 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Quality-Diversity Trade-offs for Large-Scale Batch Recommendation
Feb 02, 2026A core research question in recommender systems is to propose batches of highly relevant and diverse items, that is, items personalized to the user's preferences, but which also might get the user out of their comfort zone. This diversity might induce properties of serendipidity and novelty which might increase user engagement or revenue. However, many real-life problems arise in that case: e.g., avoiding to recommend distinct but too similar items to reduce the churn risk, and computational cost for large item libraries, up to millions of items. First, we consider the case when the user feedback model is perfectly observed and known in advance, and introduce an efficient algorithm called B-DivRec combining determinantal point processes and a fuzzy denuding procedure to adjust the degree of item diversity. This helps enforcing a quality-diversity trade-off throughout the user history. Second, we propose an approach to adaptively tailor the quality-diversity trade-off to the user, so that diversity in recommendations can be enhanced if it leads to positive feedback, and vice-versa. Finally, we illustrate the performance and versatility of B-DivRec in the two settings on synthetic and real-life data sets on movie recommendation and drug repurposing.
Unpacking the Implicit Norm Dynamics of Sharpness-Aware Minimization in Tensorized Models
Aug 14, 2025

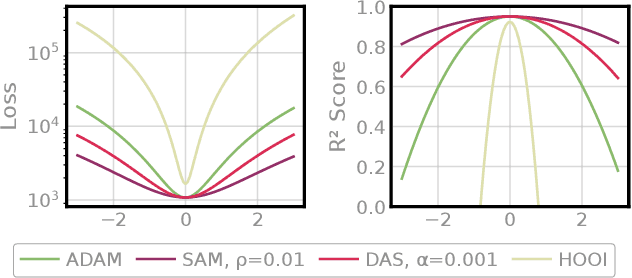

Sharpness-Aware Minimization (SAM) has been proven to be an effective optimization technique for improving generalization in overparameterized models. While prior works have explored the implicit regularization of SAM in simple two-core scale-invariant settings, its behavior in more general tensorized or scale-invariant models remains underexplored. In this work, we leverage scale-invariance to analyze the norm dynamics of SAM in general tensorized models. We introduce the notion of \emph{Norm Deviation} as a global measure of core norm imbalance, and derive its evolution under SAM using gradient flow analysis. We show that SAM's implicit control of Norm Deviation is governed by the covariance between core norms and their gradient magnitudes. Motivated by these findings, we propose a simple yet effective method, \emph{Deviation-Aware Scaling (DAS)}, which explicitly mimics this regularization behavior by scaling core norms in a data-adaptive manner. Our experiments across tensor completion, noisy training, model compression, and parameter-efficient fine-tuning confirm that DAS achieves competitive or improved performance over SAM, while offering reduced computational overhead.
Hierarchical Text Classification Using Black Box Large Language Models
Aug 06, 2025Hierarchical Text Classification (HTC) aims to assign texts to structured label hierarchies; however, it faces challenges due to data scarcity and model complexity. This study explores the feasibility of using black box Large Language Models (LLMs) accessed via APIs for HTC, as an alternative to traditional machine learning methods that require extensive labeled data and computational resources. We evaluate three prompting strategies -- Direct Leaf Label Prediction (DL), Direct Hierarchical Label Prediction (DH), and Top-down Multi-step Hierarchical Label Prediction (TMH) -- in both zero-shot and few-shot settings, comparing the accuracy and cost-effectiveness of these strategies. Experiments on two datasets show that a few-shot setting consistently improves classification accuracy compared to a zero-shot setting. While a traditional machine learning model achieves high accuracy on a dataset with a shallow hierarchy, LLMs, especially DH strategy, tend to outperform the machine learning model on a dataset with a deeper hierarchy. API costs increase significantly due to the higher input tokens required for deeper label hierarchies on DH strategy. These results emphasize the trade-off between accuracy improvement and the computational cost of prompt strategy. These findings highlight the potential of black box LLMs for HTC while underscoring the need to carefully select a prompt strategy to balance performance and cost.
