 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouch2Insert: Zero-Shot Peg Insertion by Touching Intersections of Peg and Hole
Mar 04, 2026Reliable insertion of industrial connectors remains a central challenge in robotics, requiring sub-millimeter precision under uncertainty and often without full visual access. Vision-based approaches struggle with occlusion and limited generalization, while learning-based policies frequently fail to transfer to unseen geometries. To address these limitations, we leverage tactile sensing, which captures local surface geometry at the point of contact and thus provides reliable information even under occlusion and across novel connector shapes. Building on this capability, we present \emph{Touch2Insert}, a tactile-based framework for arbitrary peg insertion. Our method reconstructs cross-sectional geometry from high-resolution tactile images and estimates the relative pose of the hole with respect to the peg in a zero-shot manner. By aligning reconstructed shapes through registration, the framework enables insertion from a single contact without task-specific training. To evaluate its performance, we conducted experiments with three diverse connectors in both simulation and real-robot settings. The results indicate that Touch2Insert achieved sub-millimeter pose estimation accuracy for all connectors in simulation, and attained an average success rate of 86.7\% on the real robot, thereby confirming the robustness and generalizability of tactile sensing for real-world robotic connector insertion.
COG: Confidence-aware Optimal Geometric Correspondence for Unsupervised Single-reference Novel Object Pose Estimation
Feb 28, 2026Estimating the 6DoF pose of a novel object with a single reference view is challenging due to occlusions, view-point changes, and outliers. A core difficulty lies in finding robust cross-view correspondences, as existing methods often rely on discrete one-to-one matching that is non-differentiable and tends to collapse onto sparse key-points. We propose Confidence-aware Optimal Geometric Correspondence (COG), an unsupervised framework that formulates correspondence estimation as a confidence-aware optimal transport problem. COG produces balanced soft correspondences by predicting point-wise confidences and injecting them as optimal transport marginals, suppressing non-overlapping regions. Semantic priors from vision foundation models further regularize the correspondences, leading to stable pose estimation. This design integrates confidence into the correspondence finding and pose estimation pipeline, enabling unsupervised learning. Experiments show unsupervised COG achieves comparable performance to supervised methods, and supervised COG outperforms them.
FlowLoss: Dynamic Flow-Conditioned Loss Strategy for Video Diffusion Models
Apr 20, 2025Video Diffusion Models (VDMs) can generate high-quality videos, but often struggle with producing temporally coherent motion. Optical flow supervision is a promising approach to address this, with prior works commonly employing warping-based strategies that avoid explicit flow matching. In this work, we explore an alternative formulation, FlowLoss, which directly compares flow fields extracted from generated and ground-truth videos. To account for the unreliability of flow estimation under high-noise conditions in diffusion, we propose a noise-aware weighting scheme that modulates the flow loss across denoising steps. Experiments on robotic video datasets suggest that FlowLoss improves motion stability and accelerates convergence in early training stages. Our findings offer practical insights for incorporating motion-based supervision into noise-conditioned generative models.
Modality Selection and Skill Segmentation via Cross-Modality Attention
Apr 20, 2025
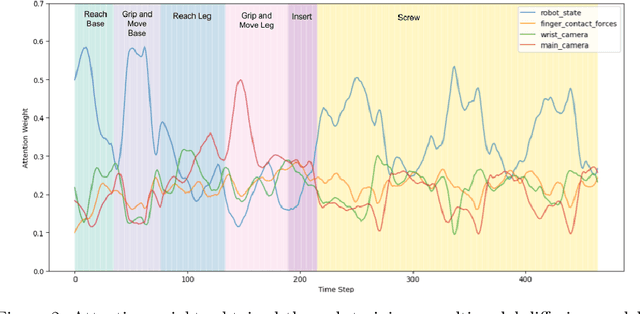


Incorporating additional sensory modalities such as tactile and audio into foundational robotic models poses significant challenges due to the curse of dimensionality. This work addresses this issue through modality selection. We propose a cross-modality attention (CMA) mechanism to identify and selectively utilize the modalities that are most informative for action generation at each timestep. Furthermore, we extend the application of CMA to segment primitive skills from expert demonstrations and leverage this segmentation to train a hierarchical policy capable of solving long-horizon, contact-rich manipulation tasks.
