 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Knowledge Tracing: Real-Time Adaptation using Tabular Foundation Models
Feb 06, 2026Deep knowledge tracing models have achieved significant breakthroughs in modeling student learning trajectories. However, these architectures require substantial training time and are prone to overfitting on datasets with short sequences. In this paper, we explore a new paradigm for knowledge tracing by leveraging tabular foundation models (TFMs). Unlike traditional methods that require offline training on a fixed training set, our approach performs real-time ''live'' knowledge tracing in an online way. The core of our method lies in a two-way attention mechanism: while attention knowledge tracing models only attend across earlier time steps, TFMs simultaneously attend across both time steps and interactions of other students in the training set. They align testing sequences with relevant training sequences at inference time, therefore skipping the training step entirely. We demonstrate, using several datasets of increasing size, that our method achieves competitive predictive performance with up to 273x speedups, in a setting where more student interactions are observed over time.
Adaptive Quality-Diversity Trade-offs for Large-Scale Batch Recommendation
Feb 02, 2026A core research question in recommender systems is to propose batches of highly relevant and diverse items, that is, items personalized to the user's preferences, but which also might get the user out of their comfort zone. This diversity might induce properties of serendipidity and novelty which might increase user engagement or revenue. However, many real-life problems arise in that case: e.g., avoiding to recommend distinct but too similar items to reduce the churn risk, and computational cost for large item libraries, up to millions of items. First, we consider the case when the user feedback model is perfectly observed and known in advance, and introduce an efficient algorithm called B-DivRec combining determinantal point processes and a fuzzy denuding procedure to adjust the degree of item diversity. This helps enforcing a quality-diversity trade-off throughout the user history. Second, we propose an approach to adaptively tailor the quality-diversity trade-off to the user, so that diversity in recommendations can be enhanced if it leads to positive feedback, and vice-versa. Finally, we illustrate the performance and versatility of B-DivRec in the two settings on synthetic and real-life data sets on movie recommendation and drug repurposing.
Large Language Models as Students Who Think Aloud: Overly Coherent, Verbose, and Confident
Feb 01, 2026Large language models (LLMs) are increasingly embedded in AI-based tutoring systems. Can they faithfully model novice reasoning and metacognitive judgments? Existing evaluations emphasize problem-solving accuracy, overlooking the fragmented and imperfect reasoning that characterizes human learning. We evaluate LLMs as novices using 630 think-aloud utterances from multi-step chemistry tutoring problems with problem-solving logs of student hint use, attempts, and problem context. We compare LLM-generated reasoning to human learner utterances under minimal and extended contextual prompting, and assess the models' ability to predict step-level learner success. Although GPT-4.1 generates fluent and contextually appropriate continuations, its reasoning is systematically over-coherent, verbose, and less variable than human think-alouds. These effects intensify with a richer problem-solving context during prompting. Learner performance was consistently overestimated. These findings highlight epistemic limitations of simulating learning with LLMs. We attribute these limitations to LLM training data, including expert-like solutions devoid of expressions of affect and working memory constraints during problem solving. Our evaluation framework can guide future design of adaptive systems that more faithfully support novice learning and self-regulation using generative artificial intelligence.
A Pre-Trained Graph-Based Model for Adaptive Sequencing of Educational Documents
Nov 18, 2024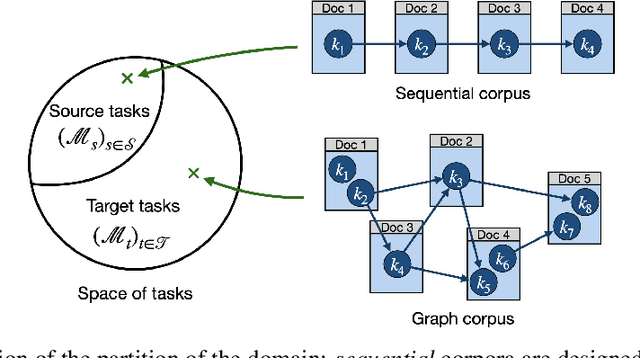

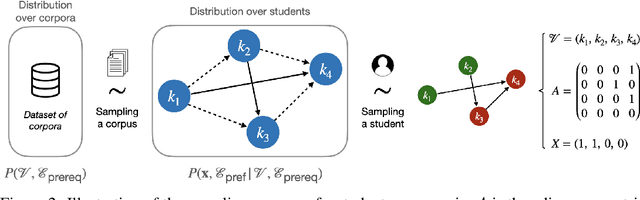

Massive Open Online Courses (MOOCs) have greatly contributed to making education more accessible. However, many MOOCs maintain a rigid, one-size-fits-all structure that fails to address the diverse needs and backgrounds of individual learners. Learning path personalization aims to address this limitation, by tailoring sequences of educational content to optimize individual student learning outcomes. Existing approaches, however, often require either massive student interaction data or extensive expert annotation, limiting their broad application. In this study, we introduce a novel data-efficient framework for learning path personalization that operates without expert annotation. Our method employs a flexible recommender system pre-trained with reinforcement learning on a dataset of raw course materials. Through experiments on semi-synthetic data, we show that this pre-training stage substantially improves data-efficiency in a range of adaptive learning scenarios featuring new educational materials. This opens up new perspectives for the design of foundation models for adaptive learning.
