 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyrax: An Extensible Framework for Rapid ML Experimentation and Unsupervised Discovery in the Era of Rubin, Roman, and Euclid
May 18, 2026The NSF-DOE Vera C. Rubin Observatory, Roman Space Telescope, Euclid, and other next-generation surveys will deliver imaging, spectroscopic, and time-domain data at scales that increasingly shift the bottleneck in astronomical machine learning (ML) projects from model design to infrastructure. We present Hyrax, an open-source, modular, GPU-enabled Python framework that supports the full ML lifecycle in astronomy: from data acquisition and training to inference and experiment comparison, with capabilities including multimodal dataset support, integrated vector databases for similarity search, and interactive two- and three-dimensional latent-space exploration for unsupervised discovery. We demonstrate Hyrax's versatility through five representative applications on real survey data: (i) unsupervised representation learning on $\sim 4\times10^5$ Rubin Legacy Survey of Space and Time (LSST) Data Preview 1 (DP1) galaxies, surfacing new merger and low-surface-brightness candidates missing from reference Euclid and Dark Energy Survey catalogs, while also isolating imaging artifacts -- all without labeled training data; (ii) hybrid density-based clustering for identifying cluster-scale gravitational lens candidates in DP1 data; (iii) multimodal early-time transient classification in the Zwicky Transient Facility leveraging light curves, spectra, images, and metadata; (iv) supervised false-positive filtering in shift-and-stack searches for distant solar system objects in the Dark Energy Camera Ecliptic Exploration Project survey; and (v) supervised detection of semi-resolved dwarf galaxies in Hyper Suprime-Cam and LSST-like imaging using synthetic source injection. Together, these results demonstrate that Hyrax provides astronomy-specific ML infrastructure that enables systematic discovery and rapid methodological iteration across next-generation astronomical surveys.
Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
Automatic Machine Learning Framework to Study Morphological Parameters of AGN Host Galaxies within $z < 1.4$ in the Hyper Supreme-Cam Wide Survey
Jan 27, 2025We present a composite machine learning framework to estimate posterior probability distributions of bulge-to-total light ratio, half-light radius, and flux for Active Galactic Nucleus (AGN) host galaxies within $z<1.4$ and $m<23$ in the Hyper Supreme-Cam Wide survey. We divide the data into five redshift bins: low ($0<z<0.25$), mid ($0.25<z<0.5$), high ($0.5<z<0.9$), extra ($0.9<z<1.1$) and extreme ($1.1<z<1.4$), and train our models independently in each bin. We use PSFGAN to decompose the AGN point source light from its host galaxy, and invoke the Galaxy Morphology Posterior Estimation Network (GaMPEN) to estimate morphological parameters of the recovered host galaxy. We first trained our models on simulated data, and then fine-tuned our algorithm via transfer learning using labeled real data. To create training labels for transfer learning, we used GALFIT to fit $\sim 20,000$ real HSC galaxies in each redshift bin. We comprehensively examined that the predicted values from our final models agree well with the GALFIT values for the vast majority of cases. Our PSFGAN + GaMPEN framework runs at least three orders of magnitude faster than traditional light-profile fitting methods, and can be easily retrained for other morphological parameters or on other datasets with diverse ranges of resolutions, seeing conditions, and signal-to-noise ratios, making it an ideal tool for analyzing AGN host galaxies from large surveys coming soon from the Rubin-LSST, Euclid, and Roman telescopes.
A Conceptual Model for End-to-End Causal Discovery in Knowledge Tracing
May 11, 2023



In this paper, we take a preliminary step towards solving the problem of causal discovery in knowledge tracing, i.e., finding the underlying causal relationship among different skills from real-world student response data. This problem is important since it can potentially help us understand the causal relationship between different skills without extensive A/B testing, which can potentially help educators to design better curricula according to skill prerequisite information. Specifically, we propose a conceptual solution, a novel causal gated recurrent unit (GRU) module in a modified deep knowledge tracing model, which uses i) a learnable permutation matrix for causal ordering among skills and ii) an optionally learnable lower-triangular matrix for causal structure among skills. We also detail how to learn the model parameters in an end-to-end, differentiable way. Our solution placed among the top entries in Task 3 of the NeurIPS 2022 Challenge on Causal Insights for Learning Paths in Education. We detail preliminary experiments as evaluated on the challenge's public leaderboard since the ground truth causal structure has not been publicly released, making detailed local evaluation impossible.