Box-Constrained Softmax Function and Its Application for Post-Hoc Calibration
Jun 12, 2025Controlling the output probabilities of softmax-based models is a common problem in modern machine learning. Although the $\mathrm{Softmax}$ function provides soft control via its temperature parameter, it lacks the ability to enforce hard constraints, such as box constraints, on output probabilities, which can be critical in certain applications requiring reliable and trustworthy models. In this work, we propose the box-constrained softmax ($\mathrm{BCSoftmax}$) function, a novel generalization of the $\mathrm{Softmax}$ function that explicitly enforces lower and upper bounds on output probabilities. While $\mathrm{BCSoftmax}$ is formulated as the solution to a box-constrained optimization problem, we develop an exact and efficient computation algorithm for $\mathrm{BCSoftmax}$. As a key application, we introduce two post-hoc calibration methods based on $\mathrm{BCSoftmax}$. The proposed methods mitigate underconfidence and overconfidence in predictive models by learning the lower and upper bounds of the output probabilities or logits after model training, thereby enhancing reliability in downstream decision-making tasks. We demonstrate the effectiveness of our methods experimentally using the TinyImageNet, CIFAR-100, and 20NewsGroups datasets, achieving improvements in calibration metrics.
Dynamic Feature Selection from Variable Feature Sets Using Features of Features
Mar 12, 2025Machine learning models usually assume that a set of feature values used to obtain an output is fixed in advance. However, in many real-world problems, a cost is associated with measuring these features. To address the issue of reducing measurement costs, various methods have been proposed to dynamically select which features to measure, but existing methods assume that the set of measurable features remains constant, which makes them unsuitable for cases where the set of measurable features varies from instance to instance. To overcome this limitation, we define a new problem setting for Dynamic Feature Selection (DFS) with variable feature sets and propose a deep learning method that utilizes prior information about each feature, referred to as ''features of features''. Experimental results on several datasets demonstrate that the proposed method effectively selects features based on the prior information, even when the set of measurable features changes from instance to instance.
Exploring Causes and Mitigation of Hallucinations in Large Vision Language Models
Feb 24, 2025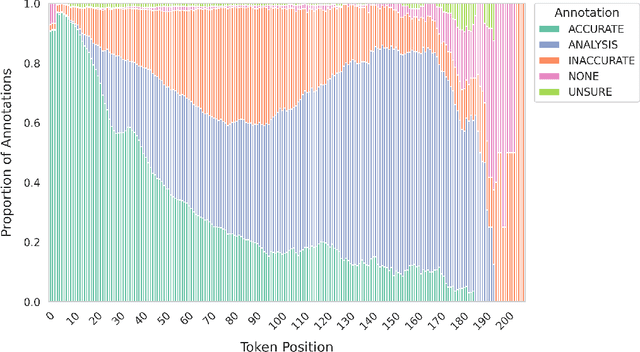
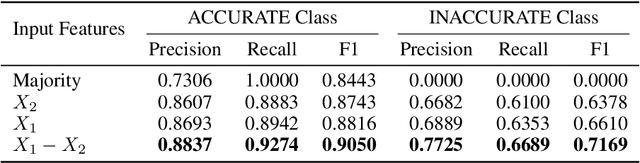