Zero-Shot Peg Insertion: Identifying Mating Holes and Estimating SE(2) Poses with Vision-Language Models
Mar 08, 2025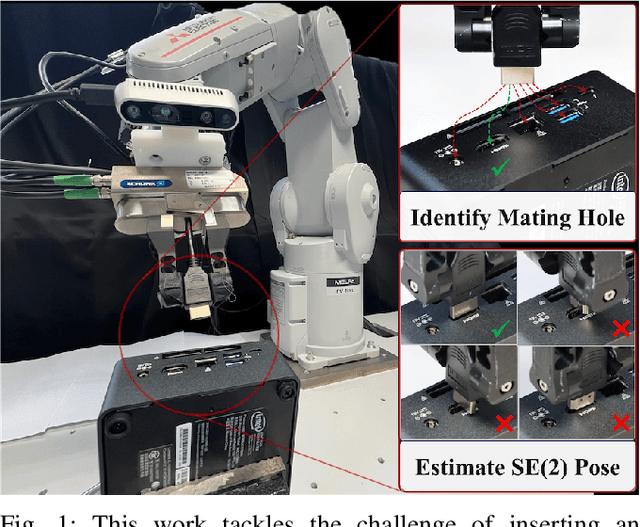
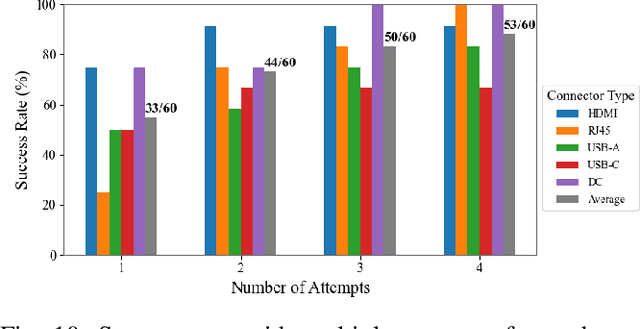
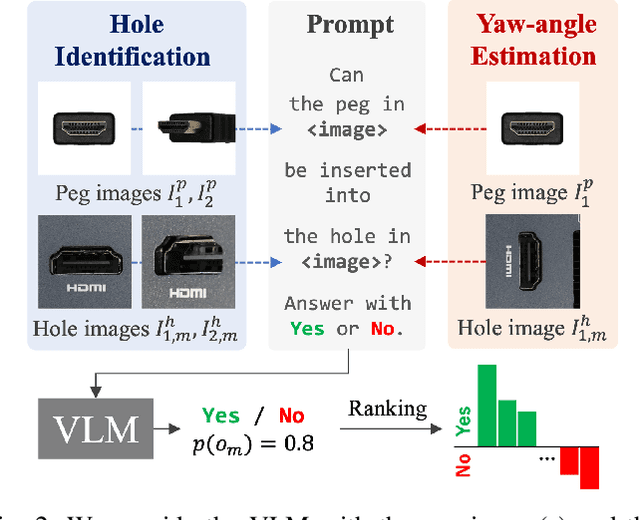
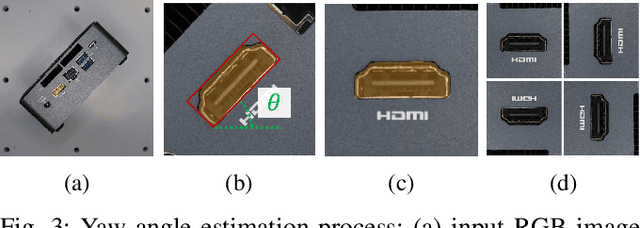
Achieving zero-shot peg insertion, where inserting an arbitrary peg into an unseen hole without task-specific training, remains a fundamental challenge in robotics. This task demands a highly generalizable perception system capable of detecting potential holes, selecting the correct mating hole from multiple candidates, estimating its precise pose, and executing insertion despite uncertainties. While learning-based methods have been applied to peg insertion, they often fail to generalize beyond the specific peg-hole pairs encountered during training. Recent advancements in Vision-Language Models (VLMs) offer a promising alternative, leveraging large-scale datasets to enable robust generalization across diverse tasks. Inspired by their success, we introduce a novel zero-shot peg insertion framework that utilizes a VLM to identify mating holes and estimate their poses without prior knowledge of their geometry. Extensive experiments demonstrate that our method achieves 90.2% accuracy, significantly outperforming baselines in identifying the correct mating hole across a wide range of previously unseen peg-hole pairs, including 3D-printed objects, toy puzzles, and industrial connectors. Furthermore, we validate the effectiveness of our approach in a real-world connector insertion task on a backpanel of a PC, where our system successfully detects holes, identifies the correct mating hole, estimates its pose, and completes the insertion with a success rate of 88.3%. These results highlight the potential of VLM-driven zero-shot reasoning for enabling robust and generalizable robotic assembly.
