 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Backbone in Class Imbalanced Federated Source Free Domain Adaptation: The Utility of Vision Foundation Models
Sep 10, 2025Federated Learning (FL) offers a framework for training models collaboratively while preserving data privacy of each client. Recently, research has focused on Federated Source-Free Domain Adaptation (FFREEDA), a more realistic scenario wherein client-held target domain data remains unlabeled, and the server can access source domain data only during pre-training. We extend this framework to a more complex and realistic setting: Class Imbalanced FFREEDA (CI-FFREEDA), which takes into account class imbalances in both the source and target domains, as well as label shifts between source and target and among target clients. The replication of existing methods in our experimental setup lead us to rethink the focus from enhancing aggregation and domain adaptation methods to improving the feature extractors within the network itself. We propose replacing the FFREEDA backbone with a frozen vision foundation model (VFM), thereby improving overall accuracy without extensive parameter tuning and reducing computational and communication costs in federated learning. Our experimental results demonstrate that VFMs effectively mitigate the effects of domain gaps, class imbalances, and even non-IID-ness among target clients, suggesting that strong feature extractors, not complex adaptation or FL methods, are key to success in the real-world FL.
Federated Source-free Domain Adaptation for Classification: Weighted Cluster Aggregation for Unlabeled Data
Dec 18, 2024



Federated learning (FL) commonly assumes that the server or some clients have labeled data, which is often impractical due to annotation costs and privacy concerns. Addressing this problem, we focus on a source-free domain adaptation task, where (1) the server holds a pre-trained model on labeled source domain data, (2) clients possess only unlabeled data from various target domains, and (3) the server and clients cannot access the source data in the adaptation phase. This task is known as Federated source-Free Domain Adaptation (FFREEDA). Specifically, we focus on classification tasks, while the previous work solely studies semantic segmentation. Our contribution is the novel Federated learning with Weighted Cluster Aggregation (FedWCA) method, designed to mitigate both domain shifts and privacy concerns with only unlabeled data. FedWCA comprises three phases: private and parameter-free clustering of clients to obtain domain-specific global models on the server, weighted aggregation of the global models for the clustered clients, and local domain adaptation with pseudo-labeling. Experimental results show that FedWCA surpasses several existing methods and baselines in FFREEDA, establishing its effectiveness and practicality.
Survey of Privacy Threats and Countermeasures in Federated Learning
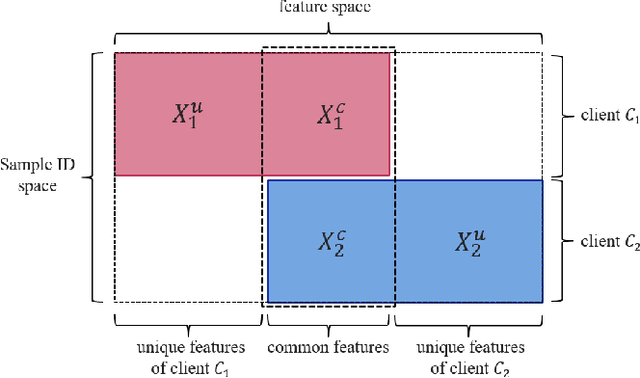
Feb 01, 2024Federated learning is widely considered to be as a privacy-aware learning method because no training data is exchanged directly between clients. Nevertheless, there are threats to privacy in federated learning, and privacy countermeasures have been studied. However, we note that common and unique privacy threats among typical types of federated learning have not been categorized and described in a comprehensive and specific way. In this paper, we describe privacy threats and countermeasures for the typical types of federated learning; horizontal federated learning, vertical federated learning, and transfer federated learning.
