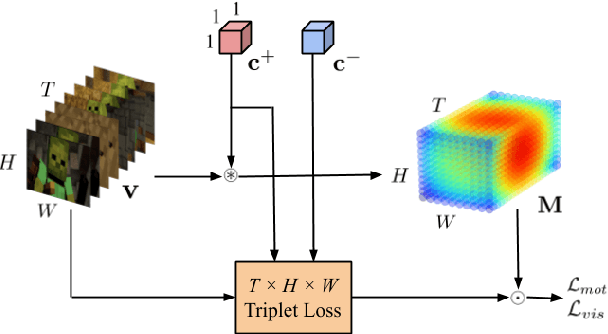

In this paper, we present a framework that jointly retrieves and spatiotemporally highlights actions in videos by enhancing current deep cross-modal retrieval methods. Our work takes on the novel task of action highlighting, which visualizes where and when actions occur in an untrimmed video setting. Action highlighting is a fine-grained task, compared to conventional action recognition tasks which focus on classification or window-based localization. Leveraging weak supervision from annotated captions, our framework acquires spatiotemporal relevance maps and generates local embeddings which relate to the nouns and verbs in captions. Through experiments, we show that our model generates various maps conditioned on different actions, in which conventional visual reasoning methods only go as far as to show a single deterministic saliency map. Also, our model improves retrieval recall over our baseline without alignment by 2-3% on the MSR-VTT dataset.
Would Mega-scale Datasets Further Enhance Spatiotemporal 3D CNNs?
Apr 10, 2020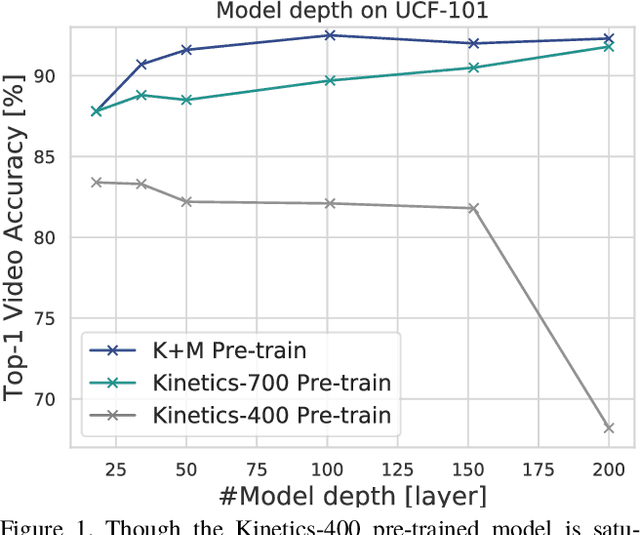
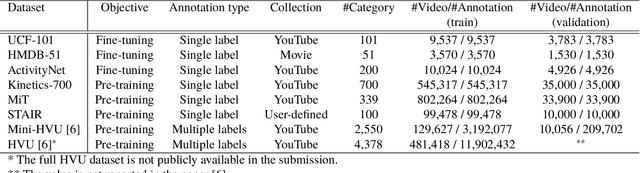
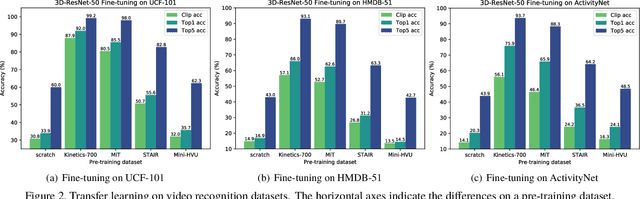
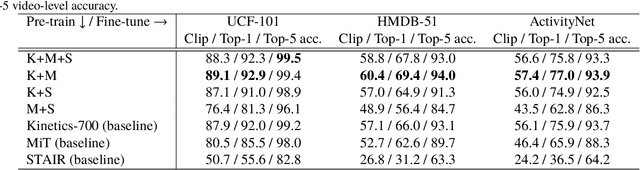
How can we collect and use a video dataset to further improve spatiotemporal 3D Convolutional Neural Networks (3D CNNs)? In order to positively answer this open question in video recognition, we have conducted an exploration study using a couple of large-scale video datasets and 3D CNNs. In the early era of deep neural networks, 2D CNNs have been better than 3D CNNs in the context of video recognition. Recent studies revealed that 3D CNNs can outperform 2D CNNs trained on a large-scale video dataset. However, we heavily rely on architecture exploration instead of dataset consideration. Therefore, in the present paper, we conduct exploration study in order to improve spatiotemporal 3D CNNs as follows: (i) Recently proposed large-scale video datasets help improve spatiotemporal 3D CNNs in terms of video classification accuracy. We reveal that a carefully annotated dataset (e.g., Kinetics-700) effectively pre-trains a video representation for a video classification task. (ii) We confirm the relationships between #category/#instance and video classification accuracy. The results show that #category should initially be fixed, and then #instance is increased on a video dataset in case of dataset construction. (iii) In order to practically extend a video dataset, we simply concatenate publicly available datasets, such as Kinetics-700 and Moments in Time (MiT) datasets. Compared with Kinetics-700 pre-training, we further enhance spatiotemporal 3D CNNs with the merged dataset, e.g., +0.9, +3.4, and +1.1 on UCF-101, HMDB-51, and ActivityNet datasets, respectively, in terms of fine-tuning. (iv) In terms of recognition architecture, the Kinetics-700 and merged dataset pre-trained models increase the recognition performance to 200 layers with the Residual Network (ResNet), while the Kinetics-400 pre-trained model cannot successfully optimize the 200-layer architecture.
