 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKASER: Knowledge-Aligned Student Error Simulator for Open-Ended Coding Tasks
Jan 10, 2026Open-ended tasks, such as coding problems that are common in computer science education, provide detailed insights into student knowledge. However, training large language models (LLMs) to simulate and predict possible student errors in their responses to these problems can be challenging: they often suffer from mode collapse and fail to fully capture the diversity in syntax, style, and solution approach in student responses. In this work, we present KASER (Knowledge-Aligned Student Error Simulator), a novel approach that aligns errors with student knowledge. We propose a training method based on reinforcement learning using a hybrid reward that reflects three aspects of student code prediction: i) code similarity to the ground-truth, ii) error matching, and iii) code prediction diversity. On two real-world datasets, we perform two levels of evaluation and show that: At the per-student-problem pair level, our method outperforms baselines on code and error prediction; at the per-problem level, our method outperforms baselines on error coverage and simulated code diversity.
LookAlike: Consistent Distractor Generation in Math MCQs
May 03, 2025



Large language models (LLMs) are increasingly used to generate distractors for multiple-choice questions (MCQs), especially in domains like math education. However, existing approaches are limited in ensuring that the generated distractors are consistent with common student errors. We propose LookAlike, a method that improves error-distractor consistency via preference optimization. Our two main innovations are: (a) mining synthetic preference pairs from model inconsistencies, and (b) alternating supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to stabilize training. Unlike prior work that relies on heuristics or manually annotated preference data, LookAlike uses its own generation inconsistencies as dispreferred samples, thus enabling scalable and stable training. Evaluated on a real-world dataset of 1,400+ math MCQs, LookAlike achieves 51.6% accuracy in distractor generation and 57.2% in error generation under LLM-as-a-judge evaluation, outperforming an existing state-of-the-art method (45.6% / 47.7%). These improvements highlight the effectiveness of preference-based regularization and inconsistency mining for generating consistent math MCQ distractors at scale.
Automated Knowledge Component Generation and Knowledge Tracing for Coding Problems
Feb 25, 2025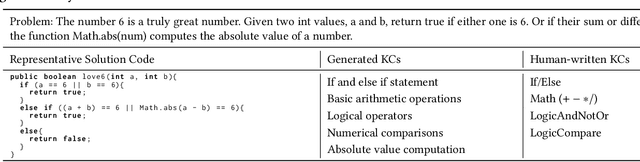
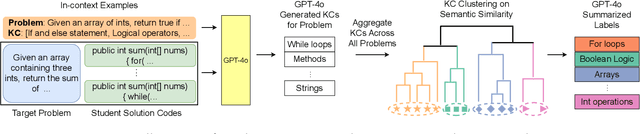
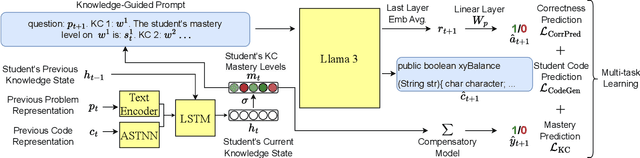
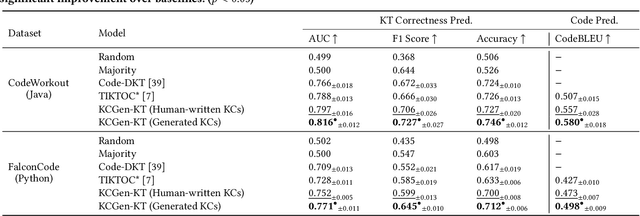
Knowledge components (KCs) mapped to problems help model student learning, tracking their mastery levels on fine-grained skills thereby facilitating personalized learning and feedback in online learning platforms. However, crafting and tagging KCs to problems, traditionally performed by human domain experts, is highly labor-intensive. We present a fully automated, LLM-based pipeline for KC generation and tagging for open-ended programming problems. We also develop an LLM-based knowledge tracing (KT) framework to leverage these LLM-generated KCs, which we refer to as KCGen-KT. We conduct extensive quantitative and qualitative evaluations validating the effectiveness of KCGen-KT. On a real-world dataset of student code submissions to open-ended programming problems, KCGen-KT outperforms existing KT methods. We investigate the learning curves of generated KCs and show that LLM-generated KCs have a comparable level-of-fit to human-written KCs under the performance factor analysis (PFA) model. We also conduct a human evaluation to show that the KC tagging accuracy of our pipeline is reasonably accurate when compared to that by human domain experts.
DiVERT: Distractor Generation with Variational Errors Represented as Text for Math Multiple-choice Questions
Jun 27, 2024



