 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoireMix: A Formula-Based Data Augmentation for Improving Image Classification Robustness
Mar 26, 2026Data augmentation is a key technique for improving the robustness of image classification models. However, many recent approaches rely on diffusion-based synthesis or complex feature mixing strategies, which introduce substantial computational overhead or require external datasets. In this work, we explore a different direction: procedural augmentation based on analytic interference patterns. Unlike conventional augmentation methods that rely on stochastic noise, feature mixing, or generative models, our approach exploits Moire interference to generate structured perturbations spanning a wide range of spatial frequencies. We propose a lightweight augmentation method that procedurally generates Moire textures on-the-fly using a closed-form mathematical formulation. The patterns are synthesized directly in memory with negligible computational cost (0.0026 seconds per image), mixed with training images during training, and immediately discarded, enabling a storage-free augmentation pipeline without external data. Extensive experiments with Vision Transformers demonstrate that the proposed method consistently improves robustness across multiple benchmarks, including ImageNet-C, ImageNet-R, and adversarial benchmarks, outperforming standard augmentation baselines and existing external-data-free augmentation approaches. These results suggest that analytic interference patterns provide a practical and efficient alternative to data-driven generative augmentation methods.
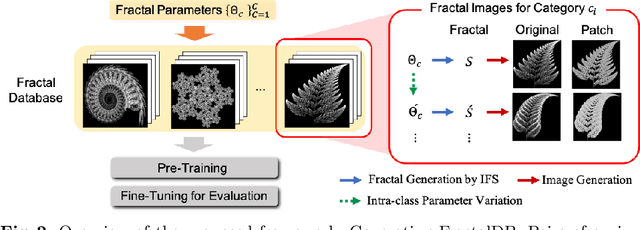
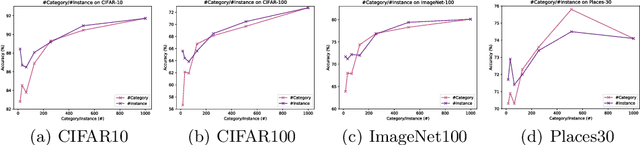
MoireDB: Formula-generated Interference-fringe Image Dataset
Feb 03, 2025Image recognition models have struggled to treat recognition robustness to real-world degradations. In this context, data augmentation methods like PixMix improve robustness but rely on generative arts and feature visualizations (FVis), which have copyright, drawing cost, and scalability issues. We propose MoireDB, a formula-generated interference-fringe image dataset for image augmentation enhancing robustness. MoireDB eliminates copyright concerns, reduces dataset assembly costs, and enhances robustness by leveraging illusory patterns. Experiments show that MoireDB augmented images outperforms traditional Fractal arts and FVis-based augmentations, making it a scalable and effective solution for improving model robustness against real-world degradations.
Pre-training without Natural Images
Jan 21, 2021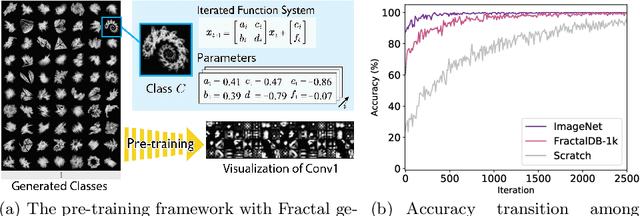

Is it possible to use convolutional neural networks pre-trained without any natural images to assist natural image understanding? The paper proposes a novel concept, Formula-driven Supervised Learning. We automatically generate image patterns and their category labels by assigning fractals, which are based on a natural law existing in the background knowledge of the real world. Theoretically, the use of automatically generated images instead of natural images in the pre-training phase allows us to generate an infinite scale dataset of labeled images. Although the models pre-trained with the proposed Fractal DataBase (FractalDB), a database without natural images, does not necessarily outperform models pre-trained with human annotated datasets at all settings, we are able to partially surpass the accuracy of ImageNet/Places pre-trained models. The image representation with the proposed FractalDB captures a unique feature in the visualization of convolutional layers and attentions.
Neural Joking Machine : Humorous image captioning
May 30, 2018

