 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for External Disturbance Factors in the Use of OCR in Real-World Environments
Apr 21, 2025The performance of OCR has improved with the evolution of AI technology. As OCR continues to broaden its range of applications, the increased likelihood of interference introduced by various usage environments can prevent it from achieving its inherent performance. This results in reduced recognition accuracy under certain conditions, and makes the quality control of recognition devices more challenging. Therefore, to ensure that users can properly utilize OCR, we compiled the real-world external disturbance factors that cause performance degradation, along with the resulting image degradation phenomena, into an external disturbance factor table and, by also indicating how to make use of it, organized them into guidelines.
Estimation of Human Condition at Disaster Site Using Aerial Drone Images
Aug 08, 2023

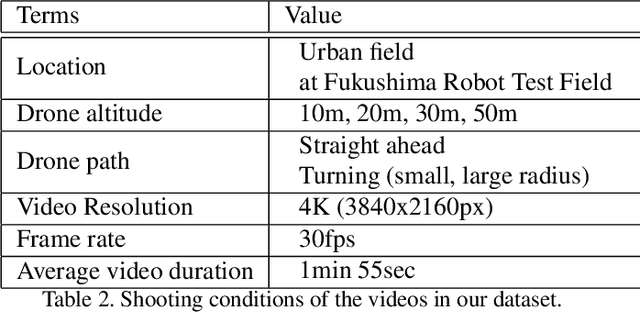
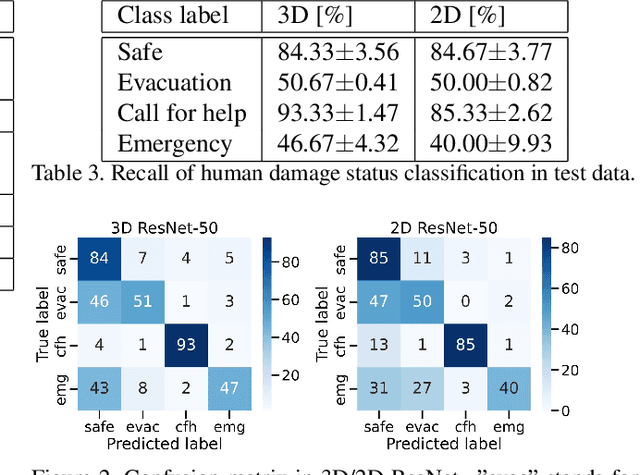
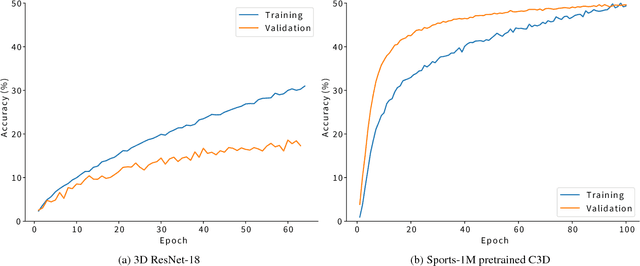
Drones are being used to assess the situation in various disasters. In this study, we investigate a method to automatically estimate the damage status of people based on their actions in aerial drone images in order to understand disaster sites faster and save labor. We constructed a new dataset of aerial images of human actions in a hypothetical disaster that occurred in an urban area, and classified the human damage status using 3D ResNet. The results showed that the status with characteristic human actions could be classified with a recall rate of more than 80%, while other statuses with similar human actions could only be classified with a recall rate of about 50%. In addition, a cloud-based VR presentation application suggested the effectiveness of using drones to understand the disaster site and estimate the human condition.
