 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalactification: painting galaxies onto dark matter only simulations using a transformer-based model
Nov 11, 2025



Connecting the formation and evolution of galaxies to the large-scale structure is crucial for interpreting cosmological observations. While hydrodynamical simulations accurately model the correlated properties of galaxies, they are computationally prohibitive to run over volumes that match modern surveys. We address this by developing a framework to rapidly generate mock galaxy catalogs conditioned on inexpensive dark-matter-only simulations. We present a multi-modal, transformer-based model that takes 3D dark matter density and velocity fields as input, and outputs a corresponding point cloud of galaxies with their physical properties. We demonstrate that our trained model faithfully reproduces a variety of galaxy summary statistics and correctly captures their variation with changes in the underlying cosmological and astrophysical parameters, making it the first accelerated forward model to capture all the relevant galaxy properties, their full spatial distribution, and their conditional dependencies in hydrosimulations.
syren-new: Precise formulae for the linear and nonlinear matter power spectra with massive neutrinos and dynamical dark energy
Oct 18, 2024



Current and future large scale structure surveys aim to constrain the neutrino mass and the equation of state of dark energy. We aim to construct accurate and interpretable symbolic approximations to the linear and nonlinear matter power spectra as a function of cosmological parameters in extended $\Lambda$CDM models which contain massive neutrinos and non-constant equations of state for dark energy. This constitutes an extension of the syren-halofit emulators to incorporate these two effects, which we call syren-new (SYmbolic-Regression-ENhanced power spectrum emulator with NEutrinos and $W_0-w_a$). We also obtain a simple approximation to the derived parameter $\sigma_8$ as a function of the cosmological parameters for these models. Our results for the linear power spectrum are designed to emulate CLASS, whereas for the nonlinear case we aim to match the results of EuclidEmulator2. We compare our results to existing emulators and $N$-body simulations. Our analytic emulators for $\sigma_8$, the linear and nonlinear power spectra achieve root mean squared errors of 0.1%, 0.3% and 1.3%, respectively, across a wide range of cosmological parameters, redshifts and wavenumbers. We verify that emulator-related discrepancies are subdominant compared to observational errors and other modelling uncertainties when computing shear power spectra for LSST-like surveys. Our expressions have similar accuracy to existing (numerical) emulators, but are at least an order of magnitude faster, both on a CPU and GPU. Our work greatly improves the accuracy, speed and range of applicability of current symbolic approximations to the linear and nonlinear matter power spectra. We provide publicly available code for all symbolic approximations found.
CHARM: Creating Halos with Auto-Regressive Multi-stage networks
Sep 13, 2024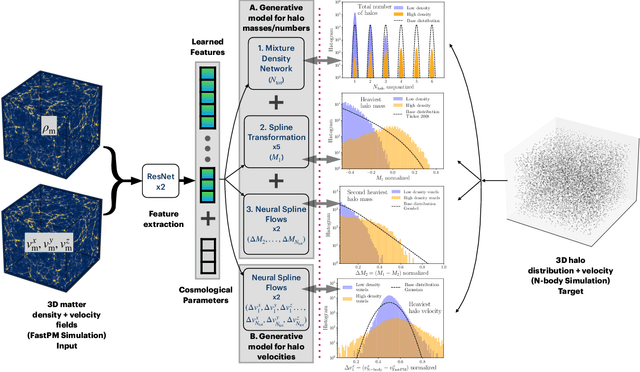
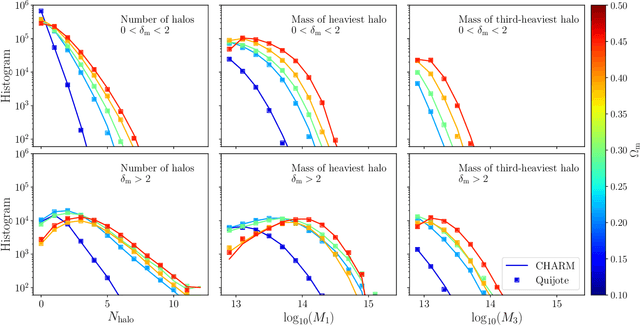
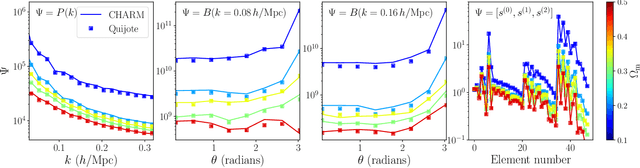
To maximize the amount of information extracted from cosmological datasets, simulations that accurately represent these observations are necessary. However, traditional simulations that evolve particles under gravity by estimating particle-particle interactions (N-body simulations) are computationally expensive and prohibitive to scale to the large volumes and resolutions necessary for the upcoming datasets. Moreover, modeling the distribution of galaxies typically involves identifying virialized dark matter halos, which is also a time- and memory-consuming process for large N-body simulations, further exacerbating the computational cost. In this study, we introduce CHARM, a novel method for creating mock halo catalogs by matching the spatial, mass, and velocity statistics of halos directly from the large-scale distribution of the dark matter density field. We develop multi-stage neural spline flow-based networks to learn this mapping at redshift z=0.5 directly with computationally cheaper low-resolution particle mesh simulations instead of relying on the high-resolution N-body simulations. We show that the mock halo catalogs and painted galaxy catalogs have the same statistical properties as obtained from $N$-body simulations in both real space and redshift space. Finally, we use these mock catalogs for cosmological inference using redshift-space galaxy power spectrum, bispectrum, and wavelet-based statistics using simulation-based inference, performing the first inference with accelerated forward model simulations and finding unbiased cosmological constraints with well-calibrated posteriors. The code was developed as part of the Simons Collaboration on Learning the Universe and is publicly available at \url{https://github.com/shivampcosmo/CHARM}.
IITK at SemEval-2024 Task 1: Contrastive Learning and Autoencoders for Semantic Textual Relatedness in Multilingual Texts
Apr 06, 2024This paper describes our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness. The challenge is focused on automatically detecting the degree of relatedness between pairs of sentences for 14 languages including both high and low-resource Asian and African languages. Our team participated in two subtasks consisting of Track A: supervised and Track B: unsupervised. This paper focuses on a BERT-based contrastive learning and similarity metric based approach primarily for the supervised track while exploring autoencoders for the unsupervised track. It also aims on the creation of a bigram relatedness corpus using negative sampling strategy, thereby producing refined word embeddings.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Feb 06, 2024