Using Machine Learning to Determine Morphologies of $z<1$ AGN Host Galaxies in the Hyper Suprime-Cam Wide Survey
Dec 20, 2022We present a machine-learning framework to accurately characterize morphologies of Active Galactic Nucleus (AGN) host galaxies within $z<1$. We first use PSFGAN to decouple host galaxy light from the central point source, then we invoke the Galaxy Morphology Network (GaMorNet) to estimate whether the host galaxy is disk-dominated, bulge-dominated, or indeterminate. Using optical images from five bands of the HSC Wide Survey, we build models independently in three redshift bins: low $(0<z<0.25)$, medium $(0.25<z<0.5)$, and high $(0.5<z<1.0)$. By first training on a large number of simulated galaxies, then fine-tuning using far fewer classified real galaxies, our framework predicts the actual morphology for $\sim$ $60\%-70\%$ host galaxies from test sets, with a classification precision of $\sim$ $80\%-95\%$, depending on redshift bin. Specifically, our models achieve disk precision of $96\%/82\%/79\%$ and bulge precision of $90\%/90\%/80\%$ (for the 3 redshift bins), at thresholds corresponding to indeterminate fractions of $30\%/43\%/42\%$. The classification precision of our models has a noticeable dependency on host galaxy radius and magnitude. No strong dependency is observed on contrast ratio. Comparing classifications of real AGNs, our models agree well with traditional 2D fitting with GALFIT. The PSFGAN+GaMorNet framework does not depend on the choice of fitting functions or galaxy-related input parameters, runs orders of magnitude faster than GALFIT, and is easily generalizable via transfer learning, making it an ideal tool for studying AGN host galaxy morphology in forthcoming large imaging survey.
Automated Scoring for Reading Comprehension via In-context BERT Tuning
May 19, 2022
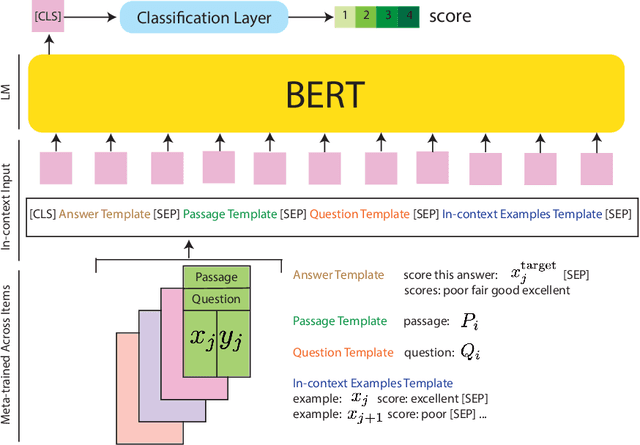

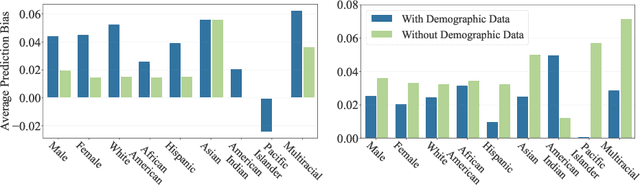
Automated scoring of open-ended student responses has the potential to significantly reduce human grader effort. Recent advances in automated scoring often leverage textual representations based on pre-trained language models such as BERT and GPT as input to scoring models. Most existing approaches train a separate model for each item/question, which is suitable for scenarios such as essay scoring where items can be quite different from one another. However, these approaches have two limitations: 1) they fail to leverage item linkage for scenarios such as reading comprehension where multiple items may share a reading passage; 2) they are not scalable since storing one model per item becomes difficult when models have a large number of parameters. In this paper, we report our (grand prize-winning) solution to the National Assessment of Education Progress (NAEP) automated scoring challenge for reading comprehension. Our approach, in-context BERT fine-tuning, produces a single shared scoring model for all items with a carefully-designed input structure to provide contextual information on each item. We demonstrate the effectiveness of our approach via local evaluations using the training dataset provided by the challenge. We also discuss the biases, common error types, and limitations of our approach.