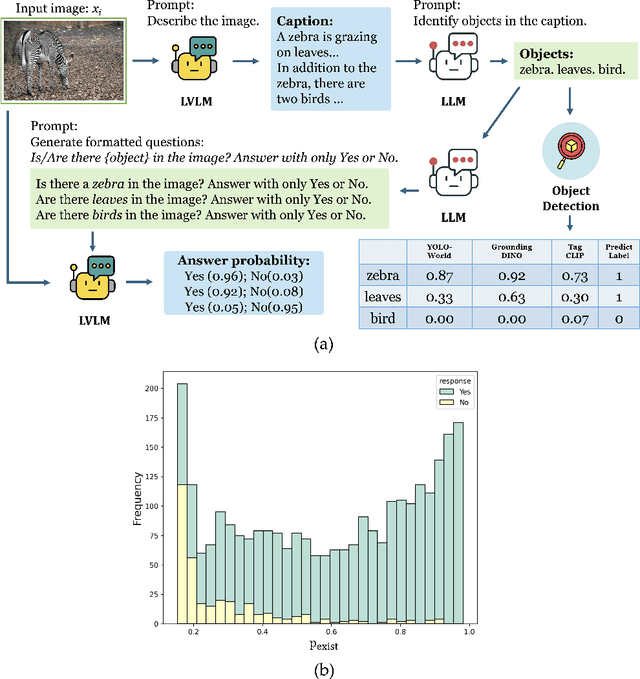
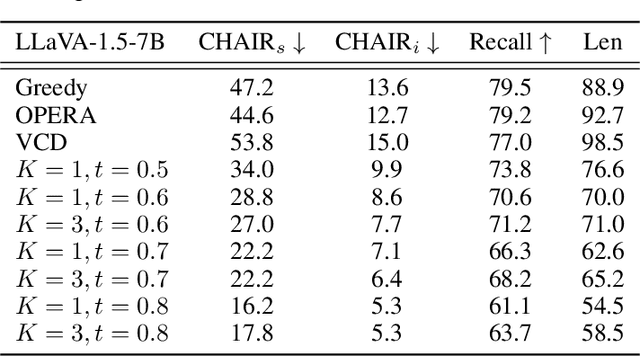
Large Vision-Language Models (LVLMs) integrate image encoders with Large Language Models (LLMs) to process multi-modal inputs and perform complex visual tasks. However, they often generate hallucinations by describing non-existent objects or attributes, compromising their reliability. This study analyzes hallucination patterns in image captioning, showing that not all tokens in the generation process are influenced by image input and that image dependency can serve as a useful signal for hallucination detection. To address this, we develop an automated pipeline to identify hallucinated objects and train a token-level classifier using hidden representations from parallel inference passes-with and without image input. Leveraging this classifier, we introduce a decoding strategy that effectively controls hallucination rates in image captioning at inference time.
Emulating Retrieval Augmented Generation via Prompt Engineering for Enhanced Long Context Comprehension in LLMs
Feb 18, 2025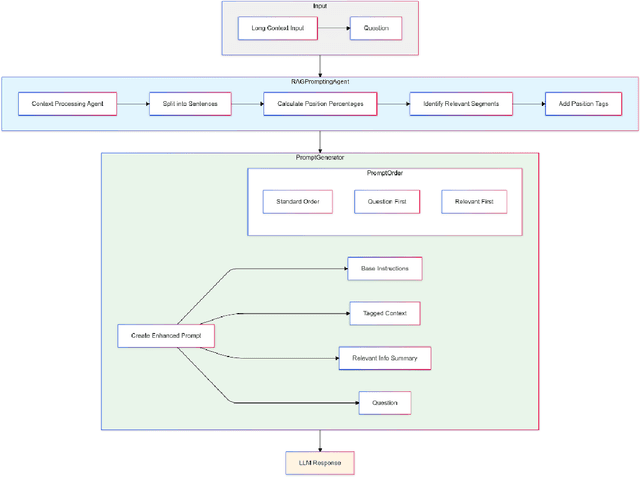


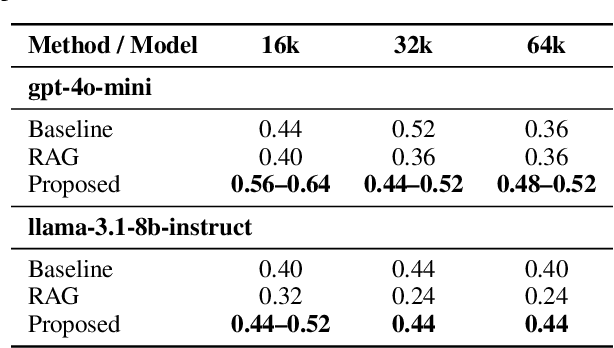
This paper addresses the challenge of comprehending very long contexts in Large Language Models (LLMs) by proposing a method that emulates Retrieval Augmented Generation (RAG) through specialized prompt engineering and chain-of-thought (CoT) reasoning. While recent LLMs support over 100,000 tokens in a single prompt, simply enlarging context windows has not guaranteed robust multi-hop reasoning when key details are scattered across massive input. Our approach treats the model as both the retriever and the reasoner: it first tags relevant segments within a long passage, then employs a stepwise CoT workflow to integrate these pieces of evidence. This single-pass method thereby reduces reliance on an external retriever, yet maintains focus on crucial segments. We evaluate our approach on selected tasks from BABILong, which interleaves standard bAbI QA problems with large amounts of distractor text. Compared to baseline (no retrieval) and naive RAG pipelines, our approach more accurately handles multi-fact questions such as object location tracking, counting, and indefinite knowledge. Furthermore, we analyze how prompt structure, including the order of question, relevant-text tags, and overall instructions, significantly affects performance. These findings underscore that optimized prompt engineering, combined with guided reasoning, can enhance LLMs' long-context comprehension and serve as a lightweight alternative to traditional retrieval pipelines.
