 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Quality-Diversity Trade-offs for Large-Scale Batch Recommendation
Feb 02, 2026A core research question in recommender systems is to propose batches of highly relevant and diverse items, that is, items personalized to the user's preferences, but which also might get the user out of their comfort zone. This diversity might induce properties of serendipidity and novelty which might increase user engagement or revenue. However, many real-life problems arise in that case: e.g., avoiding to recommend distinct but too similar items to reduce the churn risk, and computational cost for large item libraries, up to millions of items. First, we consider the case when the user feedback model is perfectly observed and known in advance, and introduce an efficient algorithm called B-DivRec combining determinantal point processes and a fuzzy denuding procedure to adjust the degree of item diversity. This helps enforcing a quality-diversity trade-off throughout the user history. Second, we propose an approach to adaptively tailor the quality-diversity trade-off to the user, so that diversity in recommendations can be enhanced if it leads to positive feedback, and vice-versa. Finally, we illustrate the performance and versatility of B-DivRec in the two settings on synthetic and real-life data sets on movie recommendation and drug repurposing.
Enhancing Chess Reinforcement Learning with Graph Representation
Oct 31, 2024Mastering games is a hard task, as games can be extremely complex, and still fundamentally different in structure from one another. While the AlphaZero algorithm has demonstrated an impressive ability to learn the rules and strategy of a large variety of games, ranging from Go and Chess, to Atari games, its reliance on extensive computational resources and rigid Convolutional Neural Network (CNN) architecture limits its adaptability and scalability. A model trained to play on a $19\times 19$ Go board cannot be used to play on a smaller $13\times 13$ board, despite the similarity between the two Go variants. In this paper, we focus on Chess, and explore using a more generic Graph-based Representation of a game state, rather than a grid-based one, to introduce a more general architecture based on Graph Neural Networks (GNN). We also expand the classical Graph Attention Network (GAT) layer to incorporate edge-features, to naturally provide a generic policy output format. Our experiments, performed on smaller networks than the initial AlphaZero paper, show that this new architecture outperforms previous architectures with a similar number of parameters, being able to increase playing strength an order of magnitude faster. We also show that the model, when trained on a smaller $5\times 5$ variant of chess, is able to be quickly fine-tuned to play on regular $8\times 8$ chess, suggesting that this approach yields promising generalization abilities. Our code is available at https://github.com/akulen/AlphaGateau.
Variational Factorization Machines for Preference Elicitation in Large-Scale Recommender Systems
Dec 20, 2022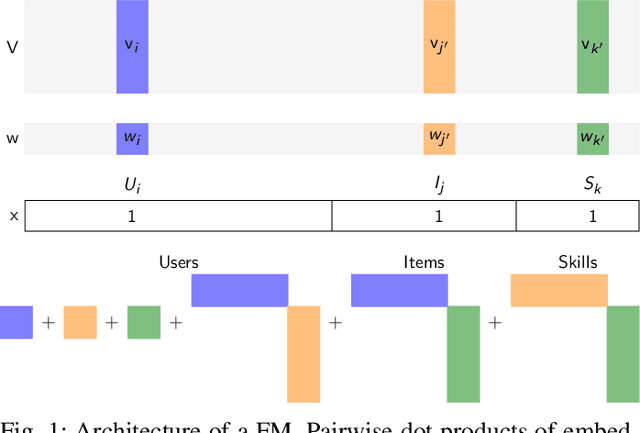
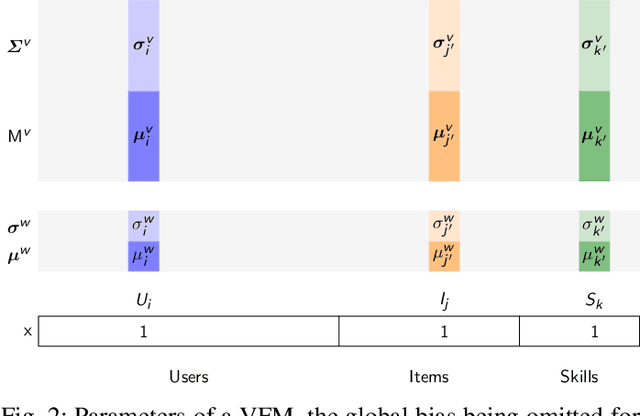
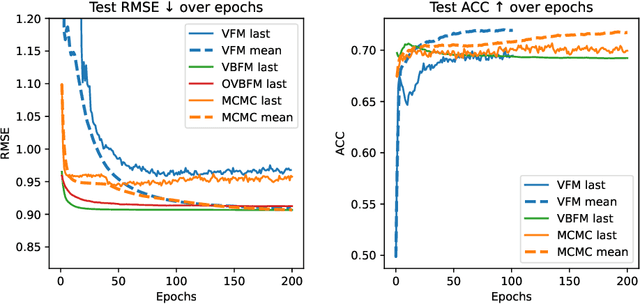
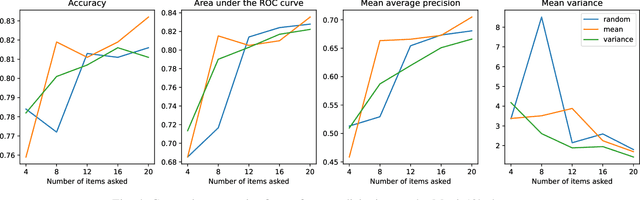
Factorization machines (FMs) are a powerful tool for regression and classification in the context of sparse observations, that has been successfully applied to collaborative filtering, especially when side information over users or items is available. Bayesian formulations of FMs have been proposed to provide confidence intervals over the predictions made by the model, however they usually involve Markov-chain Monte Carlo methods that require many samples to provide accurate predictions, resulting in slow training in the context of large-scale data. In this paper, we propose a variational formulation of factorization machines that allows us to derive a simple objective that can be easily optimized using standard mini-batch stochastic gradient descent, making it amenable to large-scale data. Our algorithm learns an approximate posterior distribution over the user and item parameters, which leads to confidence intervals over the predictions. We show, using several datasets, that it has comparable or better performance than existing methods in terms of prediction accuracy, and provide some applications in active learning strategies, e.g., preference elicitation techniques.
Privacy-Preserving Synthetic Educational Data Generation
Jul 07, 2022
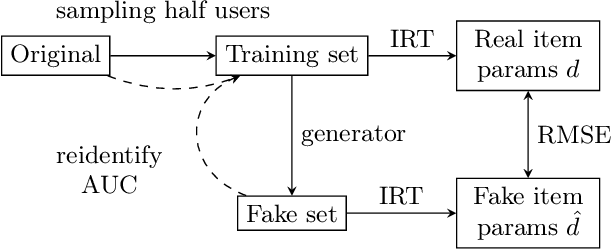

Institutions collect massive learning traces but they may not disclose it for privacy issues. Synthetic data generation opens new opportunities for research in education. In this paper we present a generative model for educational data that can preserve the privacy of participants, and an evaluation framework for comparing synthetic data generators. We show how naive pseudonymization can lead to re-identification threats and suggest techniques to guarantee privacy. We evaluate our method on existing massive educational open datasets.