 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusability report: Prostate cancer stratification with diverse biologically-informed neural architectures
Sep 28, 2023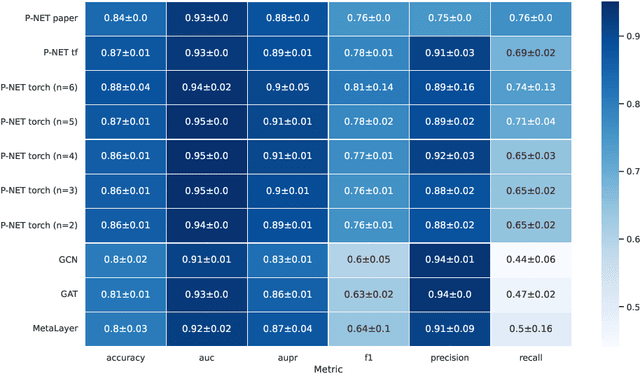
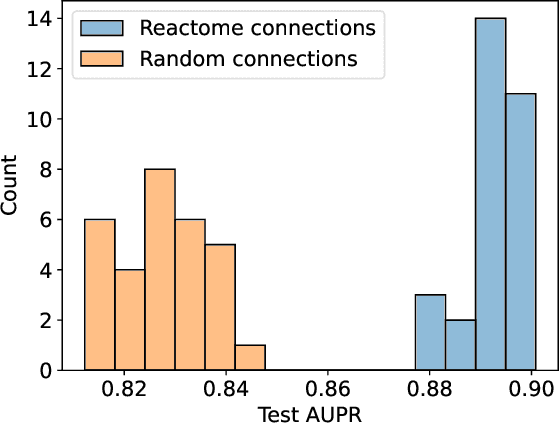
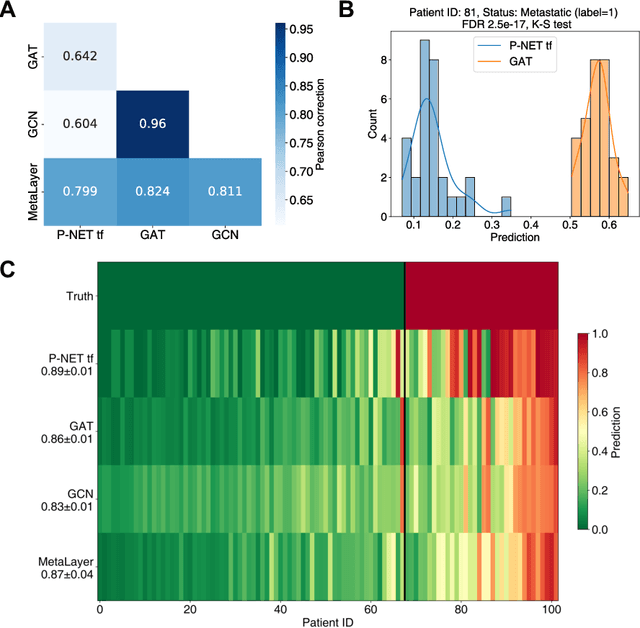
In, Elmarakeby et al., "Biologically informed deep neural network for prostate cancer discovery", a feedforward neural network with biologically informed, sparse connections (P-NET) was presented to model the state of prostate cancer. We verified the reproducibility of the study conducted by Elmarakeby et al., using both their original codebase, and our own re-implementation using more up-to-date libraries. We quantified the contribution of network sparsification by Reactome biological pathways, and confirmed its importance to P-NET's superior performance. Furthermore, we explored alternative neural architectures and approaches to incorporating biological information into the networks. We experimented with three types of graph neural networks on the same training data, and investigated the clinical prediction agreement between different models. Our analyses demonstrated that deep neural networks with distinct architectures make incorrect predictions for individual patient that are persistent across different initializations of a specific neural architecture. This suggests that different neural architectures are sensitive to different aspects of the data, an important yet under-explored challenge for clinical prediction tasks.
Learnable wavelet neural networks for cosmological inference
Jul 24, 2023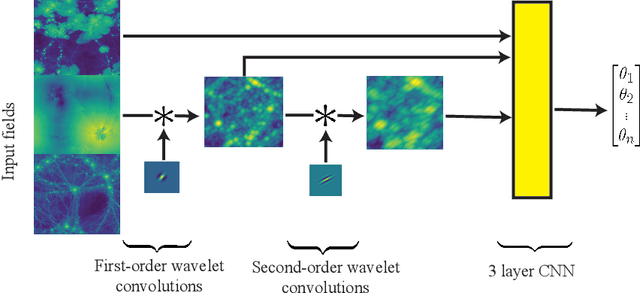
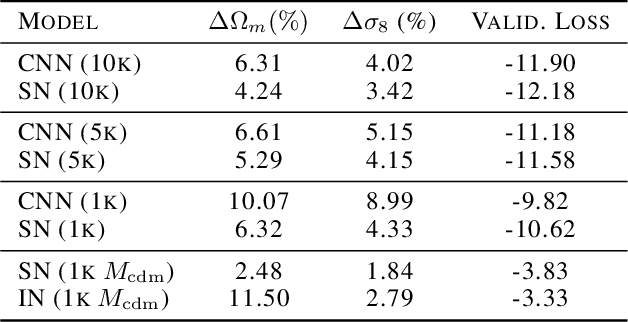
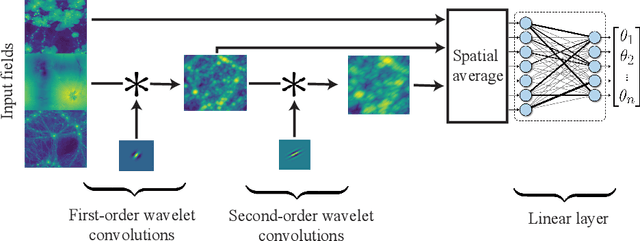
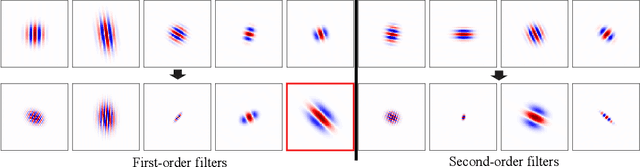
Convolutional neural networks (CNNs) have been shown to both extract more information than the traditional two-point statistics from cosmological fields, and marginalise over astrophysical effects extremely well. However, CNNs require large amounts of training data, which is potentially problematic in the domain of expensive cosmological simulations, and it is difficult to interpret the network. In this work we apply the learnable scattering transform, a kind of convolutional neural network that uses trainable wavelets as filters, to the problem of cosmological inference and marginalisation over astrophysical effects. We present two models based on the scattering transform, one constructed for performance, and one constructed for interpretability, and perform a comparison with a CNN. We find that scattering architectures are able to outperform a CNN, significantly in the case of small training data samples. Additionally we present a lightweight scattering network that is highly interpretable.