Towards Scalable Adaptive Learning with Graph Neural Networks and Reinforcement Learning
May 10, 2023Adaptive learning is an area of educational technology that consists in delivering personalized learning experiences to address the unique needs of each learner. An important subfield of adaptive learning is learning path personalization: it aims at designing systems that recommend sequences of educational activities to maximize students' learning outcomes. Many machine learning approaches have already demonstrated significant results in a variety of contexts related to learning path personalization. However, most of them were designed for very specific settings and are not very reusable. This is accentuated by the fact that they often rely on non-scalable models, which are unable to integrate new elements after being trained on a specific set of educational resources. In this paper, we introduce a flexible and scalable approach towards the problem of learning path personalization, which we formalize as a reinforcement learning problem. Our model is a sequential recommender system based on a graph neural network, which we evaluate on a population of simulated learners. Our results demonstrate that it can learn to make good recommendations in the small-data regime.
Multidimensional Item Response Theory in the Style of Collaborative Filtering
Jan 03, 2023This paper presents a machine learning approach to multidimensional item response theory (MIRT), a class of latent factor models that can be used to model and predict student performance from observed assessment data. Inspired by collaborative filtering, we define a general class of models that includes many MIRT models. We discuss the use of penalized joint maximum likelihood (JML) to estimate individual models and cross-validation to select the best performing model. This model evaluation process can be optimized using batching techniques, such that even sparse large-scale data can be analyzed efficiently. We illustrate our approach with simulated and real data, including an example from a massive open online course (MOOC). The high-dimensional model fit to this large and sparse dataset does not lend itself well to traditional methods of factor interpretation. By analogy to recommender-system applications, we propose an alternative "validation" of the factor model, using auxiliary information about the popularity of items consulted during an open-book exam in the course.
