 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOP-Align: Object-level and Part-level Alignment for Self-supervised Category-level Articulated Object Pose Estimation
Aug 29, 2024


Category-level articulated object pose estimation focuses on the pose estimation of unknown articulated objects within known categories. Despite its significance, this task remains challenging due to the varying shapes and poses of objects, expensive dataset annotation costs, and complex real-world environments. In this paper, we propose a novel self-supervised approach that leverages a single-frame point cloud to solve this task. Our model consistently generates reconstruction with a canonical pose and joint state for the entire input object, and it estimates object-level poses that reduce overall pose variance and part-level poses that align each part of the input with its corresponding part of the reconstruction. Experimental results demonstrate that our approach significantly outperforms previous self-supervised methods and is comparable to the state-of-the-art supervised methods. To assess the performance of our model in real-world scenarios, we also introduce a new real-world articulated object benchmark dataset.
Optimizing Implicit Neural Representations from Point Clouds via Energy-Based Models
Nov 05, 2023Reconstructing a continuous surface from an unoritented 3D point cloud is a fundamental task in 3D shape processing. In recent years, several methods have been proposed to address this problem using implicit neural representations (INRs). In this study, we propose a method to optimize INRs using energy-based models (EBMs). By employing the absolute value of the coordinate-based neural networks as the energy function, the INR can be optimized through the estimation of the point cloud distribution by the EBM. In addition, appropriate parameter settings of the EBM enable the model to consider the magnitude of point cloud noise. Our experiments confirmed that the proposed method is more robust against point cloud noise than conventional surface reconstruction methods.
Generalization of pixel-wise phase estimation by CNN and improvement of phase-unwrapping by MRF optimization for one-shot 3D scan
Sep 26, 2023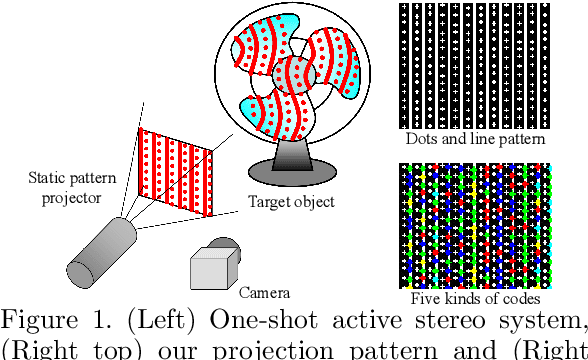

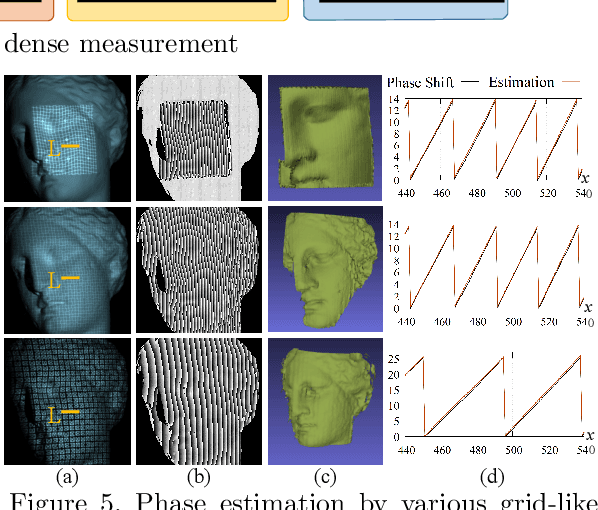
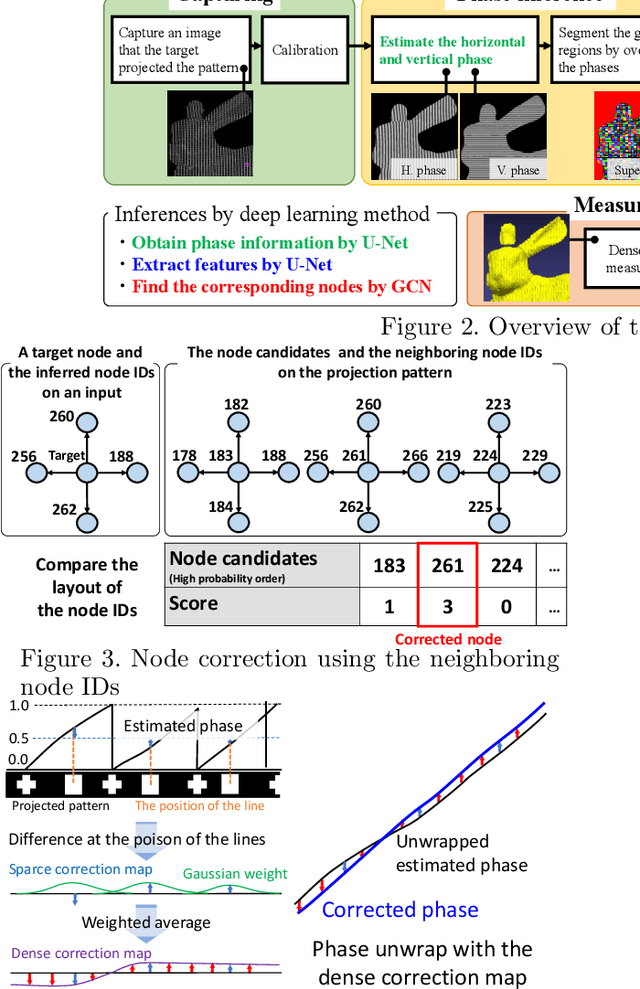