OP-Align: Object-level and Part-level Alignment for Self-supervised Category-level Articulated Object Pose Estimation
Aug 29, 2024


Category-level articulated object pose estimation focuses on the pose estimation of unknown articulated objects within known categories. Despite its significance, this task remains challenging due to the varying shapes and poses of objects, expensive dataset annotation costs, and complex real-world environments. In this paper, we propose a novel self-supervised approach that leverages a single-frame point cloud to solve this task. Our model consistently generates reconstruction with a canonical pose and joint state for the entire input object, and it estimates object-level poses that reduce overall pose variance and part-level poses that align each part of the input with its corresponding part of the reconstruction. Experimental results demonstrate that our approach significantly outperforms previous self-supervised methods and is comparable to the state-of-the-art supervised methods. To assess the performance of our model in real-world scenarios, we also introduce a new real-world articulated object benchmark dataset.
Zero-shot Degree of Ill-posedness Estimation for Active Small Object Change Detection
May 10, 2024In everyday indoor navigation, robots often needto detect non-distinctive small-change objects (e.g., stationery,lost items, and junk, etc.) to maintain domain knowledge. Thisis most relevant to ground-view change detection (GVCD), a recently emerging research area in the field of computer vision.However, these existing techniques rely on high-quality class-specific object priors to regularize a change detector modelthat cannot be applied to semantically nondistinctive smallobjects. To address ill-posedness, in this study, we explorethe concept of degree-of-ill-posedness (DoI) from the newperspective of GVCD, aiming to improve both passive and activevision. This novel DoI problem is highly domain-dependent,and manually collecting fine-grained annotated training datais expensive. To regularize this problem, we apply the conceptof self-supervised learning to achieve efficient DoI estimationscheme and investigate its generalization to diverse datasets.Specifically, we tackle the challenging issue of obtaining self-supervision cues for semantically non-distinctive unseen smallobjects and show that novel "oversegmentation cues" from openvocabulary semantic segmentation can be effectively exploited.When applied to diverse real datasets, the proposed DoI modelcan boost state-of-the-art change detection models, and it showsstable and consistent improvements when evaluated on real-world datasets.
Leveraging Large Language Model-based Room-Object Relationships Knowledge for Enhancing Multimodal-Input Object Goal Navigation
Mar 21, 2024Object-goal navigation is a crucial engineering task for the community of embodied navigation; it involves navigating to an instance of a specified object category within unseen environments. Although extensive investigations have been conducted on both end-to-end and modular-based, data-driven approaches, fully enabling an agent to comprehend the environment through perceptual knowledge and perform object-goal navigation as efficiently as humans remains a significant challenge. Recently, large language models have shown potential in this task, thanks to their powerful capabilities for knowledge extraction and integration. In this study, we propose a data-driven, modular-based approach, trained on a dataset that incorporates common-sense knowledge of object-to-room relationships extracted from a large language model. We utilize the multi-channel Swin-Unet architecture to conduct multi-task learning incorporating with multimodal inputs. The results in the Habitat simulator demonstrate that our framework outperforms the baseline by an average of 10.6% in the efficiency metric, Success weighted by Path Length (SPL). The real-world demonstration shows that the proposed approach can efficiently conduct this task by traversing several rooms. For more details and real-world demonstrations, please check our project webpage (https://sunleyuan.github.io/ObjectNav).