DiPS: Differentiable Policy for Sketching in Recommender Systems
Dec 08, 2021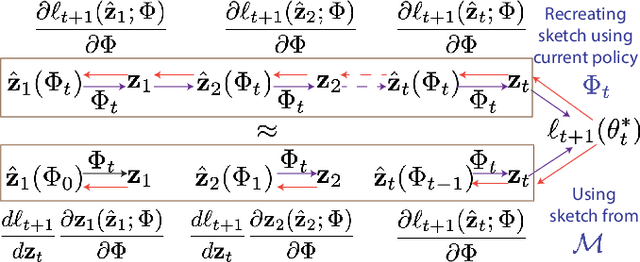

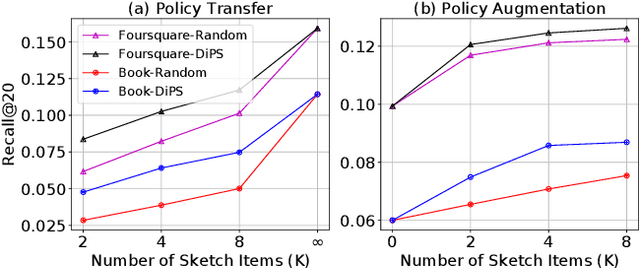
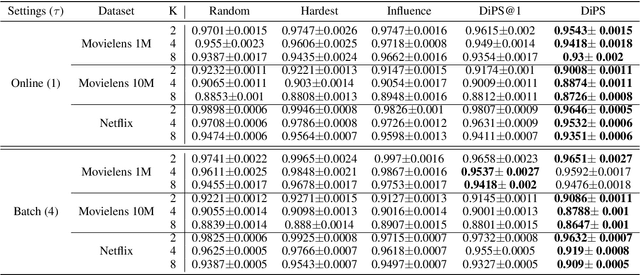
In sequential recommender system applications, it is important to develop models that can capture users' evolving interest over time to successfully recommend future items that they are likely to interact with. For users with long histories, typical models based on recurrent neural networks tend to forget important items in the distant past. Recent works have shown that storing a small sketch of past items can improve sequential recommendation tasks. However, these works all rely on static sketching policies, i.e., heuristics to select items to keep in the sketch, which are not necessarily optimal and cannot improve over time with more training data. In this paper, we propose a differentiable policy for sketching (DiPS), a framework that learns a data-driven sketching policy in an end-to-end manner together with the recommender system model to explicitly maximize recommendation quality in the future. We also propose an approximate estimator of the gradient for optimizing the sketching algorithm parameters that is computationally efficient. We verify the effectiveness of DiPS on real-world datasets under various practical settings and show that it requires up to $50\%$ fewer sketch items to reach the same predictive quality than existing sketching policies.
BOBCAT: Bilevel Optimization-Based Computerized Adaptive Testing
Aug 17, 2021
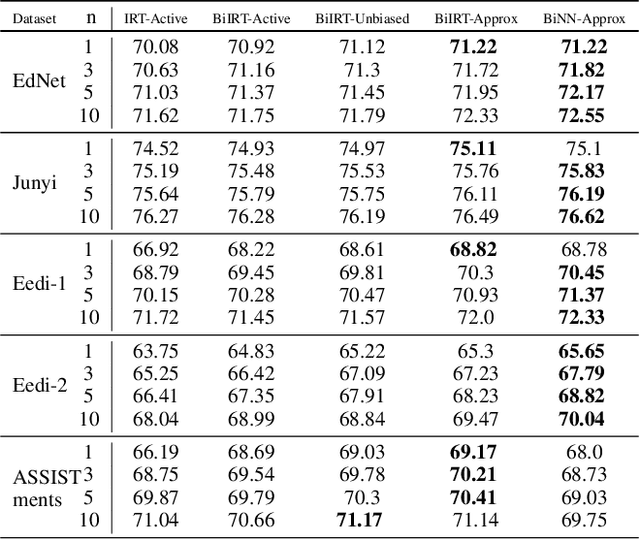
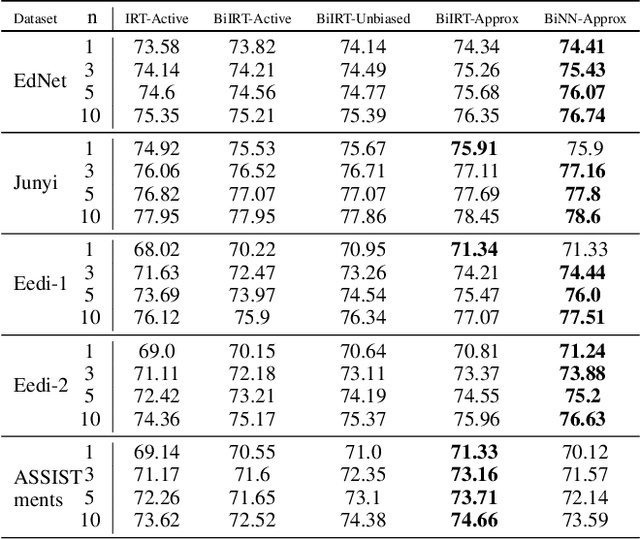

Computerized adaptive testing (CAT) refers to a form of tests that are personalized to every student/test taker. CAT methods adaptively select the next most informative question/item for each student given their responses to previous questions, effectively reducing test length. Existing CAT methods use item response theory (IRT) models to relate student ability to their responses to questions and static question selection algorithms designed to reduce the ability estimation error as quickly as possible; therefore, these algorithms cannot improve by learning from large-scale student response data. In this paper, we propose BOBCAT, a Bilevel Optimization-Based framework for CAT to directly learn a data-driven question selection algorithm from training data. BOBCAT is agnostic to the underlying student response model and is computationally efficient during the adaptive testing process. Through extensive experiments on five real-world student response datasets, we show that BOBCAT outperforms existing CAT methods (sometimes significantly) at reducing test length.
