 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecvpaper.challenge in 2016: Futuristic Computer Vision through 1,600 Papers Survey
Jul 20, 2017



The paper gives futuristic challenges disscussed in the cvpaper.challenge. In 2015 and 2016, we thoroughly study 1,600+ papers in several conferences/journals such as CVPR/ICCV/ECCV/NIPS/PAMI/IJCV.
Semantic Change Detection with Hypermaps
Mar 16, 2017
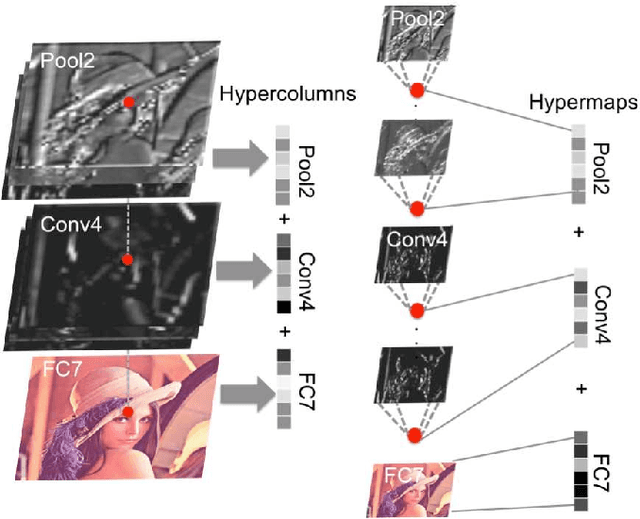

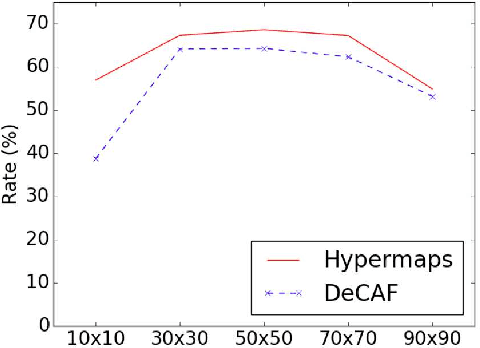
Change detection is the study of detecting changes between two different images of a scene taken at different times. By the detected change areas, however, a human cannot understand how different the two images. Therefore, a semantic understanding is required in the change detection research such as disaster investigation. The paper proposes the concept of semantic change detection, which involves intuitively inserting semantic meaning into detected change areas. We mainly focus on the novel semantic segmentation in addition to a conventional change detection approach. In order to solve this problem and obtain a high-level of performance, we propose an improvement to the hypercolumns representation, hereafter known as hypermaps, which effectively uses convolutional maps obtained from convolutional neural networks (CNNs). We also employ multi-scale feature representation captured by different image patches. We applied our method to the TSUNAMI Panoramic Change Detection dataset, and re-annotated the changed areas of the dataset via semantic classes. The results show that our multi-scale hypermaps provided outstanding performance on the re-annotated TSUNAMI dataset.
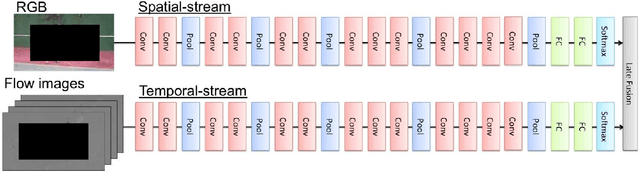
Motion Representation with Acceleration Images
Aug 30, 2016
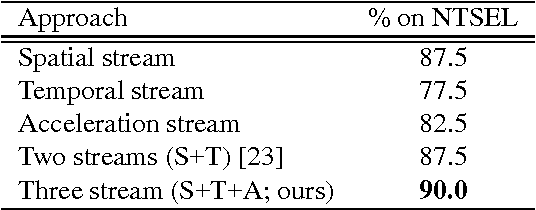

Information of time differentiation is extremely important cue for a motion representation. We have applied first-order differential velocity from a positional information, moreover we believe that second-order differential acceleration is also a significant feature in a motion representation. However, an acceleration image based on a typical optical flow includes motion noises. We have not employed the acceleration image because the noises are too strong to catch an effective motion feature in an image sequence. On one hand, the recent convolutional neural networks (CNN) are robust against input noises. In this paper, we employ acceleration-stream in addition to the spatial- and temporal-stream based on the two-stream CNN. We clearly show the effectiveness of adding the acceleration stream to the two-stream CNN.
Human Action Recognition without Human
Aug 29, 2016


The objective of this paper is to evaluate "human action recognition without human". Motion representation is frequently discussed in human action recognition. We have examined several sophisticated options, such as dense trajectories (DT) and the two-stream convolutional neural network (CNN). However, some features from the background could be too strong, as shown in some recent studies on human action recognition. Therefore, we considered whether a background sequence alone can classify human actions in current large-scale action datasets (e.g., UCF101). In this paper, we propose a novel concept for human action analysis that is named "human action recognition without human". An experiment clearly shows the effect of a background sequence for understanding an action label.
cvpaper.challenge in 2015 - A review of CVPR2015 and DeepSurvey
May 26, 2016
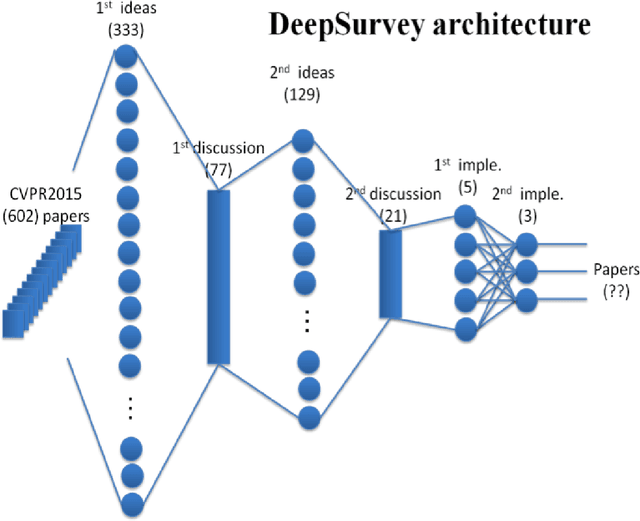
The "cvpaper.challenge" is a group composed of members from AIST, Tokyo Denki Univ. (TDU), and Univ. of Tsukuba that aims to systematically summarize papers on computer vision, pattern recognition, and related fields. For this particular review, we focused on reading the ALL 602 conference papers presented at the CVPR2015, the premier annual computer vision event held in June 2015, in order to grasp the trends in the field. Further, we are proposing "DeepSurvey" as a mechanism embodying the entire process from the reading through all the papers, the generation of ideas, and to the writing of paper.