 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Scoring for Reading Comprehension via In-context BERT Tuning
May 19, 2022
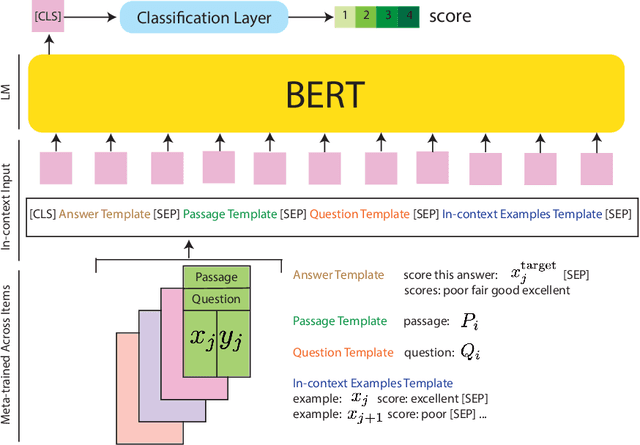

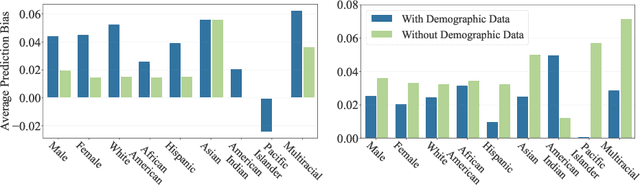
Automated scoring of open-ended student responses has the potential to significantly reduce human grader effort. Recent advances in automated scoring often leverage textual representations based on pre-trained language models such as BERT and GPT as input to scoring models. Most existing approaches train a separate model for each item/question, which is suitable for scenarios such as essay scoring where items can be quite different from one another. However, these approaches have two limitations: 1) they fail to leverage item linkage for scenarios such as reading comprehension where multiple items may share a reading passage; 2) they are not scalable since storing one model per item becomes difficult when models have a large number of parameters. In this paper, we report our (grand prize-winning) solution to the National Assessment of Education Progress (NAEP) automated scoring challenge for reading comprehension. Our approach, in-context BERT fine-tuning, produces a single shared scoring model for all items with a carefully-designed input structure to provide contextual information on each item. We demonstrate the effectiveness of our approach via local evaluations using the training dataset provided by the challenge. We also discuss the biases, common error types, and limitations of our approach.
DAS3H: Modeling Student Learning and Forgetting for Optimally Scheduling Distributed Practice of Skills
May 14, 2019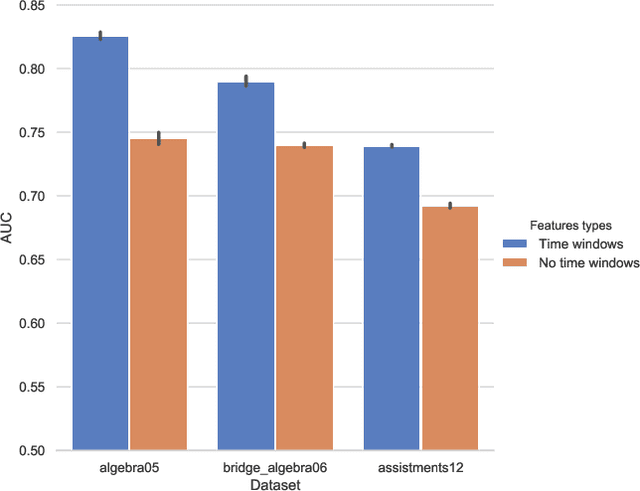

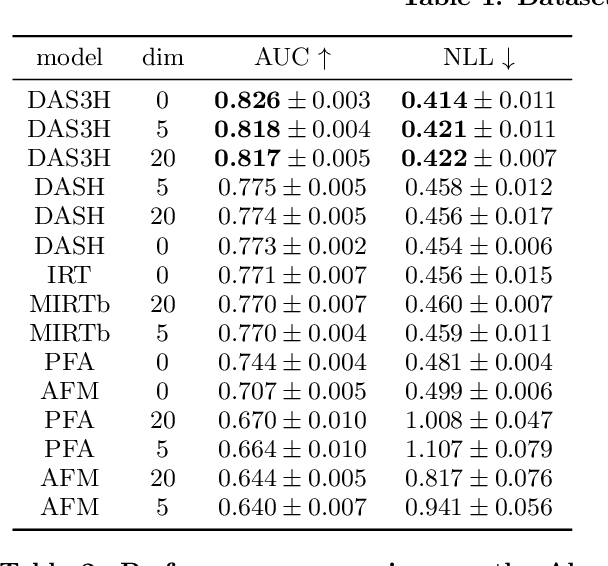
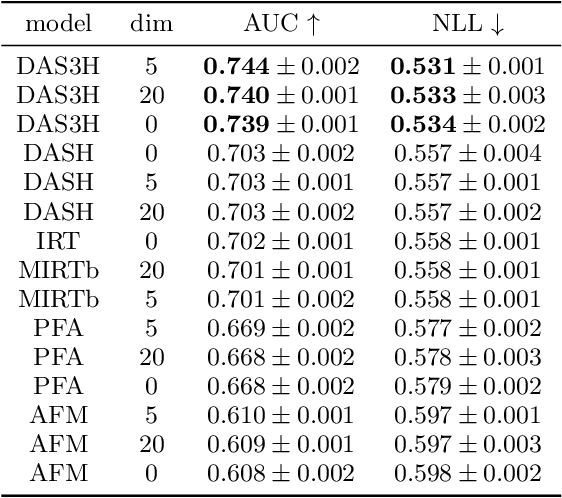
Spaced repetition is among the most studied learning strategies in the cognitive science literature. It consists in temporally distributing exposure to an information so as to improve long-term memorization. Providing students with an adaptive and personalized distributed practice schedule would benefit more than just a generic scheduler. However, the applicability of such adaptive schedulers seems to be limited to pure memorization, e.g. flashcards or foreign language learning. In this article, we first frame the research problem of optimizing an adaptive and personalized spaced repetition scheduler when memorization concerns the application of underlying multiple skills. To this end, we choose to rely on a student model for inferring knowledge state and memory dynamics on any skill or combination of skills. We argue that no knowledge tracing model takes both memory decay and multiple skill tagging into account for predicting student performance. As a consequence, we propose a new student learning and forgetting model suited to our research problem: DAS3H builds on the additive factor models and includes a representation of the temporal distribution of past practice on the skills involved by an item. In particular, DAS3H allows the learning and forgetting curves to differ from one skill to another. Finally, we provide empirical evidence on three real-world educational datasets that DAS3H outperforms other state-of-the-art EDM models. These results suggest that incorporating both item-skill relationships and forgetting effect improves over student models that consider one or the other.