 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaPLACE: Probabilistic Local Model-Agnostic Causal Explanations
Oct 01, 2023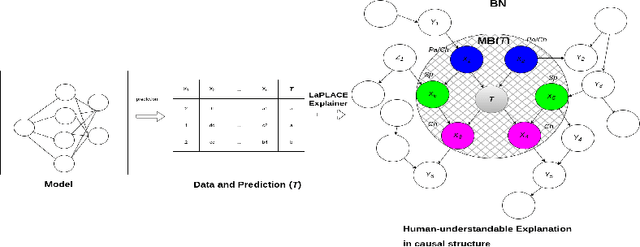
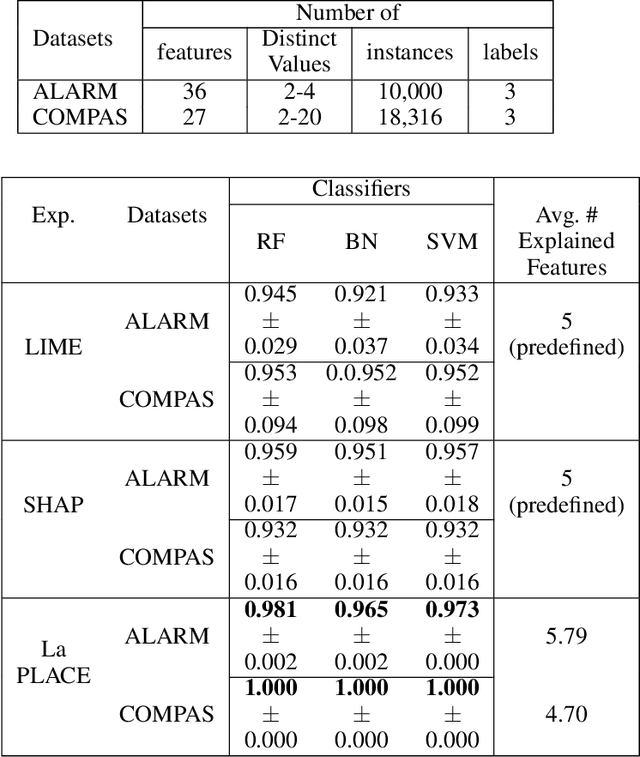
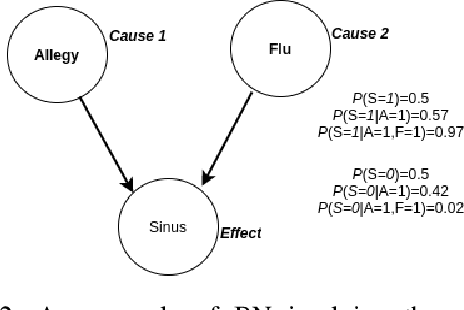

Machine learning models have undeniably achieved impressive performance across a range of applications. However, their often perceived black-box nature, and lack of transparency in decision-making, have raised concerns about understanding their predictions. To tackle this challenge, researchers have developed methods to provide explanations for machine learning models. In this paper, we introduce LaPLACE-explainer, designed to provide probabilistic cause-and-effect explanations for any classifier operating on tabular data, in a human-understandable manner. The LaPLACE-Explainer component leverages the concept of a Markov blanket to establish statistical boundaries between relevant and non-relevant features automatically. This approach results in the automatic generation of optimal feature subsets, serving as explanations for predictions. Importantly, this eliminates the need to predetermine a fixed number N of top features as explanations, enhancing the flexibility and adaptability of our methodology. Through the incorporation of conditional probabilities, our approach offers probabilistic causal explanations and outperforms LIME and SHAP (well-known model-agnostic explainers) in terms of local accuracy and consistency of explained features. LaPLACE's soundness, consistency, local accuracy, and adaptability are rigorously validated across various classification models. Furthermore, we demonstrate the practical utility of these explanations via experiments with both simulated and real-world datasets. This encompasses addressing trust-related issues, such as evaluating prediction reliability, facilitating model selection, enhancing trustworthiness, and identifying fairness-related concerns within classifiers.
Privacy-Preserving Synthetic Educational Data Generation
Jul 07, 2022
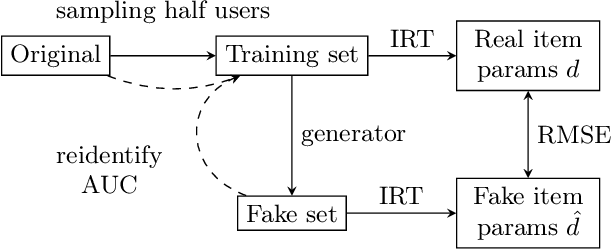

Institutions collect massive learning traces but they may not disclose it for privacy issues. Synthetic data generation opens new opportunities for research in education. In this paper we present a generative model for educational data that can preserve the privacy of participants, and an evaluation framework for comparing synthetic data generators. We show how naive pseudonymization can lead to re-identification threats and suggest techniques to guarantee privacy. We evaluate our method on existing massive educational open datasets.
