 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Transfer of a Physics Foundation Model from Simulation to Laboratory Turbulence
May 31, 2026Whether physics foundation models can be usefully deployed on laboratory experiments remains an open question for scientific machine learning (ML). We test this question on the Rayleigh-Taylor instability (RTI), a ubiquitous and demanding fluid instability seen from tabletop flows to supernova explosions, in which small perturbations at a density interface grow into chaotic, multiscale mixing as a lighter fluid accelerates into a heavier one. Standard ML models struggle with RTI, and despite over a century of theoretical, numerical, and experimental work, it carries an unresolved discrepancy between simulation and experiment: the late-time mixing growth rate, $α$, measured in most laboratory experiments ($\sim$ 0.06-0.07), is roughly three times the value from idealized direct numerical simulations (DNS, $\sim$ 0.02). The gap's origin remains debated. These properties make RTI a stringent test for a question that matters well beyond RTI: can foundation models trained only on simulations generalise to sparse, messy, and noisy laboratory settings? We finetune Walrus, a foundation model for continuum dynamics, on three or fewer DNS realizations and recover key RTI physics over long rollouts. Applied zero-shot to sliding-barrier laboratory data, the finetuned model leaves the DNS-like regime and enters the observed growth band, having never seen a single experimental sample. These results provide independent, data-driven evidence that initial conditions play a crucial role in the longstanding sim-experiment gap in $α$. The model also generalises zero-shot to stable stratification, a buoyancy regime absent from training, correctly slowing mixing-layer growth. Together, our results show that foundation models can generalise well beyond their training data, predicting laboratory behavior and unseen physical regimes, opening new ways to probe longstanding simulation-experiment gaps.
MIMIC: A Generative Multimodal Foundation Model for Biomolecules
Apr 27, 2026Biological function emerges from coupled constraints across sequence, structure, regulation, evolution, and cellular context, yet most foundation models in biology are trained within one modality or for a fixed forward task. We present MIMIC, a generative multimodal foundation model trained on our newly curated and aligned dataset, LORE, linking nucleic acid, protein, evolutionary, structural, regulatory, and semantic/contextual modalities within partially observed biomolecular states. MIMIC uses a split-track encoder-decoder architecture to condition on arbitrary subsets of observed modalities and reconstruct or generate missing components of molecular state across the genome, transcriptome, and proteome. Multimodal conditioning consistently improves MIMIC's sequence reconstruction relative to sequence-only inputs, while its learned representations enable state-of-the-art performance on RNA and protein downstream tasks. MIMIC achieves state-of-the-art splicing prediction, and its joint generative formulation enables isoform-aware inference that further improves performance. Beyond prediction, the same generative framework supports constrained design. For RNA, MIMIC identifies corrective edits in a clinically relevant HBB splice-disrupting mutation without reverting it by using evolutionary and structural signals. For proteins, jointly conditioning on shape and surface chemistry of PD-L1 and hACE2 binding sites produces diverse, high-confidence sequences with strong in silico support for target binding. Finally, MIMIC uses experimental context as semantic conditioning to model assay-dependent RNA chemical probing, rather than treating context as a fixed output. Together, these results position MIMIC's aligned multimodal generative modeling as a strong foundation for unifying representation learning, conditional prediction, and constrained biomolecular design within a single model.
Representation Learning for Spatiotemporal Physical Systems
Mar 13, 2026Machine learning approaches to spatiotemporal physical systems have primarily focused on next-frame prediction, with the goal of learning an accurate emulator for the system's evolution in time. However, these emulators are computationally expensive to train and are subject to performance pitfalls, such as compounding errors during autoregressive rollout. In this work, we take a different perspective and look at scientific tasks further downstream of predicting the next frame, such as estimation of a system's governing physical parameters. Accuracy on these tasks offers a uniquely quantifiable glimpse into the physical relevance of the representations of these models. We evaluate the effectiveness of general-purpose self-supervised methods in learning physics-grounded representations that are useful for downstream scientific tasks. Surprisingly, we find that not all methods designed for physical modeling outperform generic self-supervised learning methods on these tasks, and methods that learn in the latent space (e.g., joint embedding predictive architectures, or JEPAs) outperform those optimizing pixel-level prediction objectives. Code is available at https://github.com/helenqu/physical-representation-learning.
