 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Scoring for Reading Comprehension via In-context BERT Tuning
Paper and Code

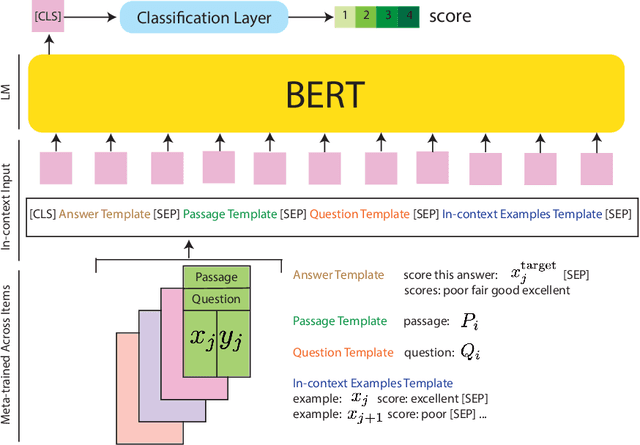

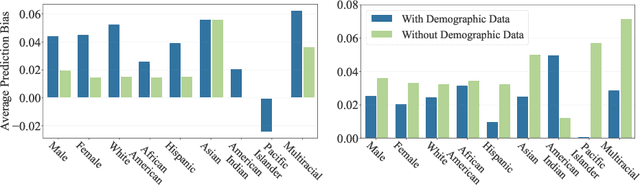
Automated scoring of open-ended student responses has the potential to significantly reduce human grader effort. Recent advances in automated scoring often leverage textual representations based on pre-trained language models such as BERT and GPT as input to scoring models. Most existing approaches train a separate model for each item/question, which is suitable for scenarios such as essay scoring where items can be quite different from one another. However, these approaches have two limitations: 1) they fail to leverage item linkage for scenarios such as reading comprehension where multiple items may share a reading passage; 2) they are not scalable since storing one model per item becomes difficult when models have a large number of parameters. In this paper, we report our (grand prize-winning) solution to the National Assessment of Education Progress (NAEP) automated scoring challenge for reading comprehension. Our approach, in-context BERT fine-tuning, produces a single shared scoring model for all items with a carefully-designed input structure to provide contextual information on each item. We demonstrate the effectiveness of our approach via local evaluations using the training dataset provided by the challenge. We also discuss the biases, common error types, and limitations of our approach.