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
Apr 02, 2018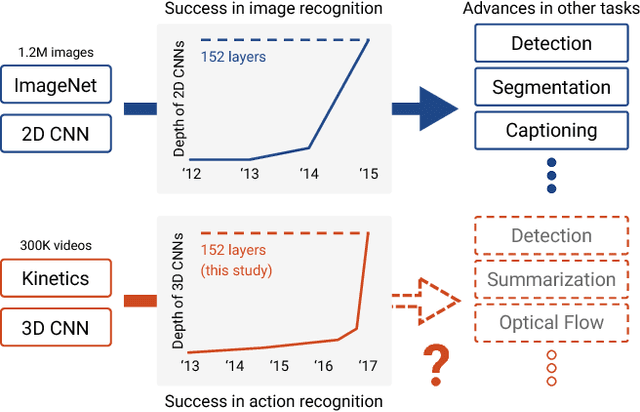
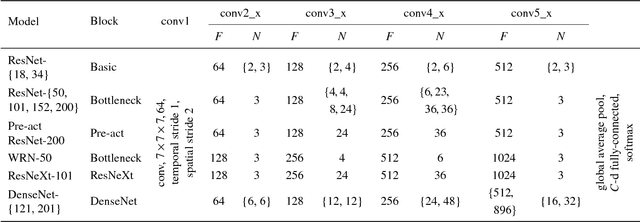

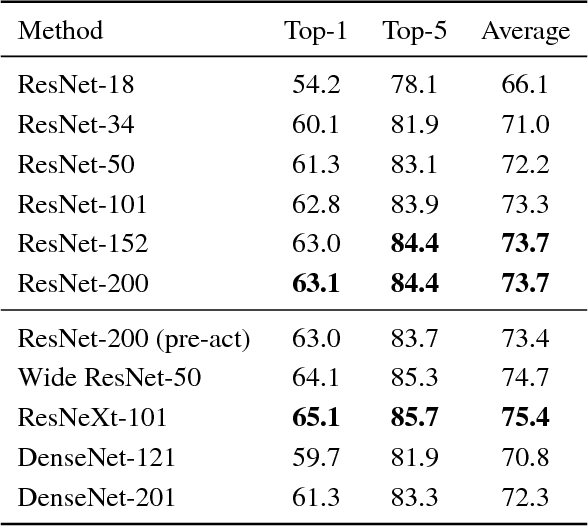
The purpose of this study is to determine whether current video datasets have sufficient data for training very deep convolutional neural networks (CNNs) with spatio-temporal three-dimensional (3D) kernels. Recently, the performance levels of 3D CNNs in the field of action recognition have improved significantly. However, to date, conventional research has only explored relatively shallow 3D architectures. We examine the architectures of various 3D CNNs from relatively shallow to very deep ones on current video datasets. Based on the results of those experiments, the following conclusions could be obtained: (i) ResNet-18 training resulted in significant overfitting for UCF-101, HMDB-51, and ActivityNet but not for Kinetics. (ii) The Kinetics dataset has sufficient data for training of deep 3D CNNs, and enables training of up to 152 ResNets layers, interestingly similar to 2D ResNets on ImageNet. ResNeXt-101 achieved 78.4% average accuracy on the Kinetics test set. (iii) Kinetics pretrained simple 3D architectures outperforms complex 2D architectures, and the pretrained ResNeXt-101 achieved 94.5% and 70.2% on UCF-101 and HMDB-51, respectively. The use of 2D CNNs trained on ImageNet has produced significant progress in various tasks in image. We believe that using deep 3D CNNs together with Kinetics will retrace the successful history of 2D CNNs and ImageNet, and stimulate advances in computer vision for videos. The codes and pretrained models used in this study are publicly available. https://github.com/kenshohara/3D-ResNets-PyTorch