* 42 pages, 2 pages, 14 tables, accepted at Psychometrika
Variational Factorization Machines for Preference Elicitation in Large-Scale Recommender Systems
Dec 20, 2022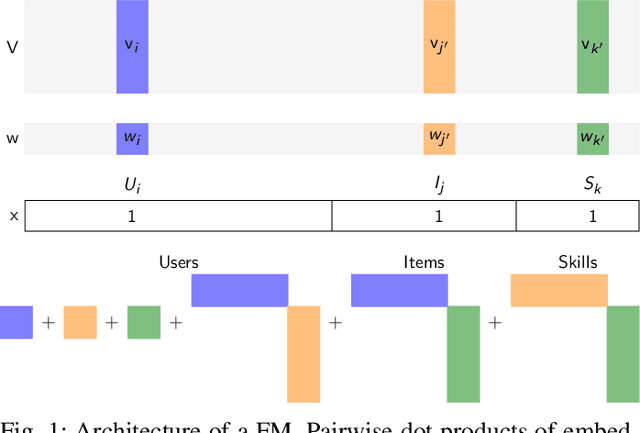
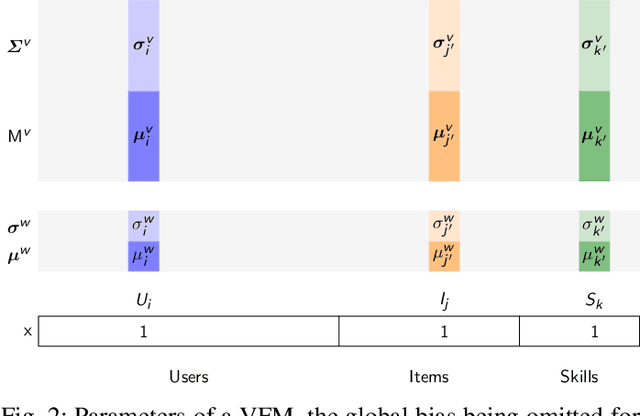
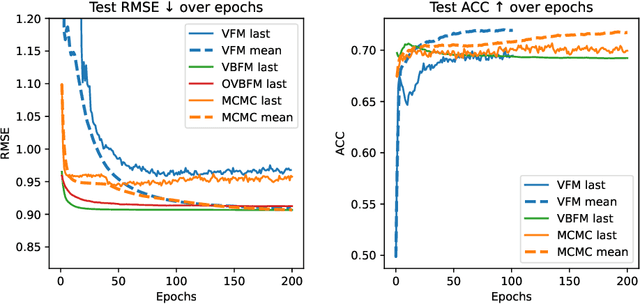
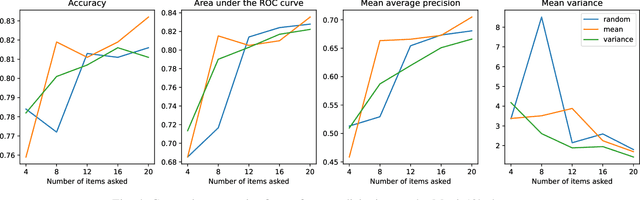
Factorization machines (FMs) are a powerful tool for regression and classification in the context of sparse observations, that has been successfully applied to collaborative filtering, especially when side information over users or items is available. Bayesian formulations of FMs have been proposed to provide confidence intervals over the predictions made by the model, however they usually involve Markov-chain Monte Carlo methods that require many samples to provide accurate predictions, resulting in slow training in the context of large-scale data. In this paper, we propose a variational formulation of factorization machines that allows us to derive a simple objective that can be easily optimized using standard mini-batch stochastic gradient descent, making it amenable to large-scale data. Our algorithm learns an approximate posterior distribution over the user and item parameters, which leads to confidence intervals over the predictions. We show, using several datasets, that it has comparable or better performance than existing methods in terms of prediction accuracy, and provide some applications in active learning strategies, e.g., preference elicitation techniques.
Privacy-Preserving Synthetic Educational Data Generation
Jul 07, 2022
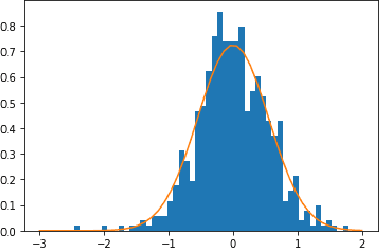
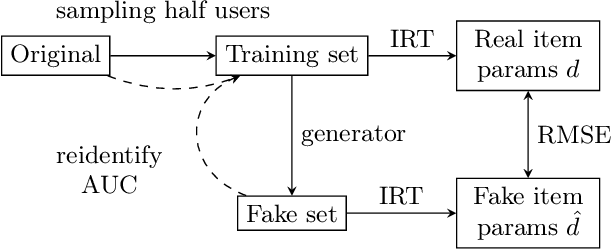

Institutions collect massive learning traces but they may not disclose it for privacy issues. Synthetic data generation opens new opportunities for research in education. In this paper we present a generative model for educational data that can preserve the privacy of participants, and an evaluation framework for comparing synthetic data generators. We show how naive pseudonymization can lead to re-identification threats and suggest techniques to guarantee privacy. We evaluate our method on existing massive educational open datasets.