High-quality distractors are crucial to both the assessment and pedagogical value of multiple-choice questions (MCQs), where manually crafting ones that anticipate knowledge deficiencies or misconceptions among real students is difficult. Meanwhile, automated distractor generation, even with the help of large language models (LLMs), remains challenging for subjects like math. It is crucial to not only identify plausible distractors but also understand the error behind them. In this paper, we introduce DiVERT (Distractor Generation with Variational Errors Represented as Text), a novel variational approach that learns an interpretable representation of errors behind distractors in math MCQs. Through experiments on a real-world math MCQ dataset with 1,434 questions used by hundreds of thousands of students, we show that DiVERT, despite using a base open-source LLM with 7B parameters, outperforms state-of-the-art approaches using GPT-4o on downstream distractor generation. We also conduct a human evaluation with math educators and find that DiVERT leads to error labels that are of comparable quality to human-authored ones.
Interpreting Latent Student Knowledge Representations in Programming Assignments
May 13, 2024
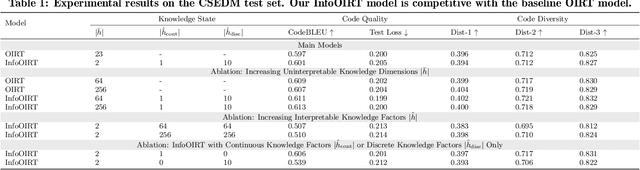
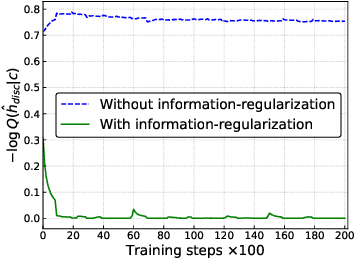

Recent advances in artificial intelligence for education leverage generative large language models, including using them to predict open-ended student responses rather than their correctness only. However, the black-box nature of these models limits the interpretability of the learned student knowledge representations. In this paper, we conduct a first exploration into interpreting latent student knowledge representations by presenting InfoOIRT, an Information regularized Open-ended Item Response Theory model, which encourages the latent student knowledge states to be interpretable while being able to generate student-written code for open-ended programming questions. InfoOIRT maximizes the mutual information between a fixed subset of latent knowledge states enforced with simple prior distributions and generated student code, which encourages the model to learn disentangled representations of salient syntactic and semantic code features including syntactic styles, mastery of programming skills, and code structures. Through experiments on a real-world programming education dataset, we show that InfoOIRT can both accurately generate student code and lead to interpretable student knowledge representations.
3HAN: A Deep Neural Network for Fake News Detection
Jun 21, 2023The rapid spread of fake news is a serious problem calling for AI solutions. We employ a deep learning based automated detector through a three level hierarchical attention network (3HAN) for fast, accurate detection of fake news. 3HAN has three levels, one each for words, sentences, and the headline, and constructs a news vector: an effective representation of an input news article, by processing an article in an hierarchical bottom-up manner. The headline is known to be a distinguishing feature of fake news, and furthermore, relatively few words and sentences in an article are more important than the rest. 3HAN gives a differential importance to parts of an article, on account of its three layers of attention. By experiments on a large real-world data set, we observe the effectiveness of 3HAN with an accuracy of 96.77%. Unlike some other deep learning models, 3HAN provides an understandable output through the attention weights given to different parts of an article, which can be visualized through a heatmap to enable further manual fact checking.
Improving Reading Comprehension Question Generation with Data Augmentation and Overgenerate-and-rank
Jun 15, 2023



Reading comprehension is a crucial skill in many aspects of education, including language learning, cognitive development, and fostering early literacy skills in children. Automated answer-aware reading comprehension question generation has significant potential to scale up learner support in educational activities. One key technical challenge in this setting is that there can be multiple questions, sometimes very different from each other, with the same answer; a trained question generation method may not necessarily know which question human educators would prefer. To address this challenge, we propose 1) a data augmentation method that enriches the training dataset with diverse questions given the same context and answer and 2) an overgenerate-and-rank method to select the best question from a pool of candidates. We evaluate our method on the FairytaleQA dataset, showing a 5% absolute improvement in ROUGE-L over the best existing method. We also demonstrate the effectiveness of our method in generating harder, "implicit" questions, where the answers are not contained in the context as text spans.
Automated Scoring for Reading Comprehension via In-context BERT Tuning
May 19, 2022
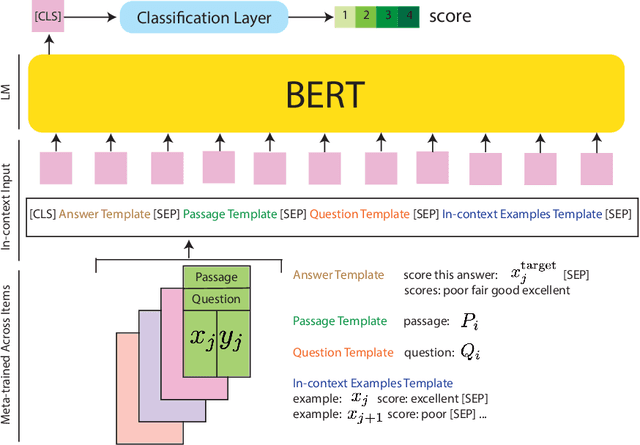