Active stereo technique using single pattern projection, a.k.a. one-shot 3D scan, have drawn a wide attention from industry, medical purposes, etc. One severe drawback of one-shot 3D scan is sparse reconstruction. In addition, since spatial pattern becomes complicated for the purpose of efficient embedding, it is easily affected by noise, which results in unstable decoding. To solve the problems, we propose a pixel-wise interpolation technique for one-shot scan, which is applicable to any types of static pattern if the pattern is regular and periodic. This is achieved by U-net which is pre-trained by CG with efficient data augmentation algorithm. In the paper, to further overcome the decoding instability, we propose a robust correspondence finding algorithm based on Markov random field (MRF) optimization. We also propose a shape refinement algorithm based on b-spline and Gaussian kernel interpolation using explicitly detected laser curves. Experiments are conducted to show the effectiveness of the proposed method using real data with strong noises and textures.
Heterogeneous Domain Adaptation with Positive and Unlabeled Data
Apr 17, 2023Heterogeneous unsupervised domain adaptation (HUDA) is the most challenging domain adaptation setting where the feature space differs between source and target domains, and the target domain has only unlabeled data. Existing HUDA methods assume that both positive and negative examples are available in the source domain, which may not be satisfied in some real applications. This paper addresses a new challenging setting called positive and unlabeled heterogeneous domain adaptation (PU-HDA), a HUDA setting where the source domain only has positives. PU-HDA can also be viewed as an extension of PU learning where the positive and unlabeled examples are sampled from different domains. A naive combination of existing HUDA and PU learning methods is ineffective in PU-HDA due to the gap in label distribution between the source and target domains. To overcome this issue, we propose a novel method, positive-adversarial domain adaptation (PADA), which can predict likely positive examples from the unlabeled target data and simultaneously align the feature spaces to reduce the distribution divergence between the whole source data and the likely positive target data. PADA achieves this by a unified adversarial training framework for learning a classifier to predict positive examples and a feature transformer to transform the target feature space to that of the source. Specifically, they are both trained to fool a common discriminator that determines whether the likely positive examples are from the target or source domain. We experimentally show that PADA outperforms several baseline methods, such as the naive combination of HUDA and PU learning.