DAS3H: Modeling Student Learning and Forgetting for Optimally Scheduling Distributed Practice of Skills
May 14, 2019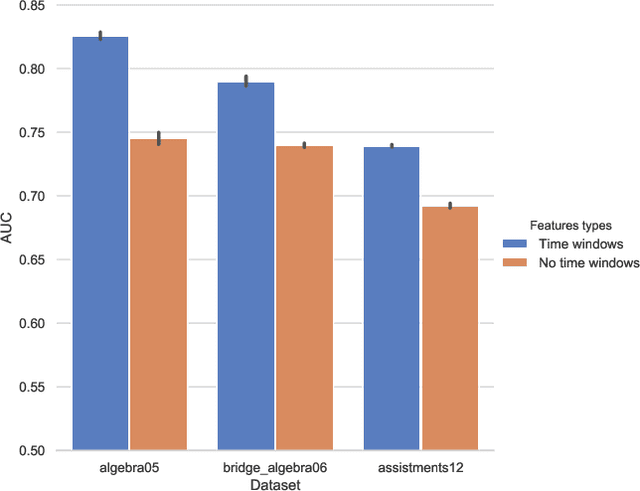

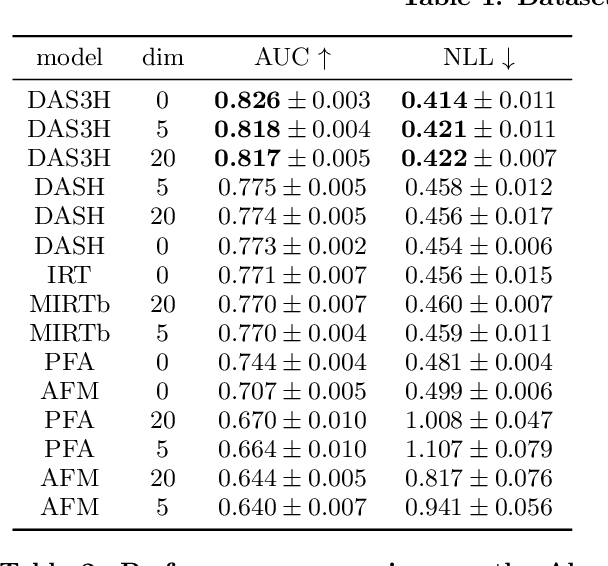
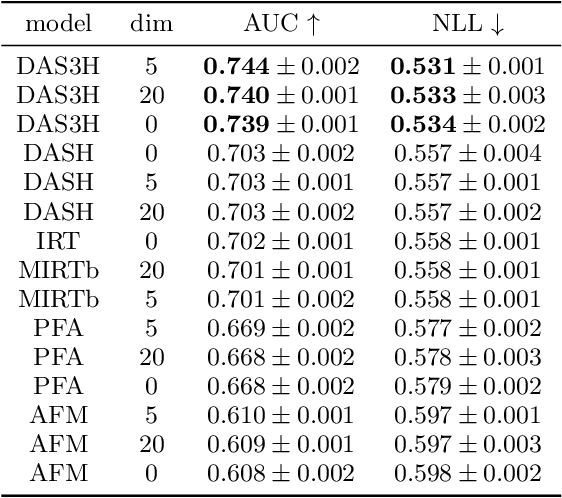
Spaced repetition is among the most studied learning strategies in the cognitive science literature. It consists in temporally distributing exposure to an information so as to improve long-term memorization. Providing students with an adaptive and personalized distributed practice schedule would benefit more than just a generic scheduler. However, the applicability of such adaptive schedulers seems to be limited to pure memorization, e.g. flashcards or foreign language learning. In this article, we first frame the research problem of optimizing an adaptive and personalized spaced repetition scheduler when memorization concerns the application of underlying multiple skills. To this end, we choose to rely on a student model for inferring knowledge state and memory dynamics on any skill or combination of skills. We argue that no knowledge tracing model takes both memory decay and multiple skill tagging into account for predicting student performance. As a consequence, we propose a new student learning and forgetting model suited to our research problem: DAS3H builds on the additive factor models and includes a representation of the temporal distribution of past practice on the skills involved by an item. In particular, DAS3H allows the learning and forgetting curves to differ from one skill to another. Finally, we provide empirical evidence on three real-world educational datasets that DAS3H outperforms other state-of-the-art EDM models. These results suggest that incorporating both item-skill relationships and forgetting effect improves over student models that consider one or the other.
Knowledge Tracing Machines: Factorization Machines for Knowledge Tracing
Nov 15, 2018
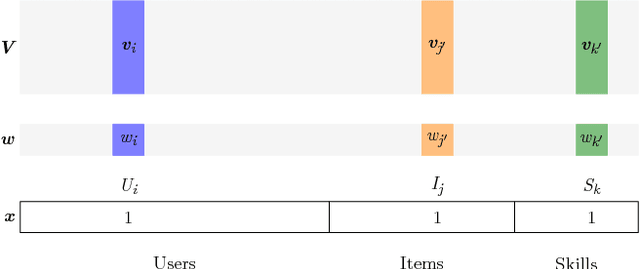


Knowledge tracing is a sequence prediction problem where the goal is to predict the outcomes of students over questions as they are interacting with a learning platform. By tracking the evolution of the knowledge of some student, one can optimize instruction. Existing methods are either based on temporal latent variable models, or factor analysis with temporal features. We here show that factorization machines (FMs), a model for regression or classification, encompasses several existing models in the educational literature as special cases, notably additive factor model, performance factor model, and multidimensional item response theory. We show, using several real datasets of tens of thousands of users and items, that FMs can estimate student knowledge accurately and fast even when student data is sparsely observed, and handle side information such as multiple knowledge components and number of attempts at item or skill level. Our approach allows to fit student models of higher dimension than existing models, and provides a testbed to try new combinations of features in order to improve existing models.