 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETRA: Parallel End-to-end Training with Reversible Architectures
Jun 04, 2024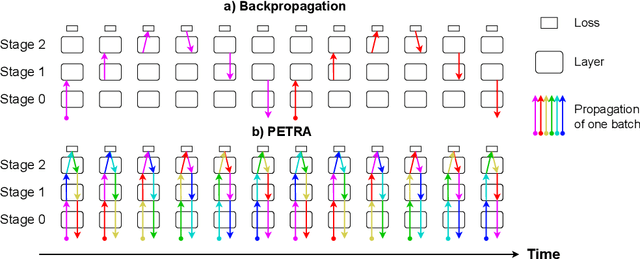
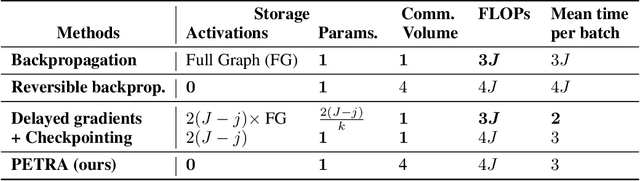
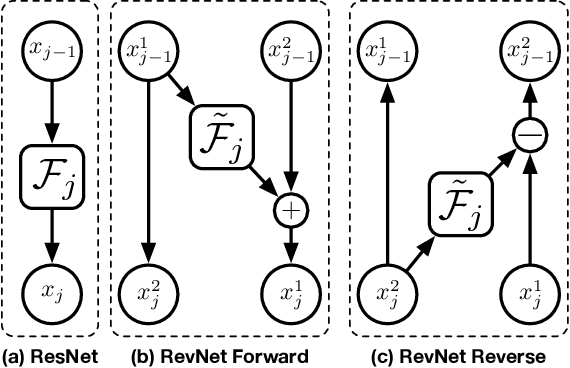
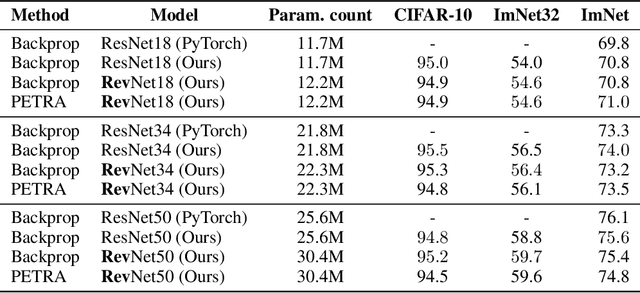
Reversible architectures have been shown to be capable of performing on par with their non-reversible architectures, being applied in deep learning for memory savings and generative modeling. In this work, we show how reversible architectures can solve challenges in parallelizing deep model training. We introduce PETRA, a novel alternative to backpropagation for parallelizing gradient computations. PETRA facilitates effective model parallelism by enabling stages (i.e., a set of layers) to compute independently on different devices, while only needing to communicate activations and gradients between each other. By decoupling the forward and backward passes and keeping a single updated version of the parameters, the need for weight stashing is also removed. We develop a custom autograd-like training framework for PETRA, and we demonstrate its effectiveness on CIFAR-10, ImageNet32, and ImageNet, achieving competitive accuracies comparable to backpropagation using ResNet-18, ResNet-34, and ResNet-50 models.
From Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Jun 03, 2024

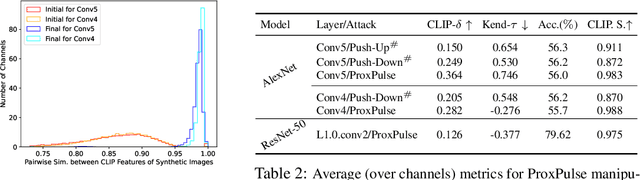
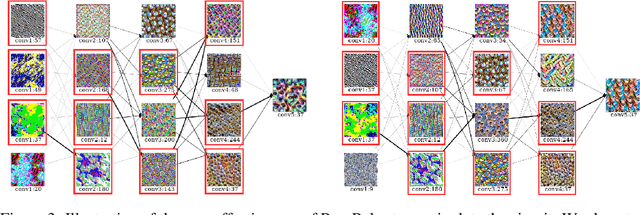
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.