Test-time Generalization for Physics through Neural Operator Splitting
Jan 31, 2026Neural operators have shown promise in learning solution maps of partial differential equations (PDEs), but they often struggle to generalize when test inputs lie outside the training distribution, such as novel initial conditions, unseen PDE coefficients or unseen physics. Prior works address this limitation with large-scale multiple physics pretraining followed by fine-tuning, but this still requires examples from the new dynamics, falling short of true zero-shot generalization. In this work, we propose a method to enhance generalization at test time, i.e., without modifying pretrained weights. Building on DISCO, which provides a dictionary of neural operators trained across different dynamics, we introduce a neural operator splitting strategy that, at test time, searches over compositions of training operators to approximate unseen dynamics. On challenging out-of-distribution tasks including parameter extrapolation and novel combinations of physics phenomena, our approach achieves state-of-the-art zero-shot generalization results, while being able to recover the underlying PDE parameters. These results underscore test-time computation as a key avenue for building flexible, compositional, and generalizable neural operators.
Semantic search for 100M+ galaxy images using AI-generated captions
Dec 12, 2025Finding scientifically interesting phenomena through slow, manual labeling campaigns severely limits our ability to explore the billions of galaxy images produced by telescopes. In this work, we develop a pipeline to create a semantic search engine from completely unlabeled image data. Our method leverages Vision-Language Models (VLMs) to generate descriptions for galaxy images, then contrastively aligns a pre-trained multimodal astronomy foundation model with these embedded descriptions to produce searchable embeddings at scale. We find that current VLMs provide descriptions that are sufficiently informative to train a semantic search model that outperforms direct image similarity search. Our model, AION-Search, achieves state-of-the-art zero-shot performance on finding rare phenomena despite training on randomly selected images with no deliberate curation for rare cases. Furthermore, we introduce a VLM-based re-ranking method that nearly doubles the recall for our most challenging targets in the top-100 results. For the first time, AION-Search enables flexible semantic search scalable to 140 million galaxy images, enabling discovery from previously infeasible searches. More broadly, our work provides an approach for making large, unlabeled scientific image archives semantically searchable, expanding data exploration capabilities in fields from Earth observation to microscopy. The code, data, and app are publicly available at https://github.com/NolanKoblischke/AION-Search
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025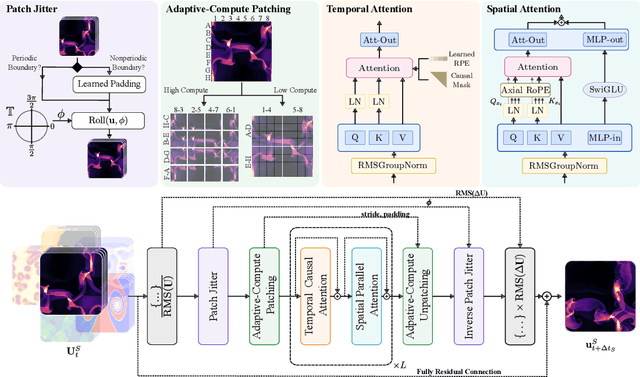


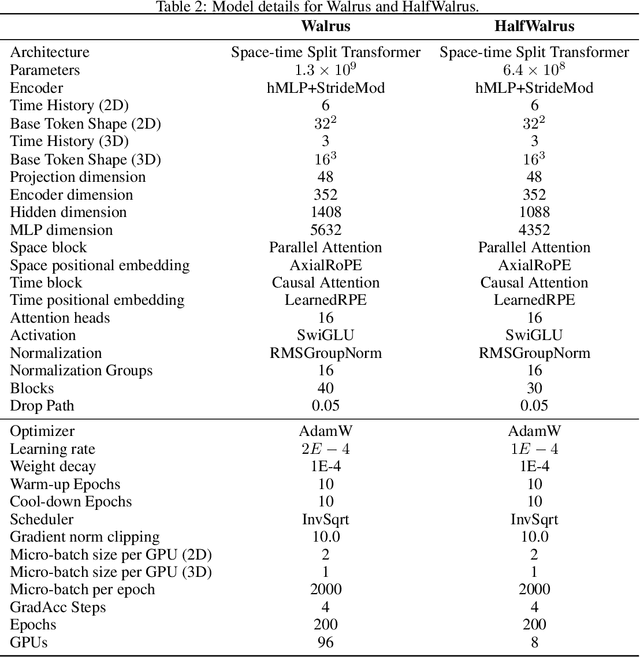
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
Accelerating scientific discovery with the common task framework
Nov 06, 2025Machine learning (ML) and artificial intelligence (AI) algorithms are transforming and empowering the characterization and control of dynamic systems in the engineering, physical, and biological sciences. These emerging modeling paradigms require comparative metrics to evaluate a diverse set of scientific objectives, including forecasting, state reconstruction, generalization, and control, while also considering limited data scenarios and noisy measurements. We introduce a common task framework (CTF) for science and engineering, which features a growing collection of challenge data sets with a diverse set of practical and common objectives. The CTF is a critically enabling technology that has contributed to the rapid advance of ML/AI algorithms in traditional applications such as speech recognition, language processing, and computer vision. There is a critical need for the objective metrics of a CTF to compare the diverse algorithms being rapidly developed and deployed in practice today across science and engineering.
Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation
Jul 03, 2025The steep computational cost of diffusion models at inference hinders their use as fast physics emulators. In the context of image and video generation, this computational drawback has been addressed by generating in the latent space of an autoencoder instead of the pixel space. In this work, we investigate whether a similar strategy can be effectively applied to the emulation of dynamical systems and at what cost. We find that the accuracy of latent-space emulation is surprisingly robust to a wide range of compression rates (up to 1000x). We also show that diffusion-based emulators are consistently more accurate than non-generative counterparts and compensate for uncertainty in their predictions with greater diversity. Finally, we cover practical design choices, spanning from architectures to optimizers, that we found critical to train latent-space emulators.
The Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
Nov 30, 2024



Machine learning based surrogate models offer researchers powerful tools for accelerating simulation-based workflows. However, as standard datasets in this space often cover small classes of physical behavior, it can be difficult to evaluate the efficacy of new approaches. To address this gap, we introduce the Well: a large-scale collection of datasets containing numerical simulations of a wide variety of spatiotemporal physical systems. The Well draws from domain experts and numerical software developers to provide 15TB of data across 16 datasets covering diverse domains such as biological systems, fluid dynamics, acoustic scattering, as well as magneto-hydrodynamic simulations of extra-galactic fluids or supernova explosions. These datasets can be used individually or as part of a broader benchmark suite. To facilitate usage of the Well, we provide a unified PyTorch interface for training and evaluating models. We demonstrate the function of this library by introducing example baselines that highlight the new challenges posed by the complex dynamics of the Well. The code and data is available at https://github.com/PolymathicAI/the_well.
ASURA-FDPS-ML: Star-by-star Galaxy Simulations Accelerated by Surrogate Modeling for Supernova Feedback
Oct 30, 2024



We introduce new high-resolution galaxy simulations accelerated by a surrogate model that reduces the computation cost by approximately 75 percent. Massive stars with a Zero Age Main Sequence mass of about 8 solar masses and above explode as core-collapse supernovae (CCSNe), which play a critical role in galaxy formation. The energy released by CCSNe is essential for regulating star formation and driving feedback processes in the interstellar medium (ISM). However, the short integration timesteps required for SNe feedback present significant bottlenecks in star-by-star galaxy simulations that aim to capture individual stellar dynamics and the inhomogeneous shell expansion of SNe within the turbulent ISM. Our new framework combines direct numerical simulations and surrogate modeling, including machine learning and Gibbs sampling. The star formation history and the time evolution of outflow rates in the galaxy match those obtained from resolved direct numerical simulations. Our new approach achieves high-resolution fidelity while reducing computational costs, effectively bridging the physical scale gap and enabling multi-scale simulations.