Treatment Effect Estimation for Graph-Structured Targets
Dec 29, 2024Treatment effect estimation, which helps understand the causality between treatment and outcome variable, is a central task in decision-making across various domains. While most studies focus on treatment effect estimation on individual targets, in specific contexts, there is a necessity to comprehend the treatment effect on a group of targets, especially those that have relationships represented as a graph structure between them. In such cases, the focus of treatment assignment is prone to depend on a particular node of the graph, such as the one with the highest degree, thus resulting in an observational bias from a small part of the entire graph. Whereas a bias tends to be caused by the small part, straightforward extensions of previous studies cannot provide efficient bias mitigation owing to the use of the entire graph information. In this study, we propose Graph-target Treatment Effect Estimation (GraphTEE), a framework designed to estimate treatment effects specifically on graph-structured targets. GraphTEE aims to mitigate observational bias by focusing on confounding variable sets and consider a new regularization framework. Additionally, we provide a theoretical analysis on how GraphTEE performs better in terms of bias mitigation. Experiments on synthetic and semi-synthetic datasets demonstrate the effectiveness of our proposed method.
Federated Source-free Domain Adaptation for Classification: Weighted Cluster Aggregation for Unlabeled Data
Dec 18, 2024



Federated learning (FL) commonly assumes that the server or some clients have labeled data, which is often impractical due to annotation costs and privacy concerns. Addressing this problem, we focus on a source-free domain adaptation task, where (1) the server holds a pre-trained model on labeled source domain data, (2) clients possess only unlabeled data from various target domains, and (3) the server and clients cannot access the source data in the adaptation phase. This task is known as Federated source-Free Domain Adaptation (FFREEDA). Specifically, we focus on classification tasks, while the previous work solely studies semantic segmentation. Our contribution is the novel Federated learning with Weighted Cluster Aggregation (FedWCA) method, designed to mitigate both domain shifts and privacy concerns with only unlabeled data. FedWCA comprises three phases: private and parameter-free clustering of clients to obtain domain-specific global models on the server, weighted aggregation of the global models for the clustered clients, and local domain adaptation with pseudo-labeling. Experimental results show that FedWCA surpasses several existing methods and baselines in FFREEDA, establishing its effectiveness and practicality.
Cognitive Biases in Large Language Models: A Survey and Mitigation Experiments
Nov 30, 2024

Large Language Models (LLMs) are trained on large corpora written by humans and demonstrate high performance on various tasks. However, as humans are susceptible to cognitive biases, which can result in irrational judgments, LLMs can also be influenced by these biases, leading to irrational decision-making. For example, changing the order of options in multiple-choice questions affects the performance of LLMs due to order bias. In our research, we first conducted an extensive survey of existing studies examining LLMs' cognitive biases and their mitigation. The mitigation techniques in LLMs have the disadvantage that they are limited in the type of biases they can apply or require lengthy inputs or outputs. We then examined the effectiveness of two mitigation methods for humans, SoPro and AwaRe, when applied to LLMs, inspired by studies in crowdsourcing. To test the effectiveness of these methods, we conducted experiments on GPT-3.5 and GPT-4 to evaluate the influence of six biases on the outputs before and after applying these methods. The results demonstrate that while SoPro has little effect, AwaRe enables LLMs to mitigate the effect of these biases and make more rational responses.