 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Machine Learning Framework to Study Morphological Parameters of AGN Host Galaxies within $z < 1.4$ in the Hyper Supreme-Cam Wide Survey
Jan 27, 2025We present a composite machine learning framework to estimate posterior probability distributions of bulge-to-total light ratio, half-light radius, and flux for Active Galactic Nucleus (AGN) host galaxies within $z<1.4$ and $m<23$ in the Hyper Supreme-Cam Wide survey. We divide the data into five redshift bins: low ($0<z<0.25$), mid ($0.25<z<0.5$), high ($0.5<z<0.9$), extra ($0.9<z<1.1$) and extreme ($1.1<z<1.4$), and train our models independently in each bin. We use PSFGAN to decompose the AGN point source light from its host galaxy, and invoke the Galaxy Morphology Posterior Estimation Network (GaMPEN) to estimate morphological parameters of the recovered host galaxy. We first trained our models on simulated data, and then fine-tuned our algorithm via transfer learning using labeled real data. To create training labels for transfer learning, we used GALFIT to fit $\sim 20,000$ real HSC galaxies in each redshift bin. We comprehensively examined that the predicted values from our final models agree well with the GALFIT values for the vast majority of cases. Our PSFGAN + GaMPEN framework runs at least three orders of magnitude faster than traditional light-profile fitting methods, and can be easily retrained for other morphological parameters or on other datasets with diverse ranges of resolutions, seeing conditions, and signal-to-noise ratios, making it an ideal tool for analyzing AGN host galaxies from large surveys coming soon from the Rubin-LSST, Euclid, and Roman telescopes.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
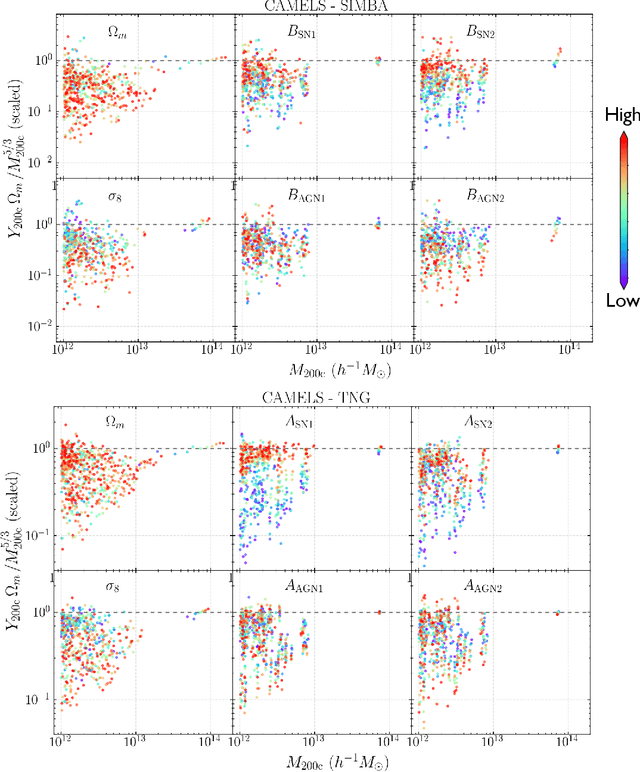
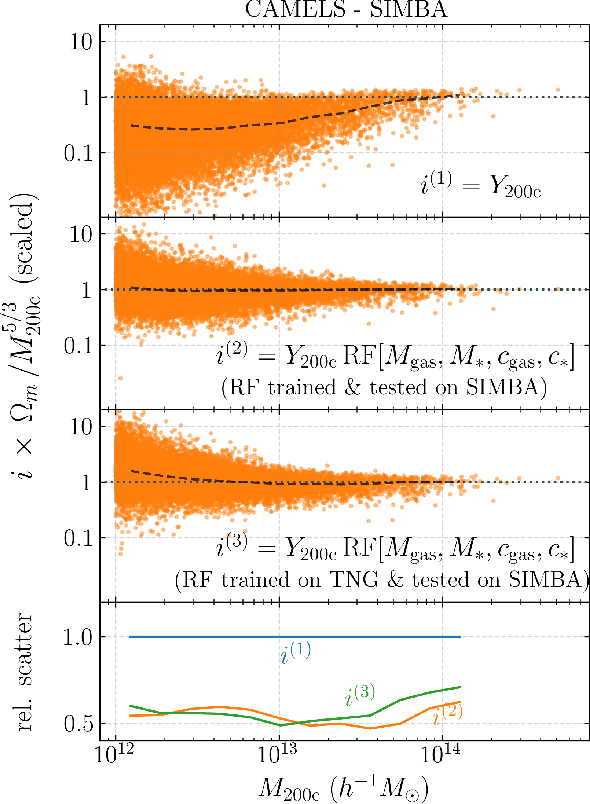

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
The CAMELS project: public data release
Jan 04, 2022
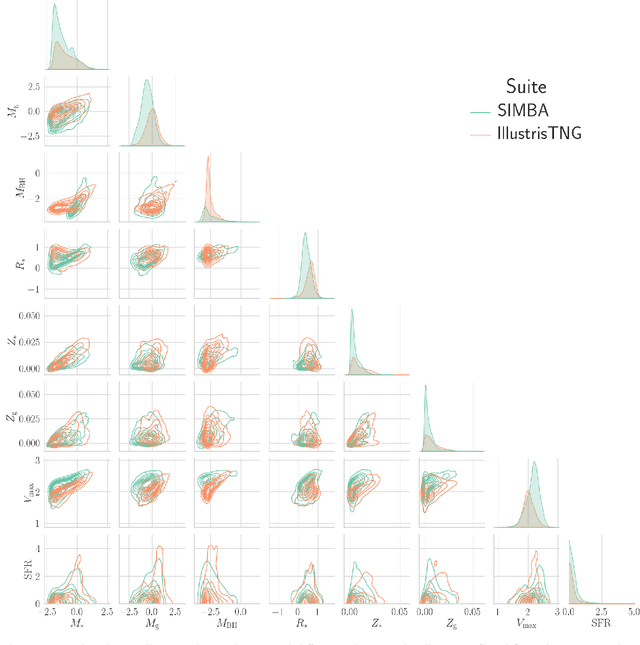
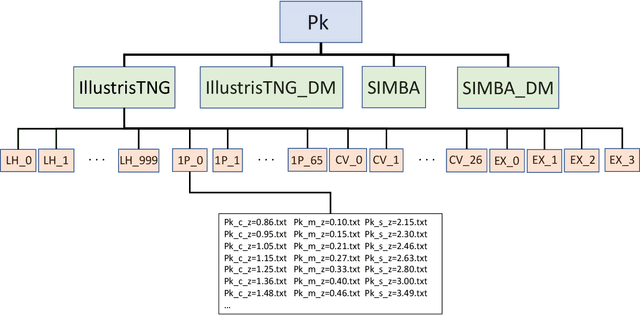
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021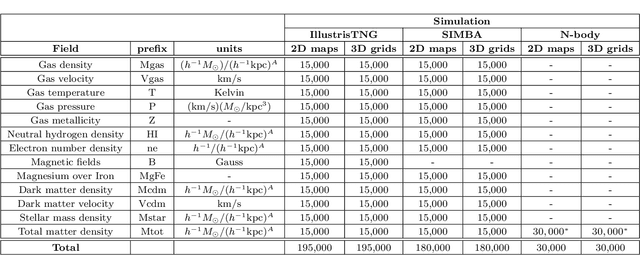

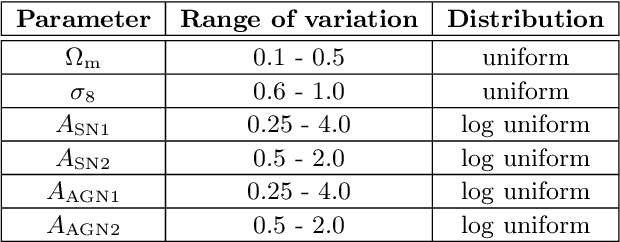
We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.