 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Denario project: Deep knowledge AI agents for scientific discovery
Oct 30, 2025We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
A new approach to template banks of gravitational waves with higher harmonics: reducing matched-filtering cost by over an order of magnitude
Oct 23, 2023Searches for gravitational wave events use models, or templates, for the signals of interest. The templates used in current searches in the LIGO-Virgo-Kagra (LVK) data model the dominant quadrupole mode $(\ell,m)=(2,2)$ of the signals, and omit sub-dominant higher-order modes (HM) such as $(\ell,m)=(3,3)$, $(4,4)$, which are predicted by general relativity. Hence, these searches could lose sensitivity to black hole mergers in interesting parts of parameter space, such as systems with high-masses and asymmetric mass ratios. We develop a new strategy to include HM in template banks that exploits the natural connection between the modes. We use a combination of post-Newtonian formulae and machine learning tools to model aligned-spin $(3,3)$, $(4,4)$ waveforms corresponding to a given $(2,2)$ waveform. Each of these modes can be individually filtered against the data to yield separate timeseries of signal-to-noise ratios (SNR), which can be combined in a relatively inexpensive way to marginalize over extrinsic parameters of the signals. This leads to a HM search pipeline whose matched-filtering cost is just $\approx 3\times$ that of a quadrupole-only search (in contrast to being $\approx\! 100 \times$, as in previously proposed HM search methods). Our method is effectual and is generally applicable for template banks constructed with either stochastic or geometric placement techniques. Additionally, we discuss compression of $(2,2)$-only geometric-placement template banks using machine learning algorithms.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
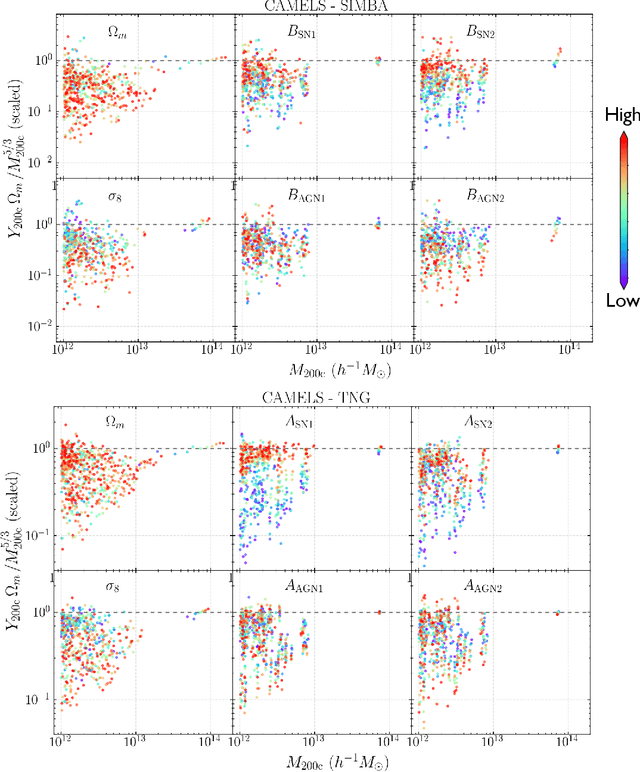
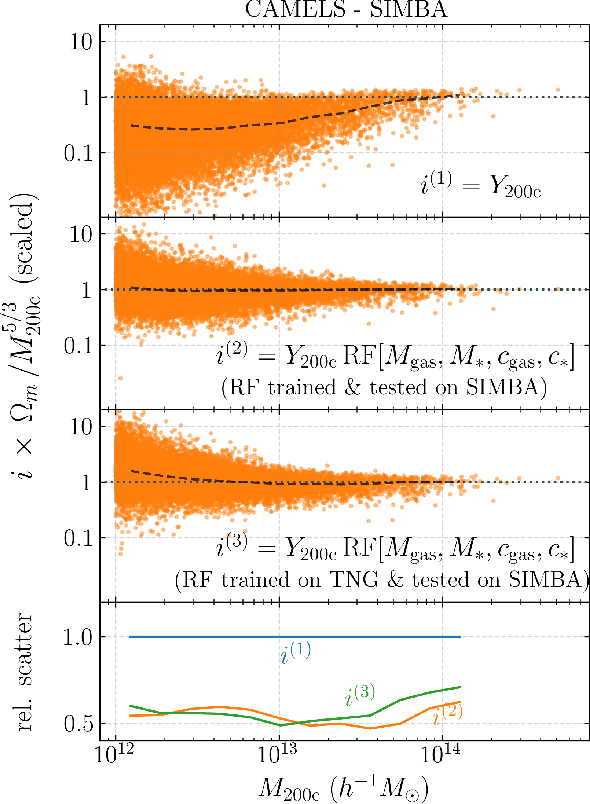

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