Describing and Localizing Multiple Changes with Transformers
Mar 25, 2021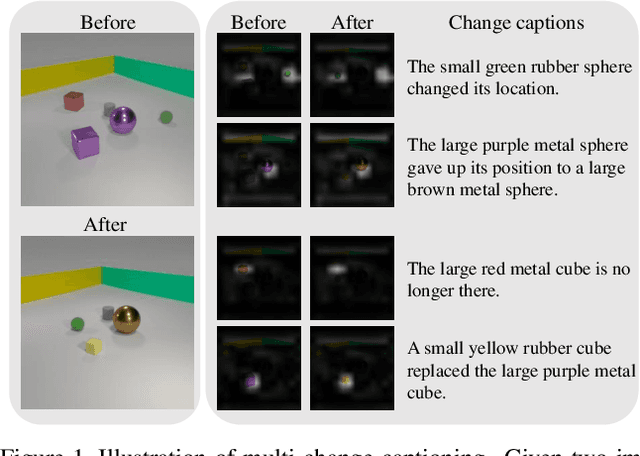
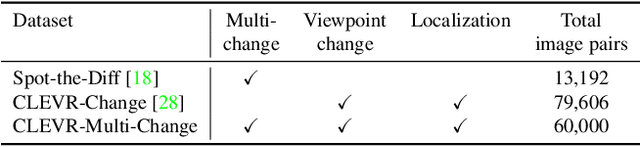


Change captioning tasks aim to detect changes in image pairs observed before and after a scene change and generate a natural language description of the changes. Existing change captioning studies have mainly focused on scenes with a single change. However, detecting and describing multiple changed parts in image pairs is essential for enhancing adaptability to complex scenarios. We solve the above issues from three aspects: (i) We propose a CG-based multi-change captioning dataset; (ii) We benchmark existing state-of-the-art methods of single change captioning on multi-change captioning; (iii) We further propose Multi-Change Captioning transformers (MCCFormers) that identify change regions by densely correlating different regions in image pairs and dynamically determines the related change regions with words in sentences. The proposed method obtained the highest scores on four conventional change captioning evaluation metrics for multi-change captioning. In addition, existing methods generate a single attention map for multiple changes and lack the ability to distinguish change regions. In contrast, our proposed method can separate attention maps for each change and performs well with respect to change localization. Moreover, the proposed framework outperformed the previous state-of-the-art methods on an existing change captioning benchmark, CLEVR-Change, by a large margin (+6.1 on BLEU-4 and +9.7 on CIDEr scores), indicating its general ability in change captioning tasks.
Pre-training without Natural Images
Jan 21, 2021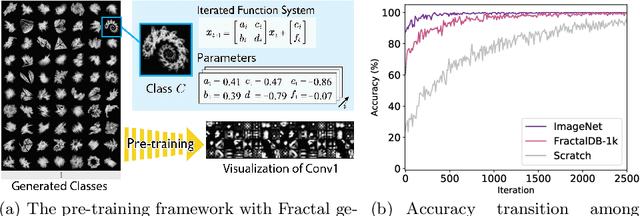
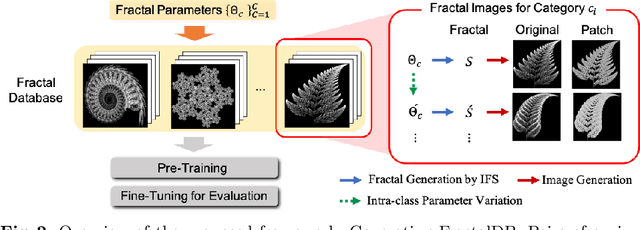

Is it possible to use convolutional neural networks pre-trained without any natural images to assist natural image understanding? The paper proposes a novel concept, Formula-driven Supervised Learning. We automatically generate image patterns and their category labels by assigning fractals, which are based on a natural law existing in the background knowledge of the real world. Theoretically, the use of automatically generated images instead of natural images in the pre-training phase allows us to generate an infinite scale dataset of labeled images. Although the models pre-trained with the proposed Fractal DataBase (FractalDB), a database without natural images, does not necessarily outperform models pre-trained with human annotated datasets at all settings, we are able to partially surpass the accuracy of ImageNet/Places pre-trained models. The image representation with the proposed FractalDB captures a unique feature in the visualization of convolutional layers and attentions.