Interpretable Knowledge Tracing: Simple and Efficient Student Modeling with Causal Relations
Dec 15, 2021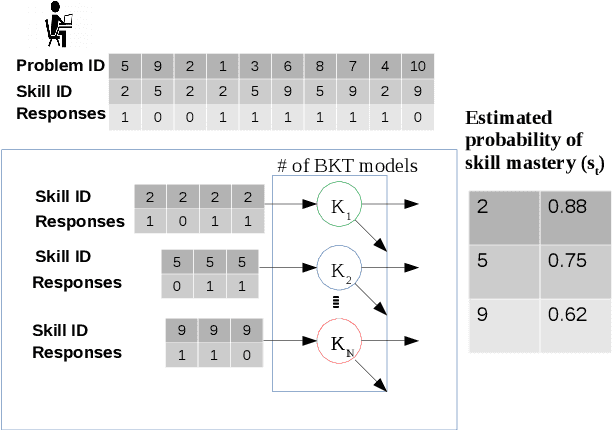
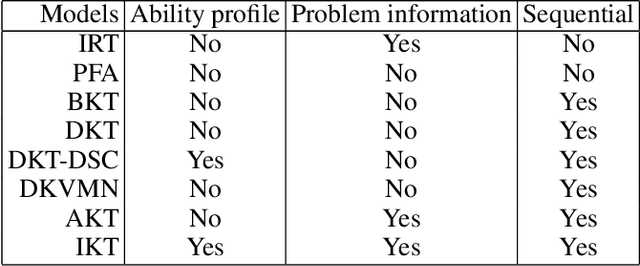

Intelligent Tutoring Systems have become critically important in future learning environments. Knowledge Tracing (KT) is a crucial part of that system. It is about inferring the skill mastery of students and predicting their performance to adjust the curriculum accordingly. Deep Learning-based KT models have shown significant predictive performance compared with traditional models. However, it is difficult to extract psychologically meaningful explanations from the tens of thousands of parameters in neural networks, that would relate to cognitive theory. There are several ways to achieve high accuracy in student performance prediction but diagnostic and prognostic reasoning is more critical in learning sciences. Since KT problem has few observable features (problem ID and student's correctness at each practice), we extract meaningful latent features from students' response data by using machine learning and data mining techniques. In this work, we present Interpretable Knowledge Tracing (IKT), a simple model that relies on three meaningful latent features: individual skill mastery, ability profile (learning transfer across skills), and problem difficulty. IKT's prediction of future student performance is made using a Tree-Augmented Naive Bayes Classifier (TAN), therefore its predictions are easier to explain than deep learning-based student models. IKT also shows better student performance prediction than deep learning-based student models without requiring a huge amount of parameters. We conduct ablation studies on each feature to examine their contribution to student performance prediction. Thus, IKT has great potential for providing adaptive and personalized instructions with causal reasoning in real-world educational systems.
BKT-LSTM: Efficient Student Modeling for knowledge tracing and student performance prediction
Jan 06, 2021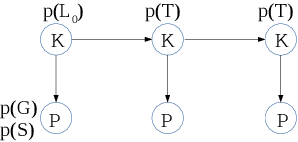
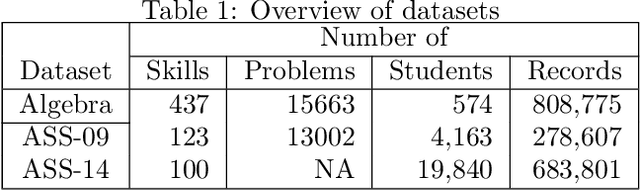
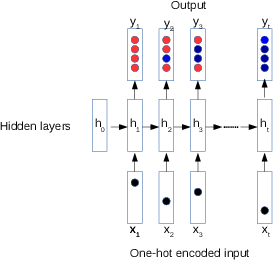
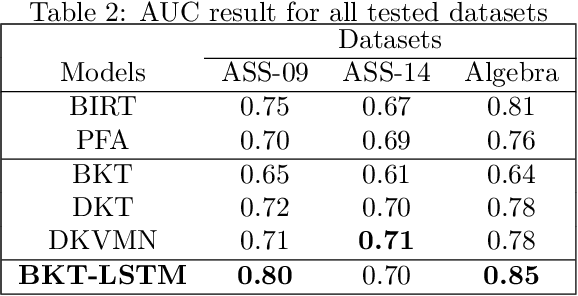
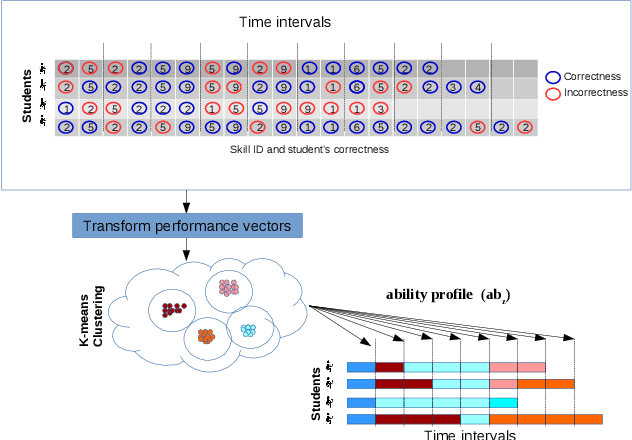