Linking Vision and Multi-Agent Communication through Visible Light Communication using Event Cameras
Feb 15, 2024Various robots, rovers, drones, and other agents of mass-produced products are expected to encounter scenes where they intersect and collaborate in the near future. In such multi-agent systems, individual identification and communication play crucial roles. In this paper, we explore camera-based visible light communication using event cameras to tackle this problem. An event camera captures the events occurring in regions with changes in brightness and can be utilized as a receiver for visible light communication, leveraging its high temporal resolution. Generally, agents with identical appearances in mass-produced products are visually indistinguishable when using conventional CMOS cameras. Therefore, linking visual information with information acquired through conventional radio communication is challenging. We empirically demonstrate the advantages of a visible light communication system employing event cameras and LEDs for visual individual identification over conventional CMOS cameras with ArUco marker recognition. In the simulation, we also verified scenarios where our event camera-based visible light communication outperforms conventional radio communication in situations with visually indistinguishable multi-agents. Finally, our newly implemented multi-agent system verifies its functionality through physical robot experiments.
Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification
Nov 04, 2023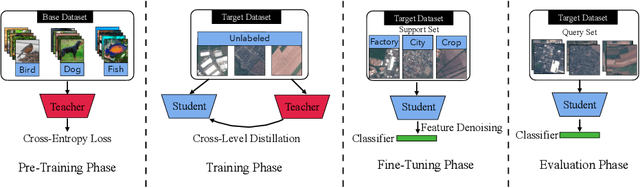
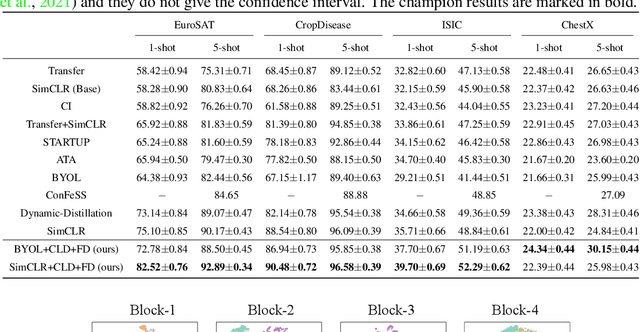
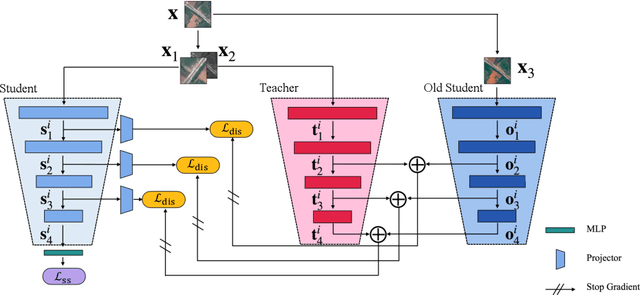

The conventional few-shot classification aims at learning a model on a large labeled base dataset and rapidly adapting to a target dataset that is from the same distribution as the base dataset. However, in practice, the base and the target datasets of few-shot classification are usually from different domains, which is the problem of cross-domain few-shot classification. We tackle this problem by making a small proportion of unlabeled images in the target domain accessible in the training stage. In this setup, even though the base data are sufficient and labeled, the large domain shift still makes transferring the knowledge from the base dataset difficult. We meticulously design a cross-level knowledge distillation method, which can strengthen the ability of the model to extract more discriminative features in the target dataset by guiding the network's shallow layers to learn higher-level information. Furthermore, in order to alleviate the overfitting in the evaluation stage, we propose a feature denoising operation which can reduce the feature redundancy and mitigate overfitting. Our approach can surpass the previous state-of-the-art method, Dynamic-Distillation, by 5.44% on 1-shot and 1.37% on 5-shot classification tasks on average in the BSCD-FSL benchmark. The implementation code will be available at https://github.com/jarucezh/cldfd.