Weakly Supervised Dataset Collection for Robust Person Detection
May 01, 2020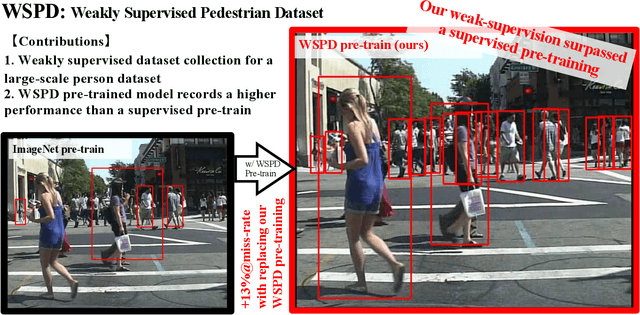
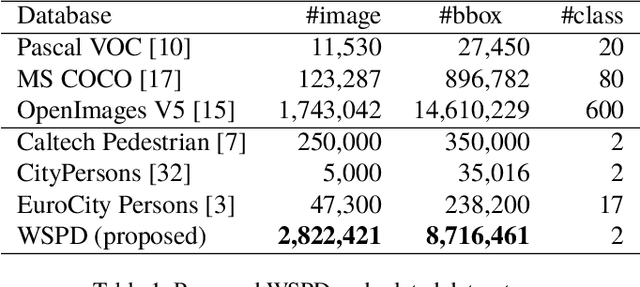
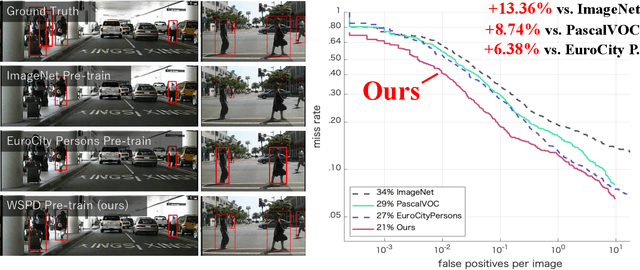

To construct an algorithm that can provide robust person detection, we present a dataset with over 8 million images that was produced in a weakly supervised manner. Through labor-intensive human annotation, the person detection research community has produced relatively small datasets containing on the order of 100,000 images, such as the EuroCity Persons dataset, which includes 240,000 bounding boxes. Therefore, we have collected 8.7 million images of persons based on a two-step collection process, namely person detection with an existing detector and data refinement for false positive suppression. According to the experimental results, the Weakly Supervised Person Dataset (WSPD) is simple yet effective for person detection pre-training. In the context of pre-trained person detection algorithms, our WSPD pre-trained model has 13.38 and 6.38% better accuracy than the same model trained on the fully supervised ImageNet and EuroCity Persons datasets, respectively, when verified with the Caltech Pedestrian.
Would Mega-scale Datasets Further Enhance Spatiotemporal 3D CNNs?