Heterogeneous Domain Adaptation with Positive and Unlabeled Data
Apr 17, 2023Heterogeneous unsupervised domain adaptation (HUDA) is the most challenging domain adaptation setting where the feature space differs between source and target domains, and the target domain has only unlabeled data. Existing HUDA methods assume that both positive and negative examples are available in the source domain, which may not be satisfied in some real applications. This paper addresses a new challenging setting called positive and unlabeled heterogeneous domain adaptation (PU-HDA), a HUDA setting where the source domain only has positives. PU-HDA can also be viewed as an extension of PU learning where the positive and unlabeled examples are sampled from different domains. A naive combination of existing HUDA and PU learning methods is ineffective in PU-HDA due to the gap in label distribution between the source and target domains. To overcome this issue, we propose a novel method, positive-adversarial domain adaptation (PADA), which can predict likely positive examples from the unlabeled target data and simultaneously align the feature spaces to reduce the distribution divergence between the whole source data and the likely positive target data. PADA achieves this by a unified adversarial training framework for learning a classifier to predict positive examples and a feature transformer to transform the target feature space to that of the source. Specifically, they are both trained to fool a common discriminator that determines whether the likely positive examples are from the target or source domain. We experimentally show that PADA outperforms several baseline methods, such as the naive combination of HUDA and PU learning.
Personalized Federated Learning with Multi-branch Architecture
Nov 15, 2022



Federated learning (FL) is a decentralized machine learning technique that enables multiple clients to collaboratively train models without revealing the raw data to each other. Although the traditional FL trains a single global model with average performance among clients, the statistical data heterogeneity across clients motivates personalized FL (PFL) which learns personalized models with good performance on each client's data. A key challenge in PFL is how to promote clients with similar data to collaborate more in a situation where each client has data from complex distribution and does not know each other's distribution. In this paper, we propose a new PFL method, personalized federated learning with multi-branch architecture (pFedMB), which achieves personalization by splitting each layer of neural networks into multiple branches and assigning client-specific weights to each branch. pFedMB is simple but effective to facilitate each client to share the knowledge with similar clients by adjusting the weights assigned to each branch. We experimentally show that pFedMB performs better than the state-of-the-art PFL methods using CIFAR10 dataset.
Continual Horizontal Federated Learning for Heterogeneous Data
Mar 04, 2022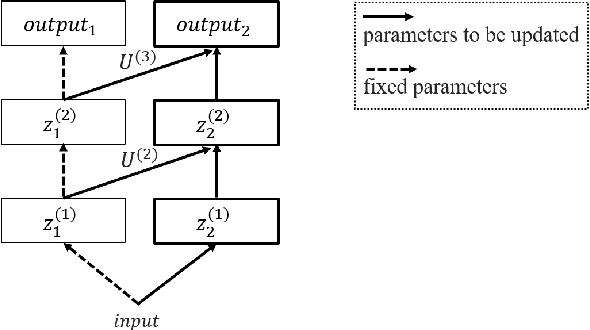

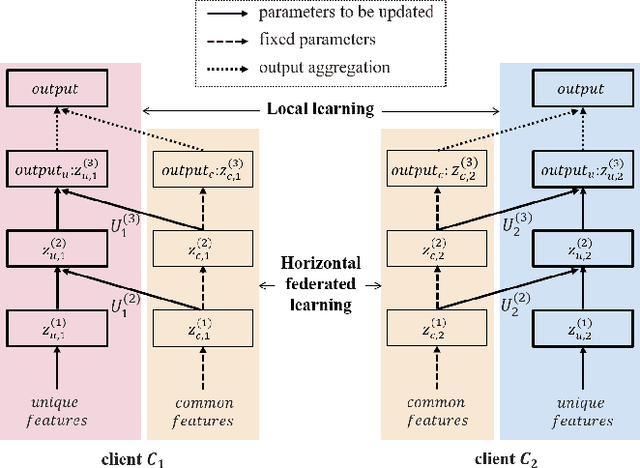
Federated learning is a promising machine learning technique that enables multiple clients to collaboratively build a model without revealing the raw data to each other. Among various types of federated learning methods, horizontal federated learning (HFL) is the best-studied category and handles homogeneous feature spaces. However, in the case of heterogeneous feature spaces, HFL uses only common features and leaves client-specific features unutilized. In this paper, we propose a HFL method using neural networks named continual horizontal federated learning (CHFL), a continual learning approach to improve the performance of HFL by taking advantage of unique features of each client. CHFL splits the network into two columns corresponding to common features and unique features, respectively. It jointly trains the first column by using common features through vanilla HFL and locally trains the second column by using unique features and leveraging the knowledge of the first one via lateral connections without interfering with the federated training of it. We conduct experiments on various real world datasets and show that CHFL greatly outperforms vanilla HFL that only uses common features and local learning that uses all features that each client has.
