 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPS: Differentiable Policy for Sketching in Recommender Systems
Paper and Code
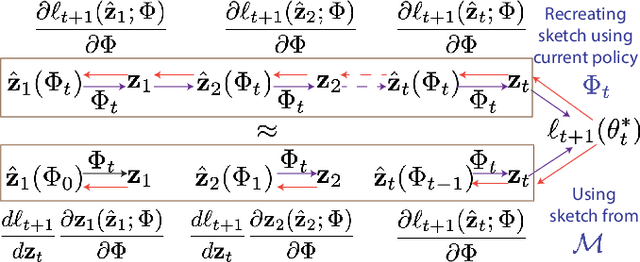

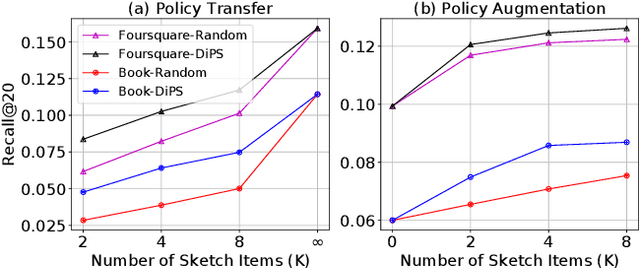
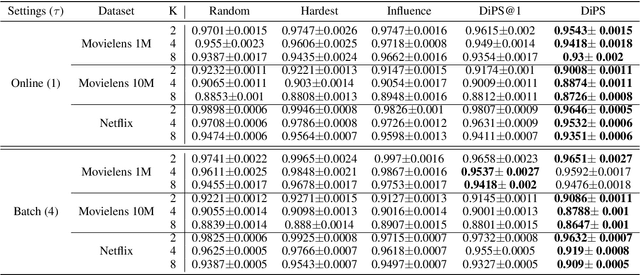
In sequential recommender system applications, it is important to develop models that can capture users' evolving interest over time to successfully recommend future items that they are likely to interact with. For users with long histories, typical models based on recurrent neural networks tend to forget important items in the distant past. Recent works have shown that storing a small sketch of past items can improve sequential recommendation tasks. However, these works all rely on static sketching policies, i.e., heuristics to select items to keep in the sketch, which are not necessarily optimal and cannot improve over time with more training data. In this paper, we propose a differentiable policy for sketching (DiPS), a framework that learns a data-driven sketching policy in an end-to-end manner together with the recommender system model to explicitly maximize recommendation quality in the future. We also propose an approximate estimator of the gradient for optimizing the sketching algorithm parameters that is computationally efficient. We verify the effectiveness of DiPS on real-world datasets under various practical settings and show that it requires up to $50\%$ fewer sketch items to reach the same predictive quality than existing sketching policies.