 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting astrophysical scaling relations with machine learning : application to reducing the SZ flux-mass scatter
Paper and Code
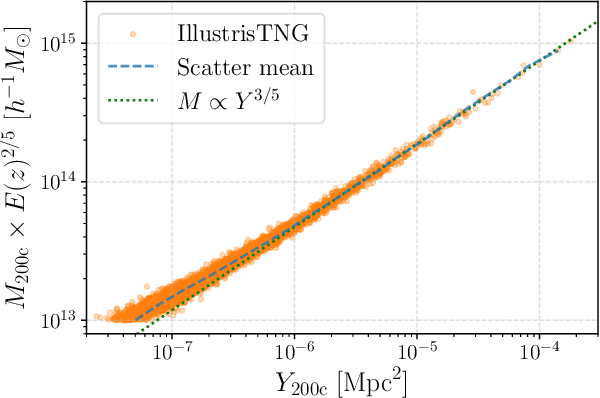

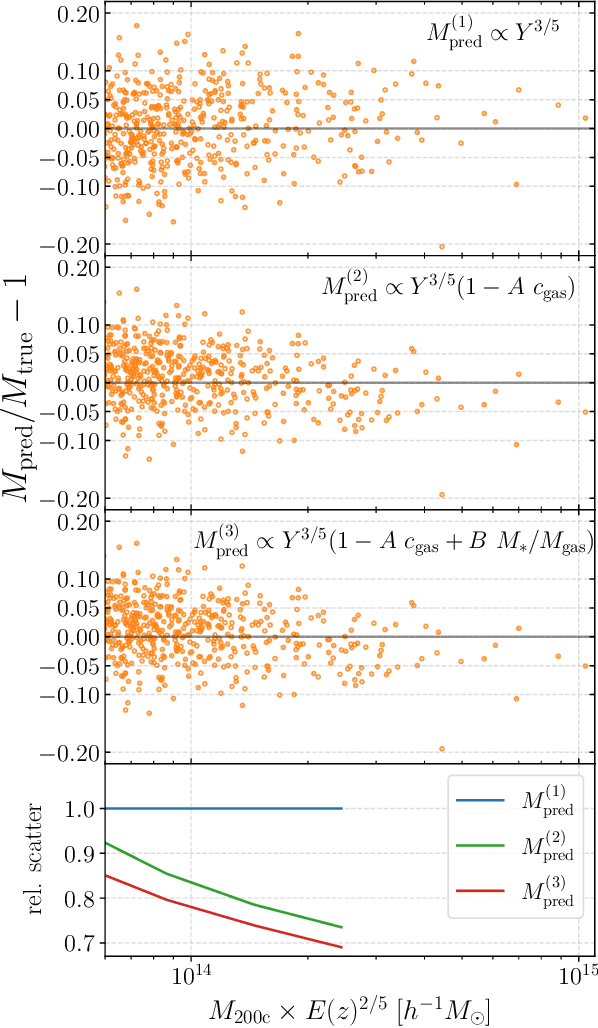
Complex systems (stars, supernovae, galaxies, and clusters) often exhibit low scatter relations between observable properties (e.g., luminosity, velocity dispersion, oscillation period, temperature). These scaling relations can illuminate the underlying physics and can provide observational tools for estimating masses and distances. Machine learning can provide a systematic way to search for new scaling relations (or for simple extensions to existing relations) in abstract high-dimensional parameter spaces. We use a machine learning tool called symbolic regression (SR), which models the patterns in a given dataset in the form of analytic equations. We focus on the Sunyaev-Zeldovich flux$-$cluster mass relation ($Y_\mathrm{SZ}-M$), the scatter in which affects inference of cosmological parameters from cluster abundance data. Using SR on the data from the IllustrisTNG hydrodynamical simulation, we find a new proxy for cluster mass which combines $Y_\mathrm{SZ}$ and concentration of ionized gas ($c_\mathrm{gas}$): $M \propto Y_\mathrm{conc}^{3/5} \equiv Y_\mathrm{SZ}^{3/5} (1-A\, c_\mathrm{gas})$. $Y_\mathrm{conc}$ reduces the scatter in the predicted $M$ by $\sim 20-30$% for large clusters ($M\gtrsim 10^{14}\, h^{-1} \, M_\odot$) at both high and low redshifts, as compared to using just $Y_\mathrm{SZ}$. We show that the dependence on $c_\mathrm{gas}$ is linked to cores of clusters exhibiting larger scatter than their outskirts. Finally, we test $Y_\mathrm{conc}$ on clusters from simulations of the CAMELS project and show that $Y_\mathrm{conc}$ is robust against variations in cosmology, astrophysics, subgrid physics, and cosmic variance. Our results and methodology can be useful for accurate multiwavelength cluster mass estimation from current and upcoming CMB and X-ray surveys like ACT, SO, SPT, eROSITA and CMB-S4.