 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaPLACE: Probabilistic Local Model-Agnostic Causal Explanations
Paper and Code
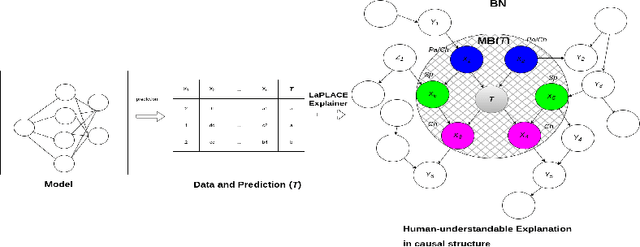
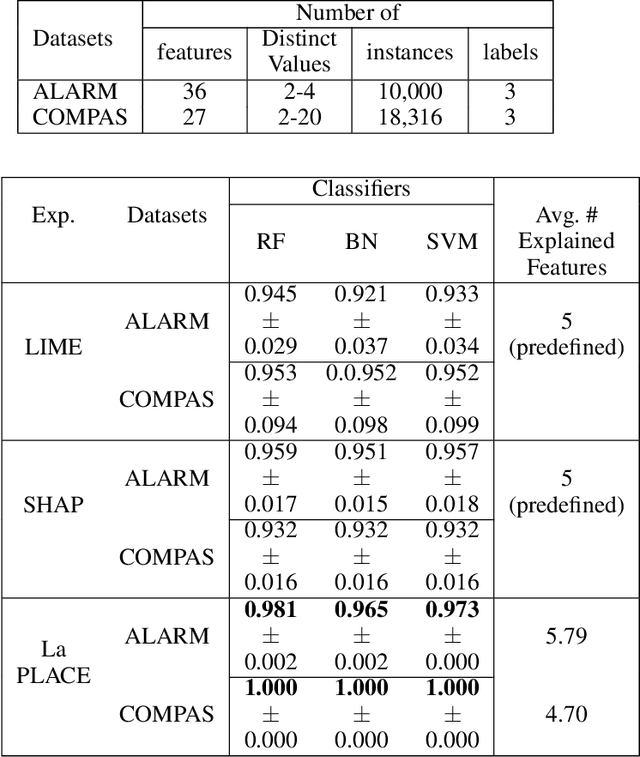
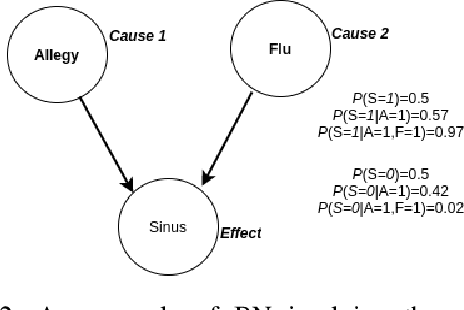

Machine learning models have undeniably achieved impressive performance across a range of applications. However, their often perceived black-box nature, and lack of transparency in decision-making, have raised concerns about understanding their predictions. To tackle this challenge, researchers have developed methods to provide explanations for machine learning models. In this paper, we introduce LaPLACE-explainer, designed to provide probabilistic cause-and-effect explanations for any classifier operating on tabular data, in a human-understandable manner. The LaPLACE-Explainer component leverages the concept of a Markov blanket to establish statistical boundaries between relevant and non-relevant features automatically. This approach results in the automatic generation of optimal feature subsets, serving as explanations for predictions. Importantly, this eliminates the need to predetermine a fixed number N of top features as explanations, enhancing the flexibility and adaptability of our methodology. Through the incorporation of conditional probabilities, our approach offers probabilistic causal explanations and outperforms LIME and SHAP (well-known model-agnostic explainers) in terms of local accuracy and consistency of explained features. LaPLACE's soundness, consistency, local accuracy, and adaptability are rigorously validated across various classification models. Furthermore, we demonstrate the practical utility of these explanations via experiments with both simulated and real-world datasets. This encompasses addressing trust-related issues, such as evaluating prediction reliability, facilitating model selection, enhancing trustworthiness, and identifying fairness-related concerns within classifiers.