Recently, we have seen a rapid rise in usage of online educational platforms. The personalized education became crucially important in future learning environments. Knowledge tracing (KT) refers to the detection of students' knowledge states and predict future performance given their past outcomes for providing adaptive solution to Intelligent Tutoring Systems (ITS). Bayesian Knowledge Tracing (BKT) is a model to capture mastery level of each skill with psychologically meaningful parameters and widely used in successful tutoring systems. However, it is unable to detect learning transfer across skills because each skill model is learned independently and shows lower efficiency in student performance prediction. While recent KT models based on deep neural networks shows impressive predictive power but it came with a price. Ten of thousands of parameters in neural networks are unable to provide psychologically meaningful interpretation that reflect to cognitive theory. In this paper, we proposed an efficient student model called BKT-LSTM. It contains three meaningful components: individual \textit{skill mastery} assessed by BKT, \textit{ability profile} (learning transfer across skills) detected by k-means clustering and \textit{problem difficulty}. All these components are taken into account in student's future performance prediction by leveraging predictive power of LSTM. BKT-LSTM outperforms state-of-the-art student models in student's performance prediction by considering these meaningful features instead of using binary values of student's past interaction in DKT. We also conduct ablation studies on each of BKT-LSTM model components to examine their value and each component shows significant contribution in student's performance prediction. Thus, it has potential for providing adaptive and personalized instruction in real-world educational systems.
Deep Knowledge Tracing and Dynamic Student Classification for Knowledge Tracing
Sep 24, 2018
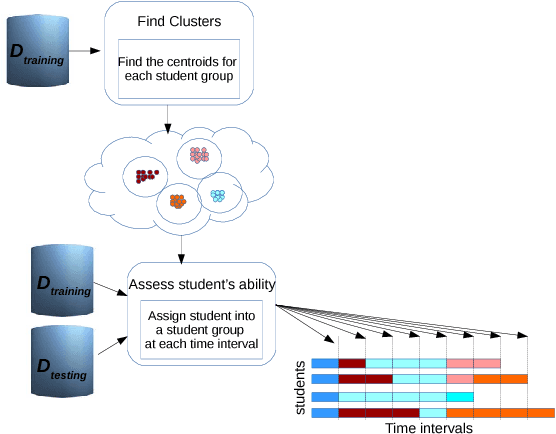
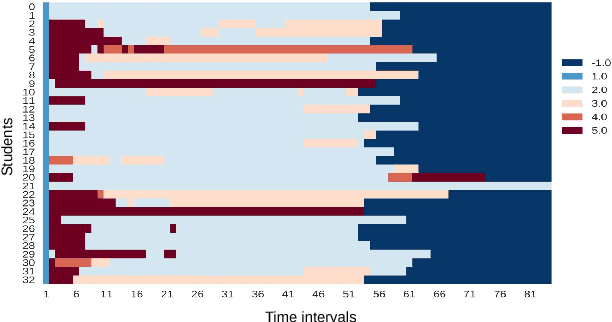
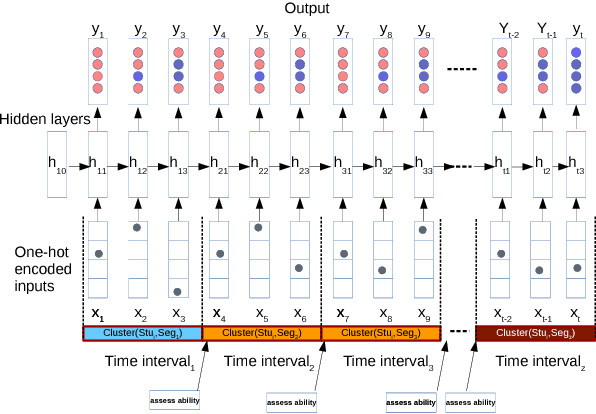
In Intelligent Tutoring System (ITS), tracing the student's knowledge state during learning has been studied for several decades in order to provide more supportive learning instructions. In this paper, we propose a novel model for knowledge tracing that i) captures students' learning ability and dynamically assigns students into distinct groups with similar ability at regular time intervals, and ii) combines this information with a Recurrent Neural Network architecture known as Deep Knowledge Tracing. Experimental results confirm that the proposed model is significantly better at predicting student performance than well known state-of-the-art techniques for student modelling.