Augmenting astrophysical scaling relations with machine learning : application to reducing the SZ flux-mass scatter
Jan 17, 2022
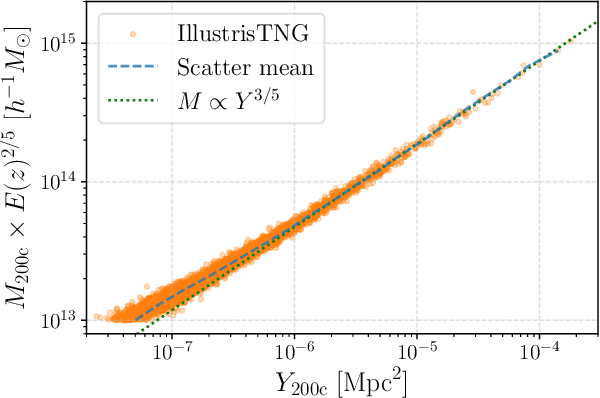

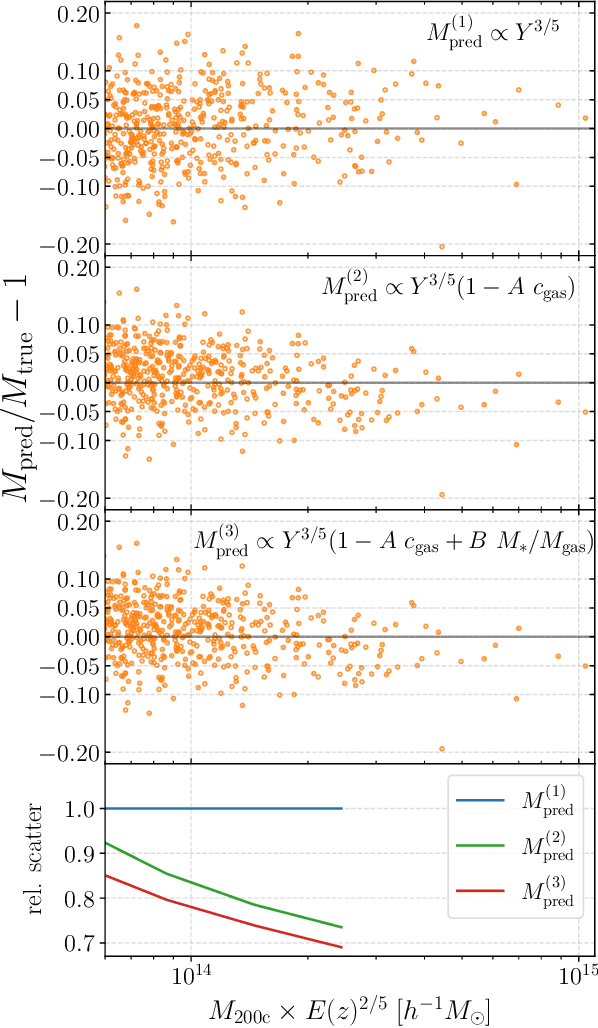
Complex systems (stars, supernovae, galaxies, and clusters) often exhibit low scatter relations between observable properties (e.g., luminosity, velocity dispersion, oscillation period, temperature). These scaling relations can illuminate the underlying physics and can provide observational tools for estimating masses and distances. Machine learning can provide a systematic way to search for new scaling relations (or for simple extensions to existing relations) in abstract high-dimensional parameter spaces. We use a machine learning tool called symbolic regression (SR), which models the patterns in a given dataset in the form of analytic equations. We focus on the Sunyaev-Zeldovich flux$-$cluster mass relation ($Y_\mathrm{SZ}-M$), the scatter in which affects inference of cosmological parameters from cluster abundance data. Using SR on the data from the IllustrisTNG hydrodynamical simulation, we find a new proxy for cluster mass which combines $Y_\mathrm{SZ}$ and concentration of ionized gas ($c_\mathrm{gas}$): $M \propto Y_\mathrm{conc}^{3/5} \equiv Y_\mathrm{SZ}^{3/5} (1-A\, c_\mathrm{gas})$. $Y_\mathrm{conc}$ reduces the scatter in the predicted $M$ by $\sim 20-30$% for large clusters ($M\gtrsim 10^{14}\, h^{-1} \, M_\odot$) at both high and low redshifts, as compared to using just $Y_\mathrm{SZ}$. We show that the dependence on $c_\mathrm{gas}$ is linked to cores of clusters exhibiting larger scatter than their outskirts. Finally, we test $Y_\mathrm{conc}$ on clusters from simulations of the CAMELS project and show that $Y_\mathrm{conc}$ is robust against variations in cosmology, astrophysics, subgrid physics, and cosmic variance. Our results and methodology can be useful for accurate multiwavelength cluster mass estimation from current and upcoming CMB and X-ray surveys like ACT, SO, SPT, eROSITA and CMB-S4.