Apr 10, 2020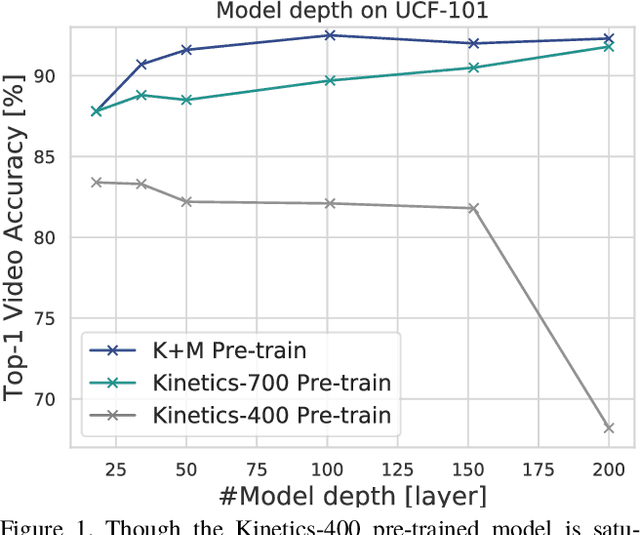
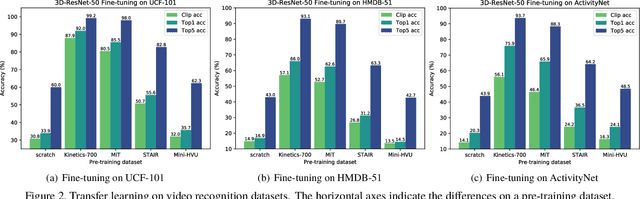
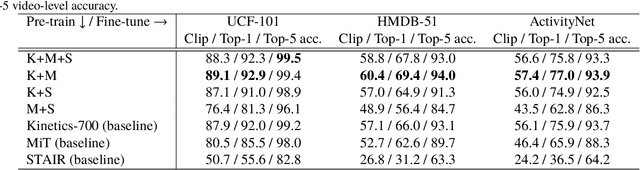
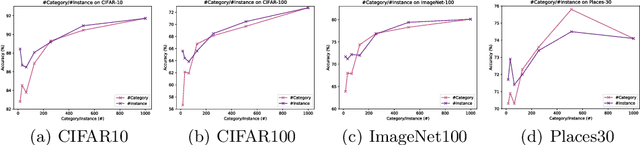
How can we collect and use a video dataset to further improve spatiotemporal 3D Convolutional Neural Networks (3D CNNs)? In order to positively answer this open question in video recognition, we have conducted an exploration study using a couple of large-scale video datasets and 3D CNNs. In the early era of deep neural networks, 2D CNNs have been better than 3D CNNs in the context of video recognition. Recent studies revealed that 3D CNNs can outperform 2D CNNs trained on a large-scale video dataset. However, we heavily rely on architecture exploration instead of dataset consideration. Therefore, in the present paper, we conduct exploration study in order to improve spatiotemporal 3D CNNs as follows: (i) Recently proposed large-scale video datasets help improve spatiotemporal 3D CNNs in terms of video classification accuracy. We reveal that a carefully annotated dataset (e.g., Kinetics-700) effectively pre-trains a video representation for a video classification task. (ii) We confirm the relationships between #category/#instance and video classification accuracy. The results show that #category should initially be fixed, and then #instance is increased on a video dataset in case of dataset construction. (iii) In order to practically extend a video dataset, we simply concatenate publicly available datasets, such as Kinetics-700 and Moments in Time (MiT) datasets. Compared with Kinetics-700 pre-training, we further enhance spatiotemporal 3D CNNs with the merged dataset, e.g., +0.9, +3.4, and +1.1 on UCF-101, HMDB-51, and ActivityNet datasets, respectively, in terms of fine-tuning. (iv) In terms of recognition architecture, the Kinetics-700 and merged dataset pre-trained models increase the recognition performance to 200 layers with the Residual Network (ResNet), while the Kinetics-400 pre-trained model cannot successfully optimize the 200-layer architecture.