Continual Horizontal Federated Learning for Heterogeneous Data
Mar 04, 2022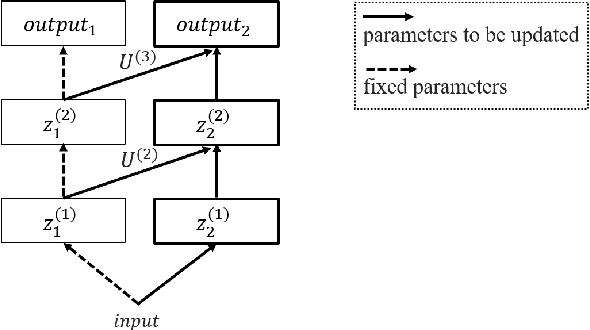

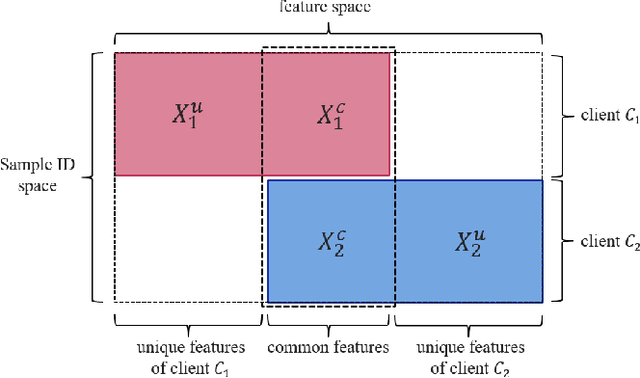
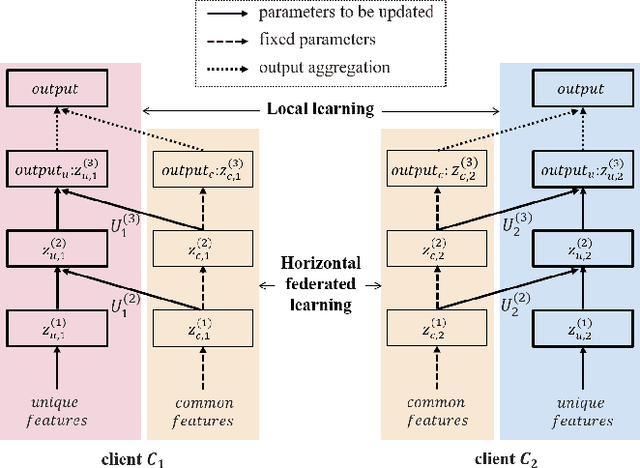
Federated learning is a promising machine learning technique that enables multiple clients to collaboratively build a model without revealing the raw data to each other. Among various types of federated learning methods, horizontal federated learning (HFL) is the best-studied category and handles homogeneous feature spaces. However, in the case of heterogeneous feature spaces, HFL uses only common features and leaves client-specific features unutilized. In this paper, we propose a HFL method using neural networks named continual horizontal federated learning (CHFL), a continual learning approach to improve the performance of HFL by taking advantage of unique features of each client. CHFL splits the network into two columns corresponding to common features and unique features, respectively. It jointly trains the first column by using common features through vanilla HFL and locally trains the second column by using unique features and leveraging the knowledge of the first one via lateral connections without interfering with the federated training of it. We conduct experiments on various real world datasets and show that CHFL greatly outperforms vanilla HFL that only uses common features and local learning that uses all features that each client has.
A Method For Adding Motion-Blur on Arbitrary Objects By using Auto-Segmentation and Color Compensation Techniques
Sep 22, 2021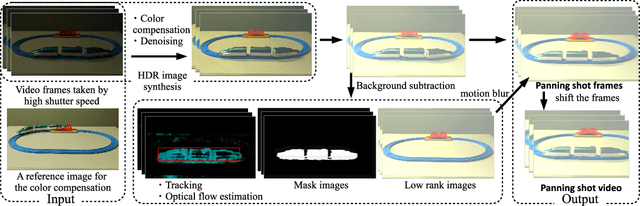
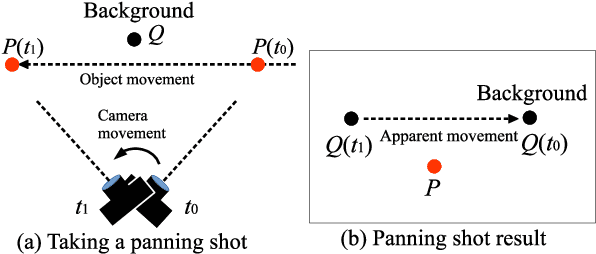


When dynamic objects are captured by a camera, motion blur inevitably occurs. Such a blur is sometimes considered as just a noise, however, it sometimes gives an important effect to add dynamism in the scene for photographs or videos. Unlike the similar effects, such as defocus blur, which is now easily controlled even by smartphones, motion blur is still uncontrollable and makes undesired effects on photographs. In this paper, an unified framework to add motion blur on per-object basis is proposed. In the method, multiple frames are captured without motion blur and they are accumulated to create motion blur on target objects. To capture images without motion blur, shutter speed must be short, however, it makes captured images dark, and thus, a sensor gain should be increased to compensate it. Since a sensor gain causes a severe noise on image, we propose a color compensation algorithm based on non-linear filtering technique for solution. Another contribution is that our technique can be used to make HDR images for fast moving objects by using multi-exposure images. In the experiments, effectiveness of the method is confirmed by ablation study using several data sets.