The CAMELS project: public data release
Jan 04, 2022
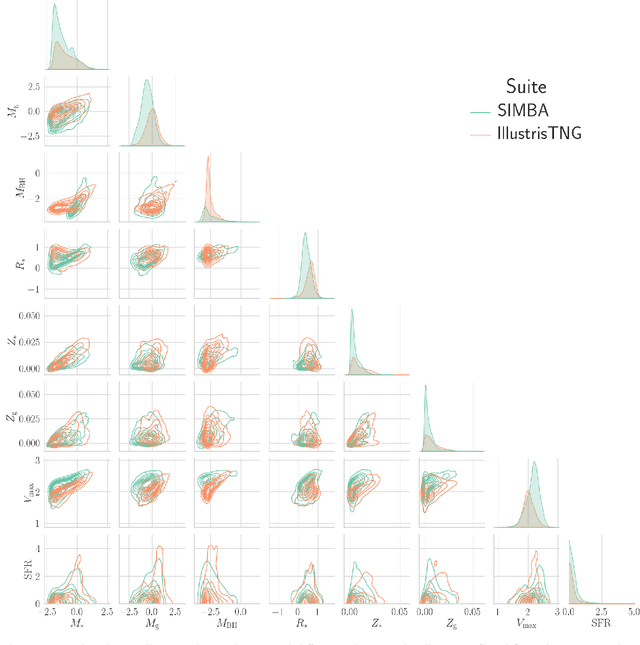
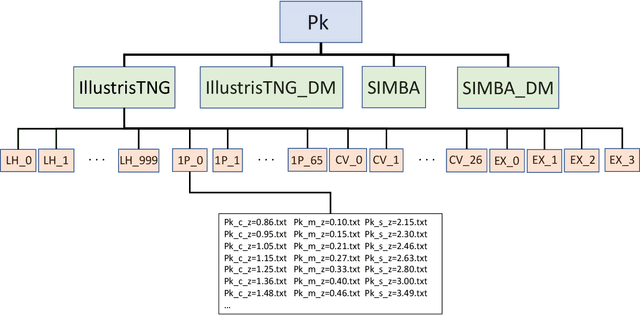
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021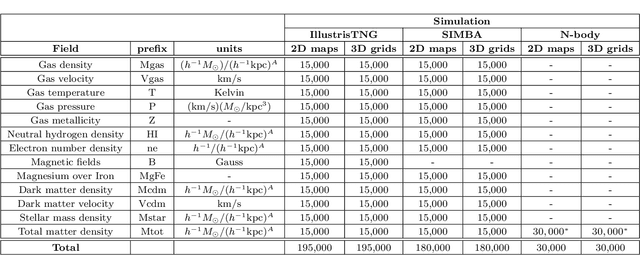

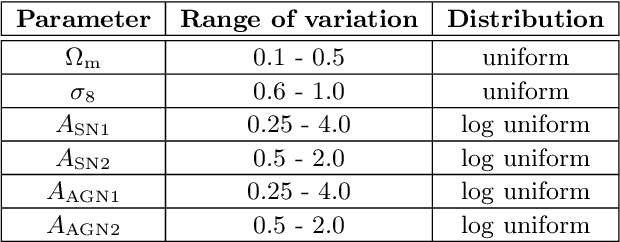
We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.