Anticipating Traffic Accidents with Adaptive Loss and Large-scale Incident DB
Apr 08, 2018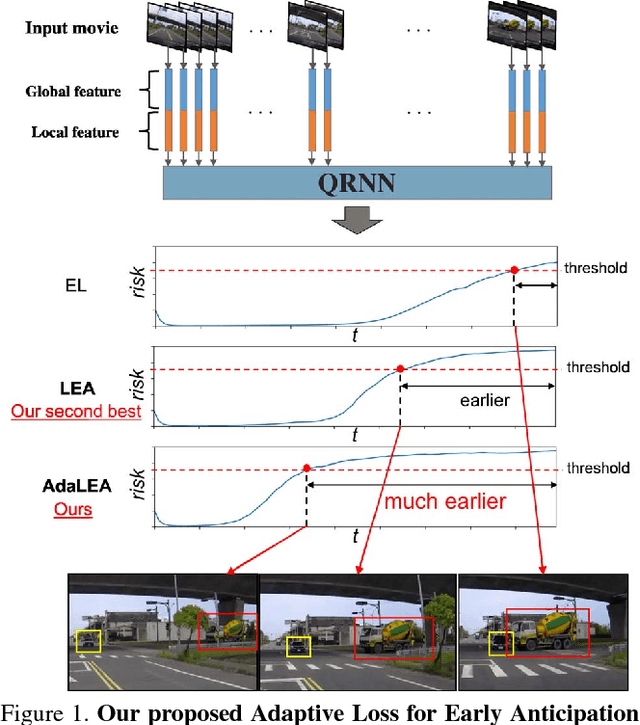


In this paper, we propose a novel approach for traffic accident anticipation through (i) Adaptive Loss for Early Anticipation (AdaLEA) and (ii) a large-scale self-annotated incident database for anticipation. The proposed AdaLEA allows a model to gradually learn an earlier anticipation as training progresses. The loss function adaptively assigns penalty weights depending on how early the model can an- ticipate a traffic accident at each epoch. Additionally, we construct a Near-miss Incident DataBase for anticipation. This database contains an enormous number of traffic near- miss incident videos and annotations for detail evaluation of two tasks, risk anticipation and risk-factor anticipation. In our experimental results, we found our proposal achieved the highest scores for risk anticipation (+6.6% better on mean average precision (mAP) and 2.36 sec earlier than previous work on the average time-to-collision (ATTC)) and risk-factor anticipation (+4.3% better on mAP and 0.70 sec earlier than previous work on ATTC).
Drive Video Analysis for the Detection of Traffic Near-Miss Incidents
Apr 07, 2018
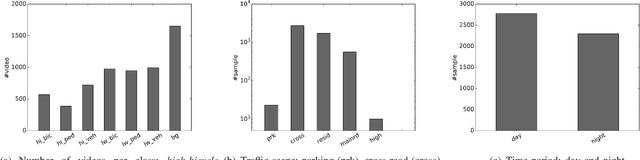
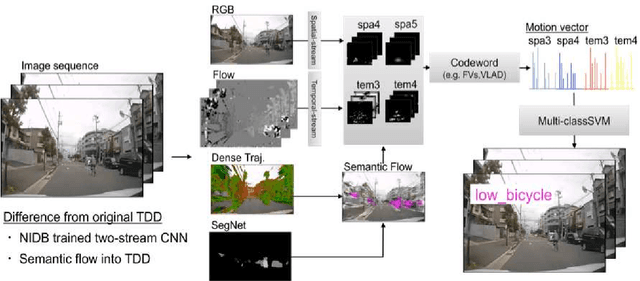

Because of their recent introduction, self-driving cars and advanced driver assistance system (ADAS) equipped vehicles have had little opportunity to learn, the dangerous traffic (including near-miss incident) scenarios that provide normal drivers with strong motivation to drive safely. Accordingly, as a means of providing learning depth, this paper presents a novel traffic database that contains information on a large number of traffic near-miss incidents that were obtained by mounting driving recorders in more than 100 taxis over the course of a decade. The study makes the following two main contributions: (i) In order to assist automated systems in detecting near-miss incidents based on database instances, we created a large-scale traffic near-miss incident database (NIDB) that consists of video clip of dangerous events captured by monocular driving recorders. (ii) To illustrate the applicability of NIDB traffic near-miss incidents, we provide two primary database-related improvements: parameter fine-tuning using various near-miss scenes from NIDB, and foreground/background separation into motion representation. Then, using our new database in conjunction with a monocular driving recorder, we developed a near-miss recognition method that provides automated systems with a performance level that is comparable to a human-level understanding of near-miss incidents (64.5% vs. 68.4% at near-miss recognition, 61.3% vs. 78.7% at near-miss detection).