This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
The CAMELS project: Expanding the galaxy formation model space with new ASTRID and 28-parameter TNG and SIMBA suites
Apr 04, 2023We present CAMELS-ASTRID, the third suite of hydrodynamical simulations in the Cosmology and Astrophysics with MachinE Learning (CAMELS) project, along with new simulation sets that extend the model parameter space based on the previous frameworks of CAMELS-TNG and CAMELS-SIMBA, to provide broader training sets and testing grounds for machine-learning algorithms designed for cosmological studies. CAMELS-ASTRID employs the galaxy formation model following the ASTRID simulation and contains 2,124 hydrodynamic simulation runs that vary 3 cosmological parameters ($\Omega_m$, $\sigma_8$, $\Omega_b$) and 4 parameters controlling stellar and AGN feedback. Compared to the existing TNG and SIMBA simulation suites in CAMELS, the fiducial model of ASTRID features the mildest AGN feedback and predicts the least baryonic effect on the matter power spectrum. The training set of ASTRID covers a broader variation in the galaxy populations and the baryonic impact on the matter power spectrum compared to its TNG and SIMBA counterparts, which can make machine-learning models trained on the ASTRID suite exhibit better extrapolation performance when tested on other hydrodynamic simulation sets. We also introduce extension simulation sets in CAMELS that widely explore 28 parameters in the TNG and SIMBA models, demonstrating the enormity of the overall galaxy formation model parameter space and the complex non-linear interplay between cosmology and astrophysical processes. With the new simulation suites, we show that building robust machine-learning models favors training and testing on the largest possible diversity of galaxy formation models. We also demonstrate that it is possible to train accurate neural networks to infer cosmological parameters using the high-dimensional TNG-SB28 simulation set.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
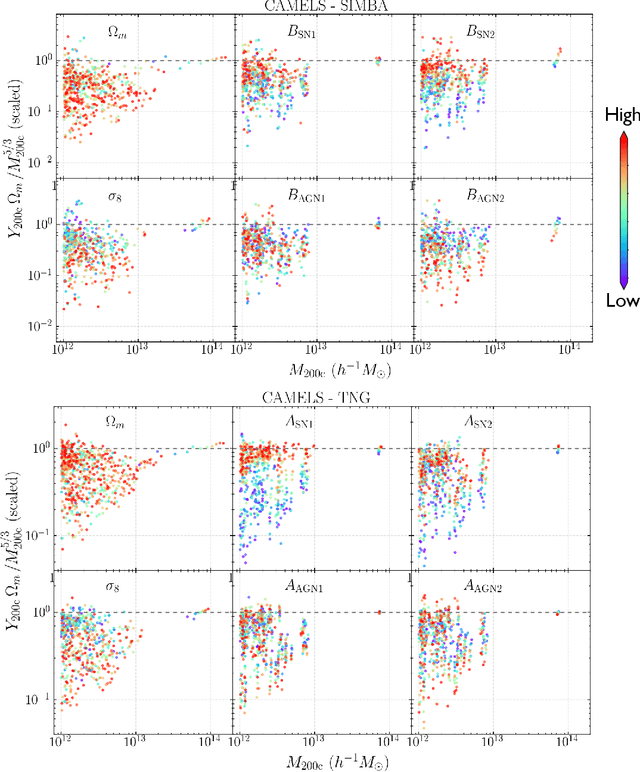
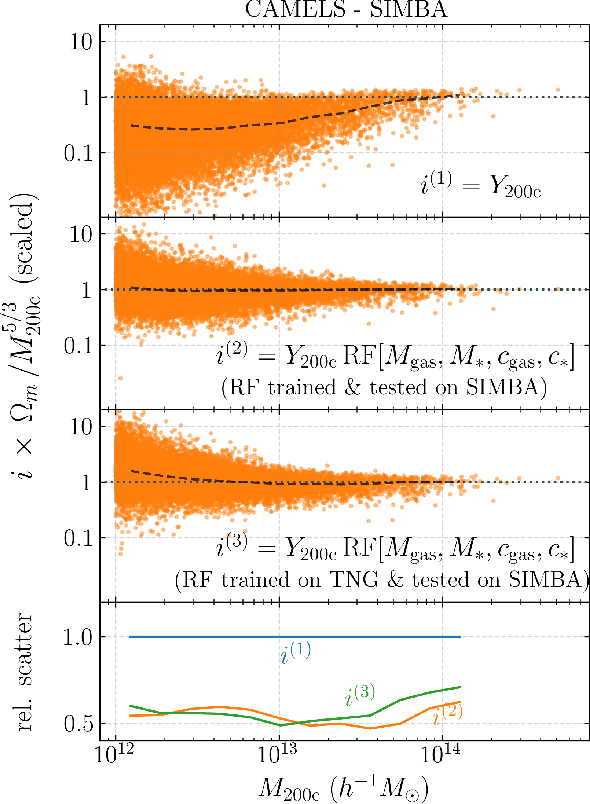

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.