* This paper was accepted at ICIP 2021
Dense Pixel-wise Micro-motion Estimation of Object Surface by using Low Dimensional Embedding of Laser Speckle Pattern
Oct 31, 2020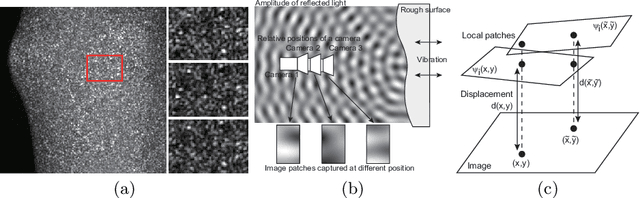
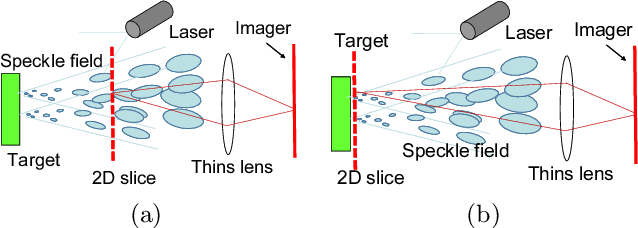


This paper proposes a method of estimating micro-motion of an object at each pixel that is too small to detect under a common setup of camera and illumination. The method introduces an active-lighting approach to make the motion visually detectable. The approach is based on speckle pattern, which is produced by the mutual interference of laser light on object's surface and continuously changes its appearance according to the out-of-plane motion of the surface. In addition, speckle pattern becomes uncorrelated with large motion. To compensate such micro- and large motion, the method estimates the motion parameters up to scale at each pixel by nonlinear embedding of the speckle pattern into low-dimensional space. The out-of-plane motion is calculated by making the motion parameters spatially consistent across the image. In the experiments, the proposed method is compared with other measuring devices to prove the effectiveness of the method.
CNN based dense underwater 3D scene reconstruction by transfer learning using bubble database
Nov 21, 2018

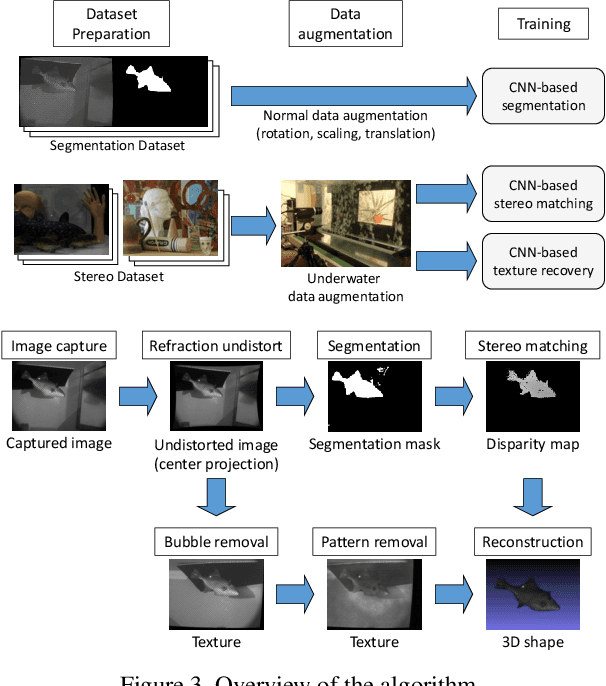

Dense 3D shape acquisition of swimming human or live fish is an important research topic for sports, biological science and so on. For this purpose, active stereo sensor is usually used in the air, however it cannot be applied to the underwater environment because of refraction, strong light attenuation and severe interference of bubbles. Passive stereo is a simple solution for capturing dynamic scenes at underwater environment, however the shape with textureless surfaces or irregular reflections cannot be recovered. Recently, the stereo camera pair with a pattern projector for adding artificial textures on the objects is proposed. However, to use the system for underwater environment, several problems should be compensated, i.e., disturbance by fluctuation and bubbles. Simple solution is to use convolutional neural network for stereo to cancel the effects of bubbles and/or water fluctuation. Since it is not easy to train CNN with small size of database with large variation, we develop a special bubble generation device to efficiently create real bubble database of multiple size and density. In addition, we propose a transfer learning technique for multi-scale CNN to effectively remove bubbles and projected-patterns on the object. Further, we develop a real system and actually captured live swimming human, which has not been done before. Experiments are conducted to show the effectiveness of our method compared with the state of the art techniques.