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
Apr 02, 2018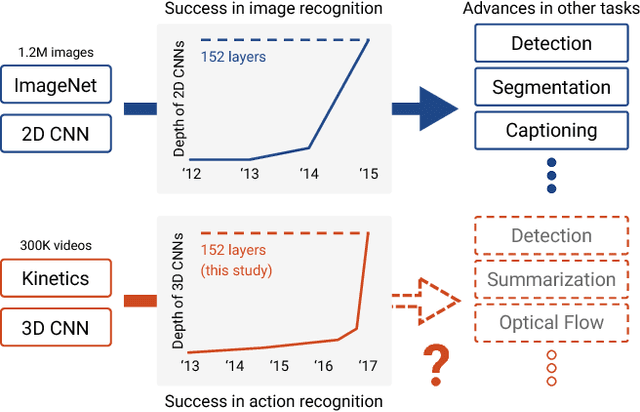
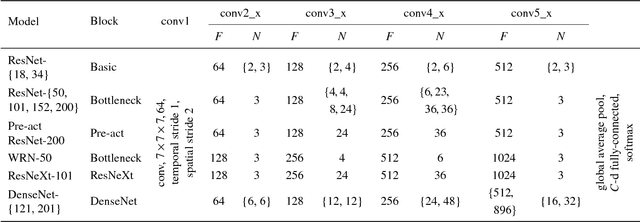

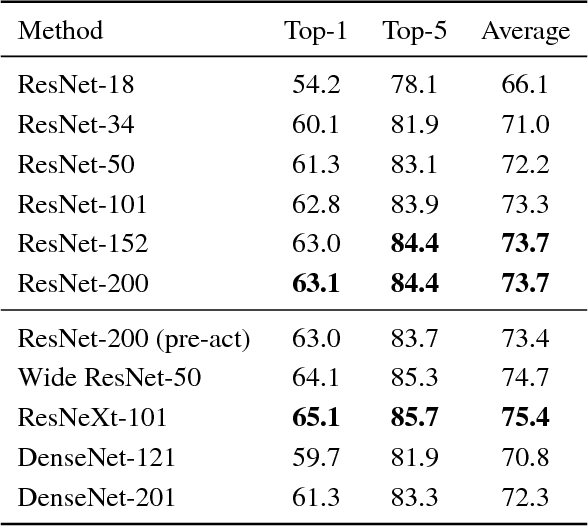
The purpose of this study is to determine whether current video datasets have sufficient data for training very deep convolutional neural networks (CNNs) with spatio-temporal three-dimensional (3D) kernels. Recently, the performance levels of 3D CNNs in the field of action recognition have improved significantly. However, to date, conventional research has only explored relatively shallow 3D architectures. We examine the architectures of various 3D CNNs from relatively shallow to very deep ones on current video datasets. Based on the results of those experiments, the following conclusions could be obtained: (i) ResNet-18 training resulted in significant overfitting for UCF-101, HMDB-51, and ActivityNet but not for Kinetics. (ii) The Kinetics dataset has sufficient data for training of deep 3D CNNs, and enables training of up to 152 ResNets layers, interestingly similar to 2D ResNets on ImageNet. ResNeXt-101 achieved 78.4% average accuracy on the Kinetics test set. (iii) Kinetics pretrained simple 3D architectures outperforms complex 2D architectures, and the pretrained ResNeXt-101 achieved 94.5% and 70.2% on UCF-101 and HMDB-51, respectively. The use of 2D CNNs trained on ImageNet has produced significant progress in various tasks in image. We believe that using deep 3D CNNs together with