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
Aug 25, 2017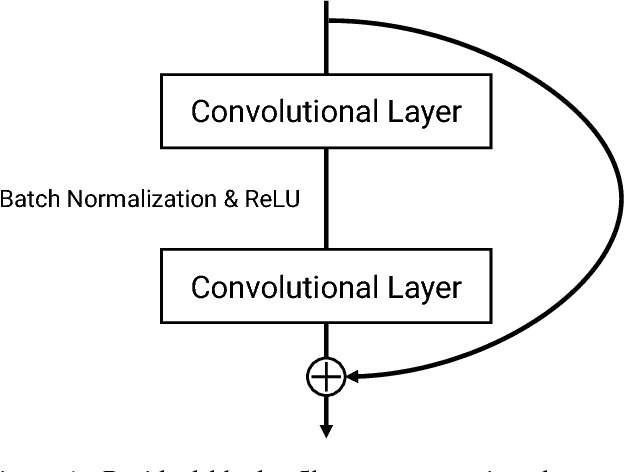
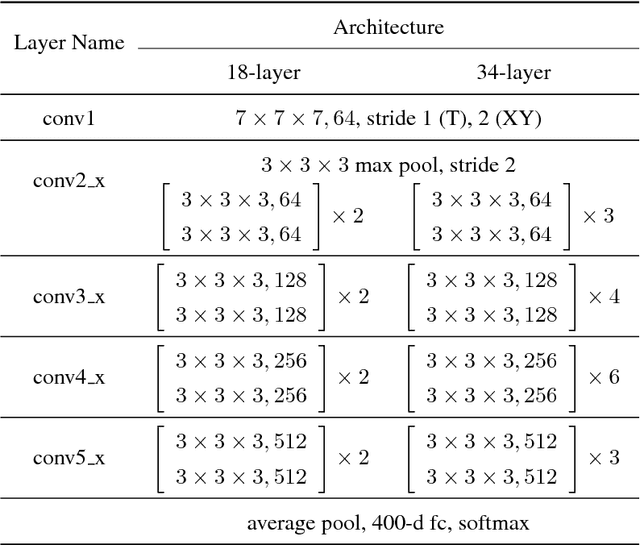
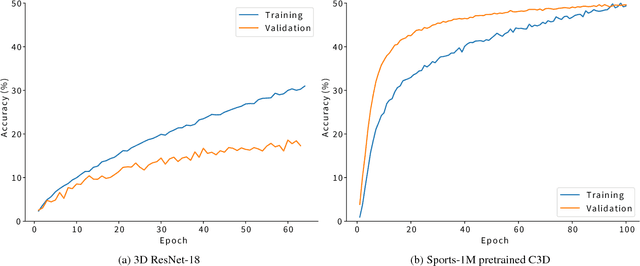
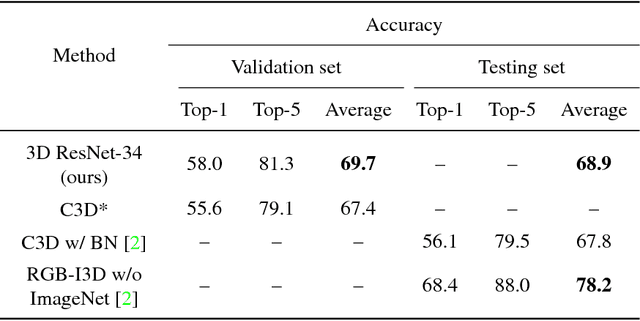
Convolutional neural networks with spatio-temporal 3D kernels (3D CNNs) have an ability to directly extract spatio-temporal features from videos for action recognition. Although the 3D kernels tend to overfit because of a large number of their parameters, the 3D CNNs are greatly improved by using recent huge video databases. However, the architecture of 3D CNNs is relatively shallow against to the success of very deep neural networks in 2D-based CNNs, such as residual networks (ResNets). In this paper, we propose a 3D CNNs based on ResNets toward a better action representation. We describe the training procedure of our 3D ResNets in details. We experimentally evaluate the 3D ResNets on the ActivityNet and Kinetics datasets. The 3D ResNets trained on the Kinetics did not suffer from overfitting despite the large number of parameters of the model, and achieved better performance than relatively shallow networks, such as C3D. Our code and pretrained models (e.g. Kinetics and ActivityNet) are publicly available at https://github.com/kenshohara/3D-ResNets.