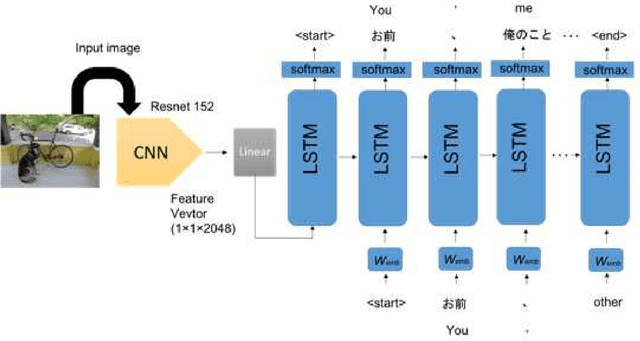

What is an effective expression that draws laughter from human beings? In the present paper, in order to consider this question from an academic standpoint, we generate an image caption that draws a "laugh" by a computer. A system that outputs funny captions based on the image caption proposed in the computer vision field is constructed. Moreover, we also propose the Funny Score, which flexibly gives weights according to an evaluation database. The Funny Score more effectively brings out "laughter" to optimize a model. In addition, we build a self-collected BoketeDB, which contains a theme (image) and funny caption (text) posted on "Bokete", which is an image Ogiri website. In an experiment, we use BoketeDB to verify the effectiveness of the proposed method by comparing the results obtained using the proposed method and those obtained using MS COCO Pre-trained CNN+LSTM, which is the baseline and idiot created by humans. We refer to the proposed method, which uses the BoketeDB pre-trained model, as the Neural Joking Machine (NJM).
Collaborative Descriptors: Convolutional Maps for Preprocessing
May 10, 2017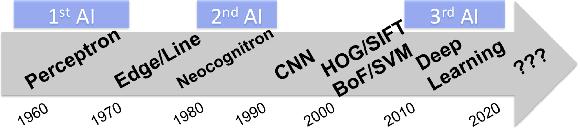


The paper presents a novel concept for collaborative descriptors between deeply learned and hand-crafted features. To achieve this concept, we apply convolutional maps for pre-processing, namely the convovlutional maps are used as input of hand-crafted features. We recorded an increase in the performance rate of +17.06 % (multi-class object recognition) and +24.71 % (car detection) from grayscale input to convolutional maps. Although the framework is straight-forward, the concept should be inherited for an improved representation.
Could you guess an interesting movie from the posters?: An evaluation of vision-based features on movie poster database
Apr 07, 2017

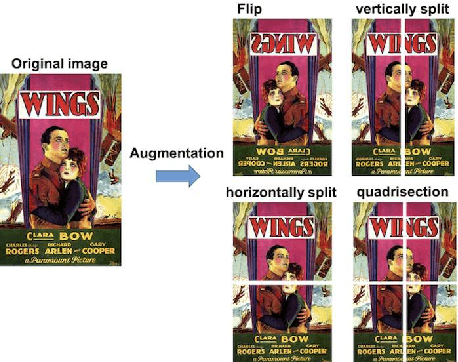
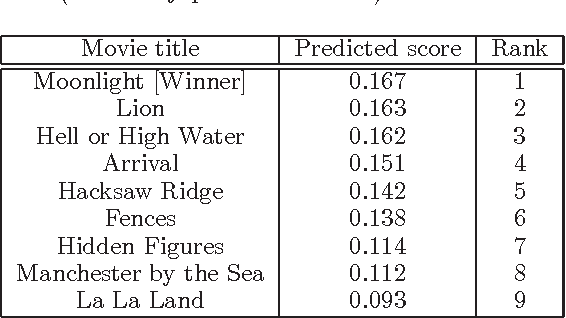
In this paper, we aim to estimate the Winner of world-wide film festival from the exhibited movie poster. The task is an extremely challenging because the estimation must be done with only an exhibited movie poster, without any film ratings and box-office takings. In order to tackle this problem, we have created a new database which is consist of all movie posters included in the four biggest film festivals. The movie poster database (MPDB) contains historic movies over 80 years which are nominated a movie award at each year. We apply a couple of feature types, namely hand-craft, mid-level and deep feature to extract various information from a movie poster. Our experiments showed suggestive knowledge, for example, the Academy award estimation can be better rate with a color feature and a facial emotion feature generally performs good rate on the MPDB. The paper may suggest a possibility of modeling human taste for a movie recommendation.
Changing Fashion Cultures
Mar 23, 2017