Kinetics will retrace the successful history of 2D CNNs and ImageNet, and stimulate advances in computer vision for videos. The codes and pretrained models used in this study are publicly available. https://github.com/kenshohara/3D-ResNets-PyTorch
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
Aug 25, 2017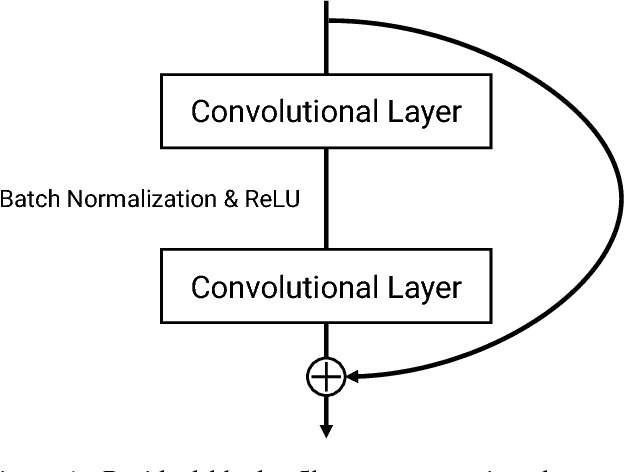
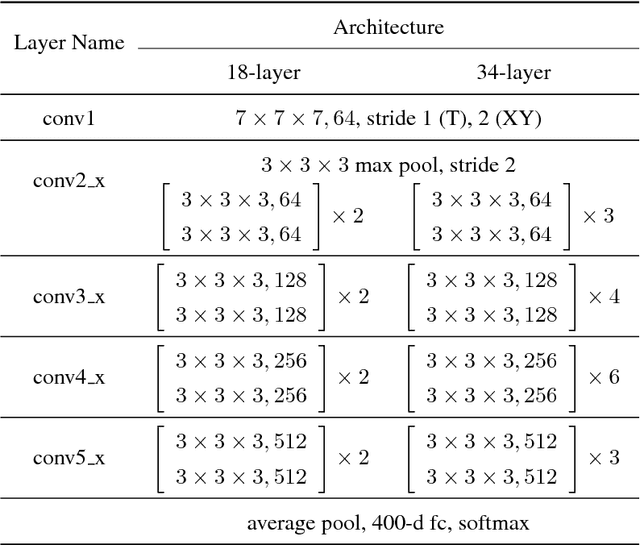
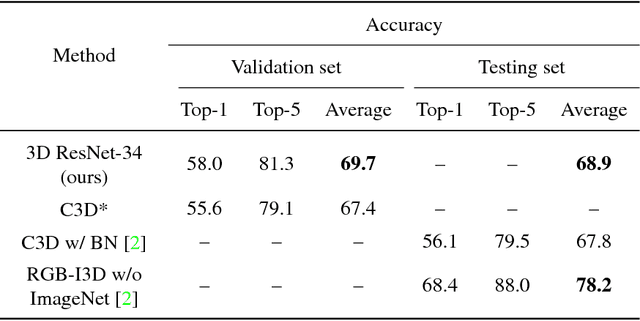
Convolutional neural networks with spatio-temporal 3D kernels (3D CNNs) have an ability to directly extract spatio-temporal features from videos for action recognition. Although the 3D kernels tend to overfit because of a large number of their parameters, the 3D CNNs are greatly improved by using recent huge video databases. However, the architecture of 3D CNNs is relatively shallow against to the success of very deep neural networks in 2D-based CNNs, such as residual networks (ResNets). In this paper, we propose a 3D CNNs based on ResNets toward a better action representation. We describe the training procedure of our 3D ResNets in details. We experimentally evaluate the 3D ResNets on the ActivityNet and Kinetics datasets. The 3D ResNets trained on the Kinetics did not suffer from overfitting despite the large number of parameters of the model, and achieved better performance than relatively shallow networks, such as C3D. Our code and pretrained models (e.g. Kinetics and ActivityNet) are publicly available at https://github.com/kenshohara/3D-ResNets.