Knowledge Cross-Distillation for Membership Privacy
Nov 02, 2021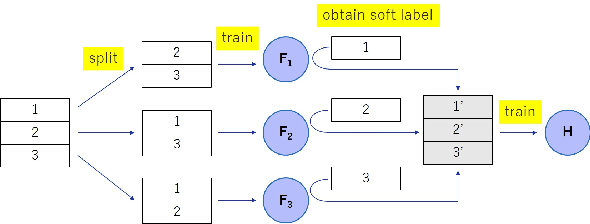
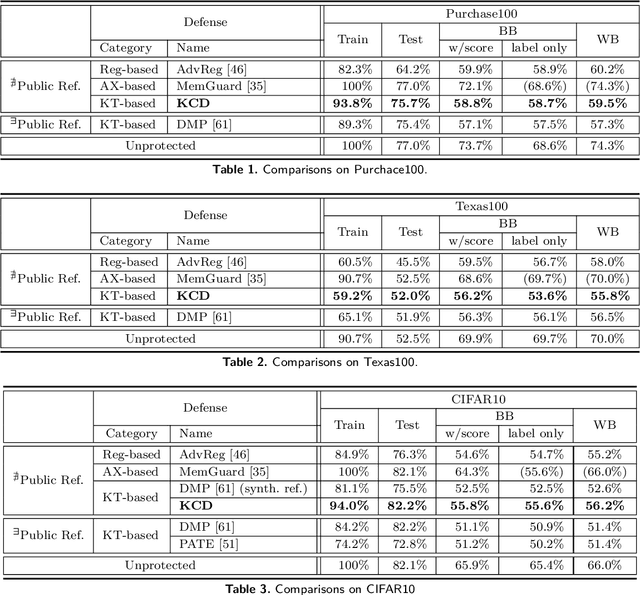
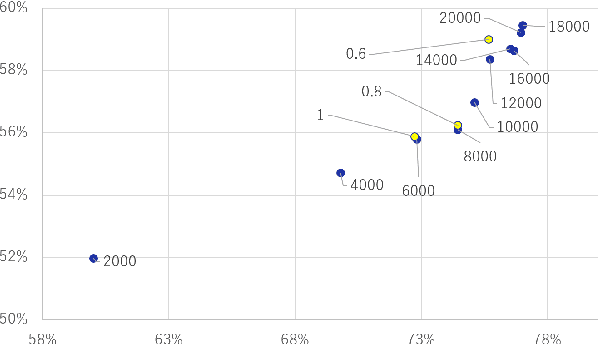
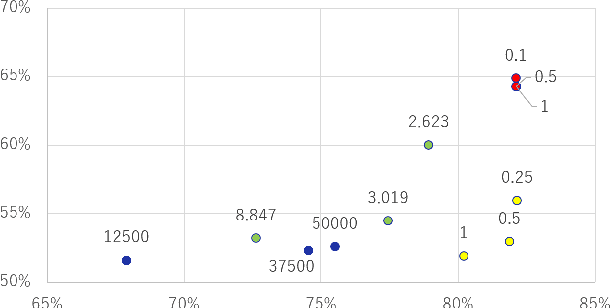
A membership inference attack (MIA) poses privacy risks on the training data of a machine learning model. With an MIA, an attacker guesses if the target data are a member of the training dataset. The state-of-the-art defense against MIAs, distillation for membership privacy (DMP), requires not only private data to protect but a large amount of unlabeled public data. However, in certain privacy-sensitive domains, such as medical and financial, the availability of public data is not obvious. Moreover, a trivial method to generate the public data by using generative adversarial networks significantly decreases the model accuracy, as reported by the authors of DMP. To overcome this problem, we propose a novel defense against MIAs using knowledge distillation without requiring public data. Our experiments show that the privacy protection and accuracy of our defense are comparable with those of DMP for the benchmark tabular datasets used in MIA researches, Purchase100 and Texas100, and our defense has much better privacy-utility trade-off than those of the existing defenses without using public data for image dataset CIFAR10.