Do We Really Need Gold Samples for Sample Weighting Under Label Noise?
Apr 19, 2021
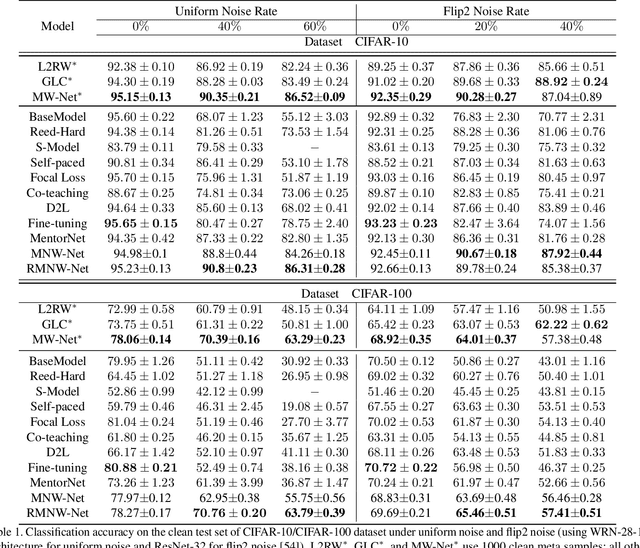
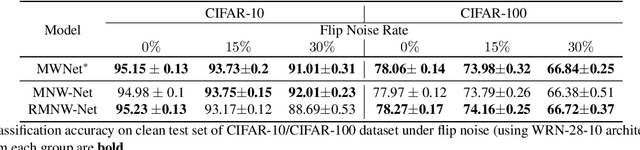
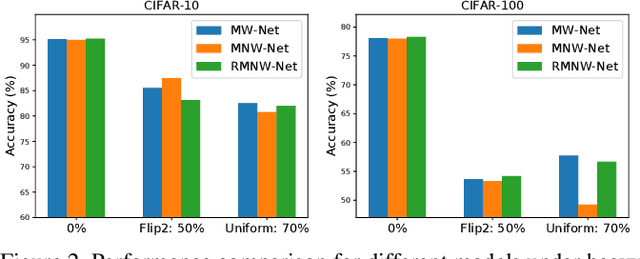
Learning with labels noise has gained significant traction recently due to the sensitivity of deep neural networks under label noise under common loss functions. Losses that are theoretically robust to label noise, however, often makes training difficult. Consequently, several recently proposed methods, such as Meta-Weight-Net (MW-Net), use a small number of unbiased, clean samples to learn a weighting function that downweights samples that are likely to have corrupted labels under the meta-learning framework. However, obtaining such a set of clean samples is not always feasible in practice. In this paper, we analytically show that one can easily train MW-Net without access to clean samples simply by using a loss function that is robust to label noise, such as mean absolute error, as the meta objective to train the weighting network. We experimentally show that our method beats all existing methods that do not use clean samples and performs on-par with methods that use gold samples on benchmark datasets across various noise types and noise rates.
Option Tracing: Beyond Correctness Analysis in Knowledge Tracing
Apr 19, 2021
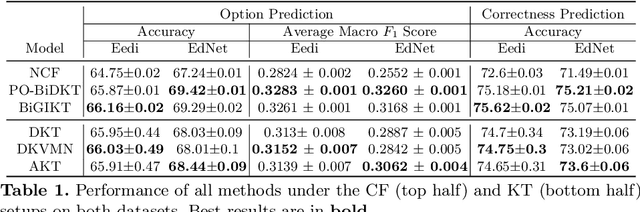

Knowledge tracing refers to a family of methods that estimate each student's knowledge component/skill mastery level from their past responses to questions. One key limitation of most existing knowledge tracing methods is that they can only estimate an \emph{overall} knowledge level of a student per knowledge component/skill since they analyze only the (usually binary-valued) correctness of student responses. Therefore, it is hard to use them to diagnose specific student errors. In this paper, we extend existing knowledge tracing methods beyond correctness prediction to the task of predicting the exact option students select in multiple choice questions. We quantitatively evaluate the performance of our option tracing methods on two large-scale student response datasets. We also qualitatively evaluate their ability in identifying common student errors in the form of clusters of incorrect options across different questions that correspond to the same error.