 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAMELS project: Expanding the galaxy formation model space with new ASTRID and 28-parameter TNG and SIMBA suites
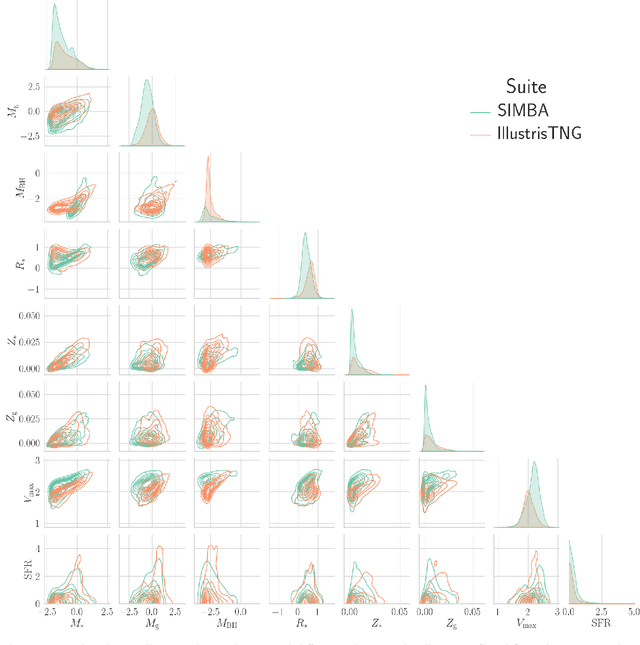
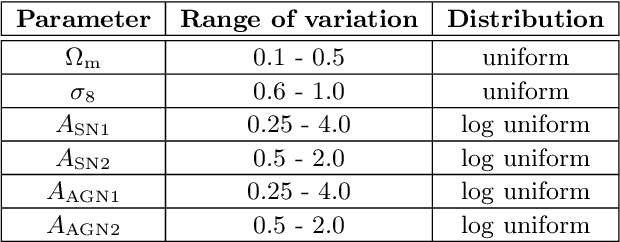
Apr 04, 2023We present CAMELS-ASTRID, the third suite of hydrodynamical simulations in the Cosmology and Astrophysics with MachinE Learning (CAMELS) project, along with new simulation sets that extend the model parameter space based on the previous frameworks of CAMELS-TNG and CAMELS-SIMBA, to provide broader training sets and testing grounds for machine-learning algorithms designed for cosmological studies. CAMELS-ASTRID employs the galaxy formation model following the ASTRID simulation and contains 2,124 hydrodynamic simulation runs that vary 3 cosmological parameters ($\Omega_m$, $\sigma_8$, $\Omega_b$) and 4 parameters controlling stellar and AGN feedback. Compared to the existing TNG and SIMBA simulation suites in CAMELS, the fiducial model of ASTRID features the mildest AGN feedback and predicts the least baryonic effect on the matter power spectrum. The training set of ASTRID covers a broader variation in the galaxy populations and the baryonic impact on the matter power spectrum compared to its TNG and SIMBA counterparts, which can make machine-learning models trained on the ASTRID suite exhibit better extrapolation performance when tested on other hydrodynamic simulation sets. We also introduce extension simulation sets in CAMELS that widely explore 28 parameters in the TNG and SIMBA models, demonstrating the enormity of the overall galaxy formation model parameter space and the complex non-linear interplay between cosmology and astrophysical processes. With the new simulation suites, we show that building robust machine-learning models favors training and testing on the largest possible diversity of galaxy formation models. We also demonstrate that it is possible to train accurate neural networks to infer cosmological parameters using the high-dimensional TNG-SB28 simulation set.
The CAMELS project: public data release
Jan 04, 2022
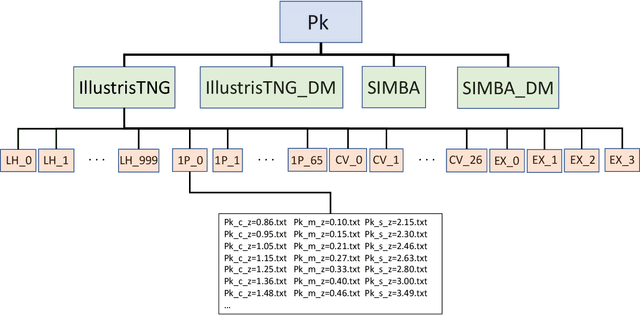
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021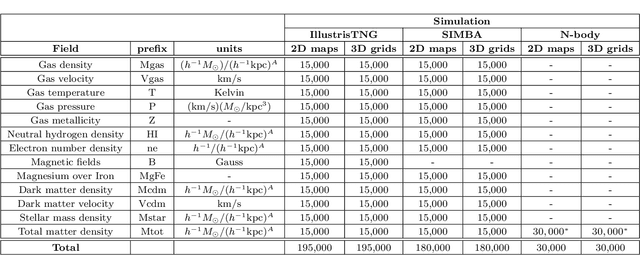

We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.