Multi-scale CNN stereo and pattern removal technique for underwater active stereo system
Aug 25, 2018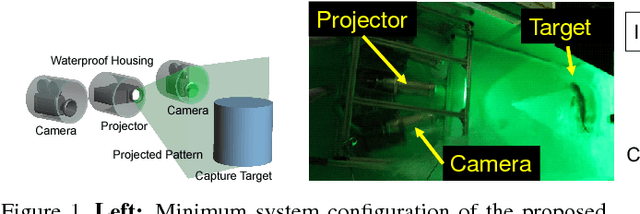
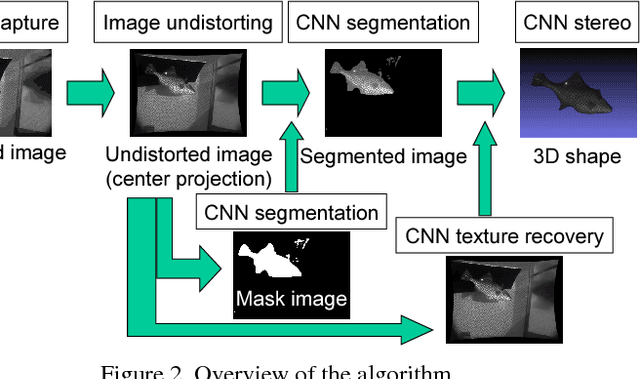
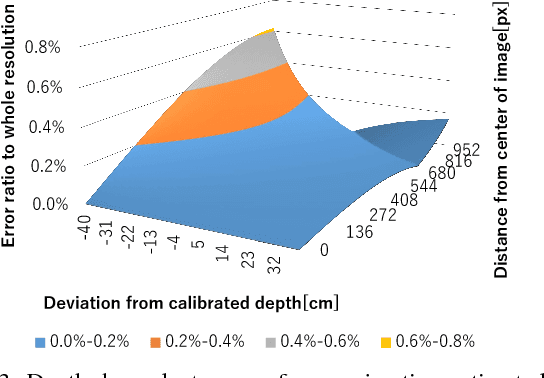

Demands on capturing dynamic scenes of underwater environments are rapidly growing. Passive stereo is applicable to capture dynamic scenes, however the shape with textureless surfaces or irregular reflections cannot be recovered by the technique. In our system, we add a pattern projector to the stereo camera pair so that artificial textures are augmented on the objects. To use the system at underwater environments, several problems should be compensated, i.e., refraction, disturbance by fluctuation and bubbles. Further, since surface of the objects are interfered by the bubbles, projected patterns, etc., those noises and patterns should be removed from captured images to recover original texture. To solve these problems, we propose three approaches; a depth-dependent calibration, Convolutional Neural Network(CNN)-stereo method and CNN-based texture recovery method. A depth-dependent calibration is our analysis to find the acceptable depth range for approximation by center projection to find the certain target depth for calibration. In terms of CNN stereo, unlike common CNNbased stereo methods which do not consider strong disturbances like refraction or bubbles, we designed a novel CNN architecture for stereo matching using multi-scale information, which is intended to be robust against such disturbances. Finally, we propose a multi-scale method for bubble and a projected-pattern removal method using CNNs to recover original textures. Experimental results are shown to prove the effectiveness of our method compared with the state of the art techniques. Furthermore, reconstruction of a live swimming fish is demonstrated to confirm the feasibility of our techniques.