Contextual Counting: A Mechanistic Study of Transformers on a Quantitative Task
May 30, 2024Transformers have revolutionized machine learning across diverse domains, yet understanding their behavior remains crucial, particularly in high-stakes applications. This paper introduces the contextual counting task, a novel toy problem aimed at enhancing our understanding of Transformers in quantitative and scientific contexts. This task requires precise localization and computation within datasets, akin to object detection or region-based scientific analysis. We present theoretical and empirical analysis using both causal and non-causal Transformer architectures, investigating the influence of various positional encodings on performance and interpretability. In particular, we find that causal attention is much better suited for the task, and that no positional embeddings lead to the best accuracy, though rotary embeddings are competitive and easier to train. We also show that out of distribution performance is tightly linked to which tokens it uses as a bias term.
Channel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Feb 07, 2024



Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.
SimBIG: Field-level Simulation-Based Inference of Galaxy Clustering
Oct 23, 2023We present the first simulation-based inference (SBI) of cosmological parameters from field-level analysis of galaxy clustering. Standard galaxy clustering analyses rely on analyzing summary statistics, such as the power spectrum, $P_\ell$, with analytic models based on perturbation theory. Consequently, they do not fully exploit the non-linear and non-Gaussian features of the galaxy distribution. To address these limitations, we use the {\sc SimBIG} forward modelling framework to perform SBI using normalizing flows. We apply SimBIG to a subset of the BOSS CMASS galaxy sample using a convolutional neural network with stochastic weight averaging to perform massive data compression of the galaxy field. We infer constraints on $\Omega_m = 0.267^{+0.033}_{-0.029}$ and $\sigma_8=0.762^{+0.036}_{-0.035}$. While our constraints on $\Omega_m$ are in-line with standard $P_\ell$ analyses, those on $\sigma_8$ are $2.65\times$ tighter. Our analysis also provides constraints on the Hubble constant $H_0=64.5 \pm 3.8 \ {\rm km / s / Mpc}$ from galaxy clustering alone. This higher constraining power comes from additional non-Gaussian cosmological information, inaccessible with $P_\ell$. We demonstrate the robustness of our analysis by showcasing our ability to infer unbiased cosmological constraints from a series of test simulations that are constructed using different forward models than the one used in our training dataset. This work not only presents competitive cosmological constraints but also introduces novel methods for leveraging additional cosmological information in upcoming galaxy surveys like DESI, PFS, and Euclid.
Multiple Physics Pretraining for Physical Surrogate Models
Oct 04, 2023


We introduce multiple physics pretraining (MPP), an autoregressive task-agnostic pretraining approach for physical surrogate modeling. MPP involves training large surrogate models to predict the dynamics of multiple heterogeneous physical systems simultaneously by learning features that are broadly useful across diverse physical tasks. In order to learn effectively in this setting, we introduce a shared embedding and normalization strategy that projects the fields of multiple systems into a single shared embedding space. We validate the efficacy of our approach on both pretraining and downstream tasks over a broad fluid mechanics-oriented benchmark. We show that a single MPP-pretrained transformer is able to match or outperform task-specific baselines on all pretraining sub-tasks without the need for finetuning. For downstream tasks, we demonstrate that finetuning MPP-trained models results in more accurate predictions across multiple time-steps on new physics compared to training from scratch or finetuning pretrained video foundation models. We open-source our code and model weights trained at multiple scales for reproducibility and community experimentation.
AstroCLIP: Cross-Modal Pre-Training for Astronomical Foundation Models
Oct 04, 2023We present AstroCLIP, a strategy to facilitate the construction of astronomical foundation models that bridge the gap between diverse observational modalities. We demonstrate that a cross-modal contrastive learning approach between images and optical spectra of galaxies yields highly informative embeddings of both modalities. In particular, we apply our method on multi-band images and optical spectra from the Dark Energy Spectroscopic Instrument (DESI), and show that: (1) these embeddings are well-aligned between modalities and can be used for accurate cross-modal searches, and (2) these embeddings encode valuable physical information about the galaxies -- in particular redshift and stellar mass -- that can be used to achieve competitive zero- and few- shot predictions without further finetuning. Additionally, in the process of developing our approach, we also construct a novel, transformer-based model and pretraining approach for processing galaxy spectra.
xVal: A Continuous Number Encoding for Large Language Models
Oct 04, 2023Large Language Models have not yet been broadly adapted for the analysis of scientific datasets due in part to the unique difficulties of tokenizing numbers. We propose xVal, a numerical encoding scheme that represents any real number using just a single token. xVal represents a given real number by scaling a dedicated embedding vector by the number value. Combined with a modified number-inference approach, this strategy renders the model end-to-end continuous when considered as a map from the numbers of the input string to those of the output string. This leads to an inductive bias that is generally more suitable for applications in scientific domains. We empirically evaluate our proposal on a number of synthetic and real-world datasets. Compared with existing number encoding schemes, we find that xVal is more token-efficient and demonstrates improved generalization.