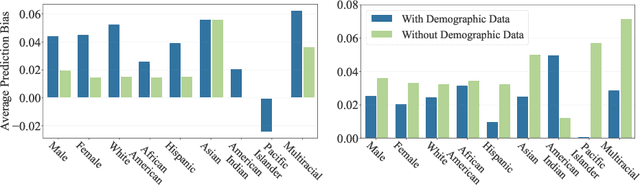
Automated scoring of open-ended student responses has the potential to significantly reduce human grader effort. Recent advances in automated scoring often leverage textual representations based on pre-trained language models such as BERT and GPT as input to scoring models. Most existing approaches train a separate model for each item/question, which is suitable for scenarios such as essay scoring where items can be quite different from one another. However, these approaches have two limitations: 1) they fail to leverage item linkage for scenarios such as reading comprehension where multiple items may share a reading passage; 2) they are not scalable since storing one model per item becomes difficult when models have a large number of parameters. In this paper, we report our (grand prize-winning) solution to the National Assessment of Education Progress (NAEP) automated scoring challenge for reading comprehension. Our approach, in-context BERT fine-tuning, produces a single shared scoring model for all items with a carefully-designed input structure to provide contextual information on each item. We demonstrate the effectiveness of our approach via local evaluations using the training dataset provided by the challenge. We also discuss the biases, common error types, and limitations of our approach.
Synthesizing Tasks for Block-based Programming
Jul 01, 2020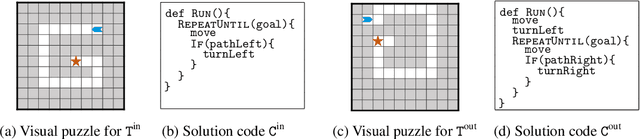
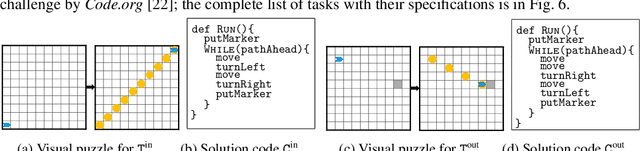
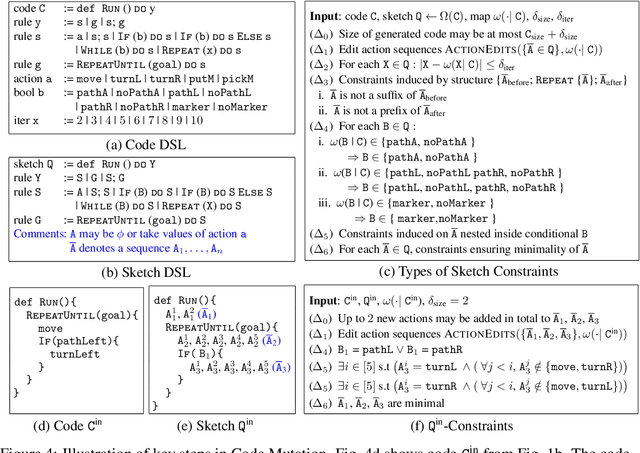

Block-based visual programming environments play a critical role in introducing computing concepts to K-12 students. One of the key pedagogical challenges in these environments is in designing new practice tasks for a student that match a desired level of difficulty and exercise specific programming concepts. In this paper, we formalize the problem of synthesizing visual programming tasks. In particular, given a reference visual task $\rm T^{in}$ and its solution code $\rm C^{in}$, we propose a novel methodology to automatically generate a set $\{(\rm T^{out}, \rm C^{out})\}$ of new tasks along with solution codes such that tasks $\rm T^{in}$ and $\rm T^{out}$ are conceptually similar but visually dissimilar. Our methodology is based on the realization that the mapping from the space of visual tasks to their solution codes is highly discontinuous; hence, directly mutating reference task $\rm T^{in}$ to generate new tasks is futile. Our task synthesis algorithm operates by first mutating code $\rm C^{in}$ to obtain a set of codes $\{\rm C^{out}\}$. Then, the algorithm performs symbolic execution over a code $\rm C^{out}$ to obtain a visual task $\rm T^{out}$; this step uses the Monte Carlo Tree Search (MCTS) procedure to guide the search in the symbolic tree. We demonstrate the effectiveness of our algorithm through an extensive empirical evaluation and user study on reference tasks taken from the \emph{Hour of the Code: Classic Maze} challenge by \emph{Code.org} and the \emph{Intro to Programming with Karel} course by \emph{CodeHS.com}.