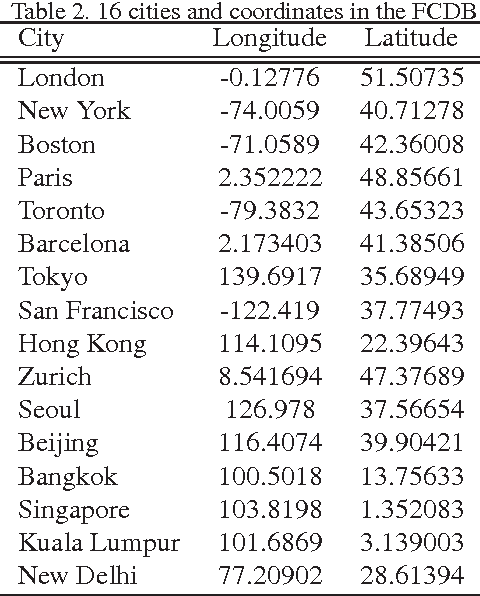
The paper presents a novel concept that analyzes and visualizes worldwide fashion trends. Our goal is to reveal cutting-edge fashion trends without displaying an ordinary fashion style. To achieve the fashion-based analysis, we created a new fashion culture database (FCDB), which consists of 76 million geo-tagged images in 16 cosmopolitan cities. By grasping a fashion trend of mixed fashion styles,the paper also proposes an unsupervised fashion trend descriptor (FTD) using a fashion descriptor, a codeword vetor, and temporal analysis. To unveil fashion trends in the FCDB, the temporal analysis in FTD effectively emphasizes consecutive features between two different times. In experiments, we clearly show the analysis of fashion trends and fashion-based city similarity. As the result of large-scale data collection and an unsupervised analyzer, the proposed approach achieves world-level fashion visualization in a time series. The code, model, and FCDB will be publicly available after the construction of the project page.
Semantic Change Detection with Hypermaps
Mar 16, 2017
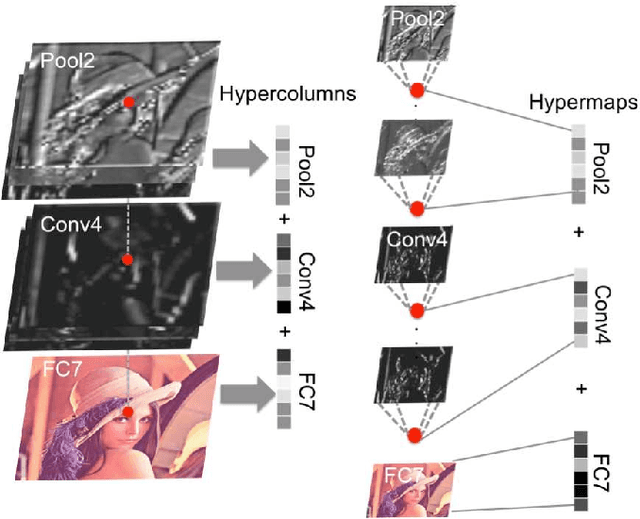

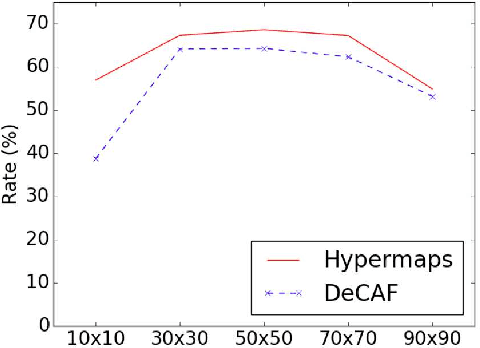
Change detection is the study of detecting changes between two different images of a scene taken at different times. By the detected change areas, however, a human cannot understand how different the two images. Therefore, a semantic understanding is required in the change detection research such as disaster investigation. The paper proposes the concept of semantic change detection, which involves intuitively inserting semantic meaning into detected change areas. We mainly focus on the novel semantic segmentation in addition to a conventional change detection approach. In order to solve this problem and obtain a high-level of performance, we propose an improvement to the hypercolumns representation, hereafter known as hypermaps, which effectively uses convolutional maps obtained from convolutional neural networks (CNNs). We also employ multi-scale feature representation captured by different image patches. We applied our method to the TSUNAMI Panoramic Change Detection dataset, and re-annotated the changed areas of the dataset via semantic classes. The results show that our multi-scale hypermaps provided outstanding performance on the re-annotated TSUNAMI dataset.
cvpaper.challenge in 2015 - A review of CVPR2015 and DeepSurvey
May 26, 2016
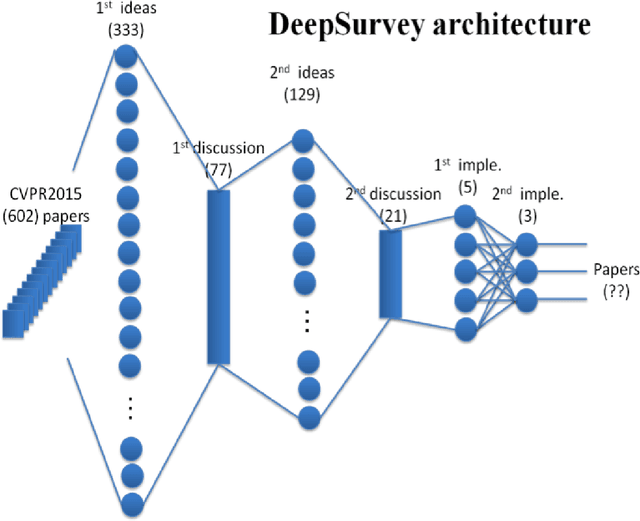
The "cvpaper.challenge" is a group composed of members from AIST, Tokyo Denki Univ. (TDU), and Univ. of Tsukuba that aims to systematically summarize papers on computer vision, pattern recognition, and related fields. For this particular review, we focused on reading the ALL 602 conference papers presented at the CVPR2015, the premier annual computer vision event held in June 2015, in order to grasp the trends in the field. Further, we are proposing "DeepSurvey" as a mechanism embodying the entire process from the reading through all the papers, the generation of ideas, and to the writing of paper.