Learnable wavelet neural networks for cosmological inference
Jul 24, 2023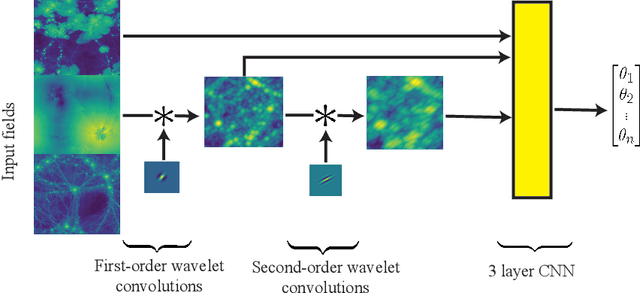
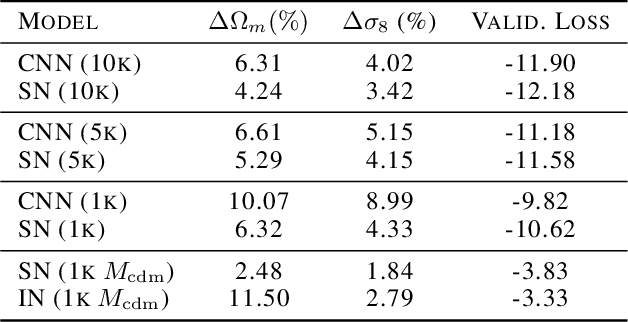
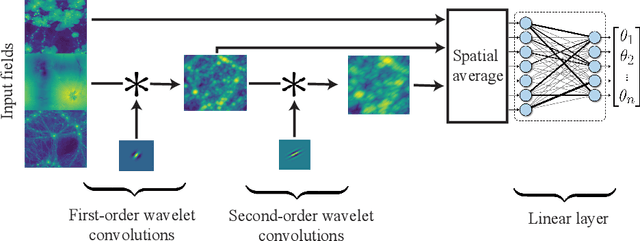
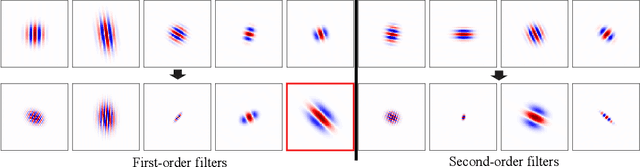
Convolutional neural networks (CNNs) have been shown to both extract more information than the traditional two-point statistics from cosmological fields, and marginalise over astrophysical effects extremely well. However, CNNs require large amounts of training data, which is potentially problematic in the domain of expensive cosmological simulations, and it is difficult to interpret the network. In this work we apply the learnable scattering transform, a kind of convolutional neural network that uses trainable wavelets as filters, to the problem of cosmological inference and marginalisation over astrophysical effects. We present two models based on the scattering transform, one constructed for performance, and one constructed for interpretability, and perform a comparison with a CNN. We find that scattering architectures are able to outperform a CNN, significantly in the case of small training data samples. Additionally we present a lightweight scattering network that is highly interpretable.
Statistical Component Separation for Targeted Signal Recovery in Noisy Mixtures
Jun 26, 2023Separating signals from an additive mixture may be an unnecessarily hard problem when one is only interested in specific properties of a given signal. In this work, we tackle simpler "statistical component separation" problems that focus on recovering a predefined set of statistical descriptors of a target signal from a noisy mixture. Assuming access to samples of the noise process, we investigate a method devised to match the statistics of the solution candidate corrupted by noise samples with those of the observed mixture. We first analyze the behavior of this method using simple examples with analytically tractable calculations. Then, we apply it in an image denoising context employing 1) wavelet-based descriptors, 2) ConvNet-based descriptors on astrophysics and ImageNet data. In the case of 1), we show that our method better recovers the descriptors of the target data than a standard denoising method in most situations. Additionally, despite not constructed for this purpose, it performs surprisingly well in terms of peak signal-to-noise ratio on full signal reconstruction. In comparison, representation 2) appears less suitable for image denoising. Finally, we extend this method by introducing a diffusive stepwise algorithm which gives a new perspective to the initial method and leads to promising results for image denoising under specific circumstances.