Temporal shape super-resolution by intra-frame motion encoding using high-fps structured light
Oct 02, 2017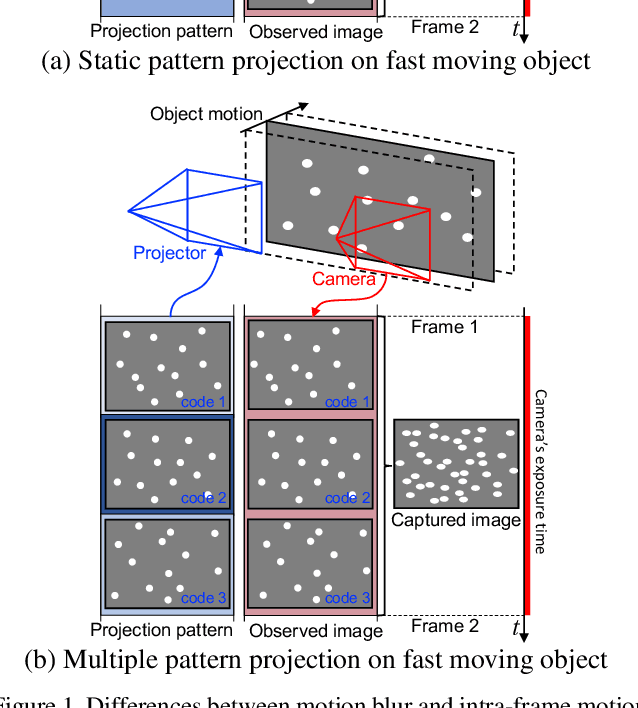

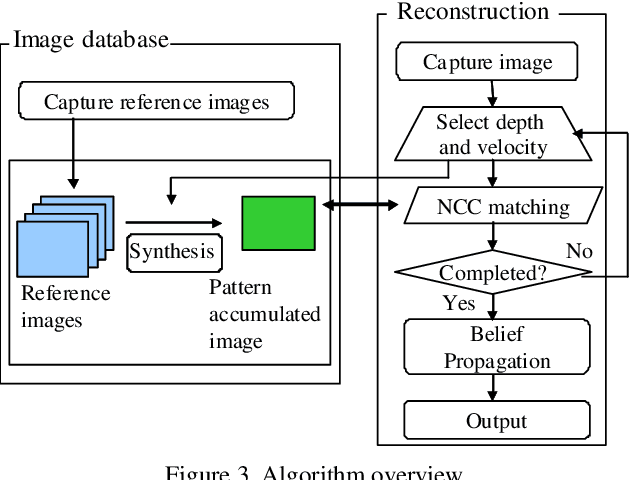
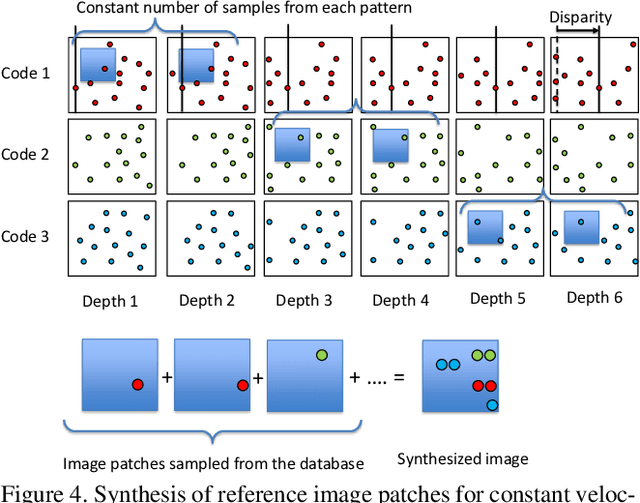
One of the solutions of depth imaging of moving scene is to project a static pattern on the object and use just a single image for reconstruction. However, if the motion of the object is too fast with respect to the exposure time of the image sensor, patterns on the captured image are blurred and reconstruction fails. In this paper, we impose multiple projection patterns into each single captured image to realize temporal super resolution of the depth image sequences. With our method, multiple patterns are projected onto the object with higher fps than possible with a camera. In this case, the observed pattern varies depending on the depth and motion of the object, so we can extract temporal information of the scene from each single image. The decoding process is realized using a learning-based approach where no geometric calibration is needed. Experiments confirm the effectiveness of our method where sequential shapes are reconstructed from a single image. Both quantitative evaluations and comparisons with recent techniques were also conducted.