 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Refusal Ablation in LLM through Optimal Transport
Mar 04, 2026Safety-aligned language models refuse harmful requests through learned refusal behaviors encoded in their internal representations. Recent activation-based jailbreaking methods circumvent these safety mechanisms by applying orthogonal projections to remove refusal directions, but these approaches treat refusal as a one-dimensional phenomenon and ignore the rich distributional structure of model activations. We introduce a principled framework based on optimal transport theory that transforms the entire distribution of harmful activations to match harmless ones. By combining PCA with closed-form Gaussian optimal transport, we achieve efficient computation in high-dimensional representation spaces while preserving essential geometric structure. Across six models (Llama-2, Llama-3.1, Qwen-2.5; 7B-32B parameters), our method achieves up to 11% higher attack success rates than state-of-the-art baselines while maintaining comparable perplexity, demonstrating superior preservation of model capabilities. Critically, we discover that layer-selective intervention (applying optimal transport to 1-2 carefully chosen layers at approximately 40-60% network depth) substantially outperforms full-network interventions, revealing that refusal mechanisms may be localized rather than distributed. Our analysis provides new insights into the geometric structure of safety representations and suggests that current alignment methods may be vulnerable to distributional attacks beyond simple direction removal.
FairDropout: Using Example-Tied Dropout to Enhance Generalization of Minority Groups
Feb 10, 2025



Deep learning models frequently exploit spurious features in training data to achieve low training error, often resulting in poor generalization when faced with shifted testing distributions. To address this issue, various methods from imbalanced learning, representation learning, and classifier recalibration have been proposed to enhance the robustness of deep neural networks against spurious correlations. In this paper, we observe that models trained with empirical risk minimization tend to generalize well for examples from the majority groups while memorizing instances from minority groups. Building on recent findings that show memorization can be localized to a limited number of neurons, we apply example-tied dropout as a method we term FairDropout, aimed at redirecting this memorization to specific neurons that we subsequently drop out during inference. We empirically evaluate FairDropout using the subpopulation benchmark suite encompassing vision, language, and healthcare tasks, demonstrating that it significantly reduces reliance on spurious correlations, and outperforms state-of-the-art methods.
Not Only the Last-Layer Features for Spurious Correlations: All Layer Deep Feature Reweighting
Sep 23, 2024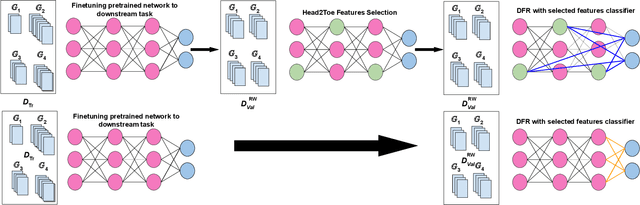
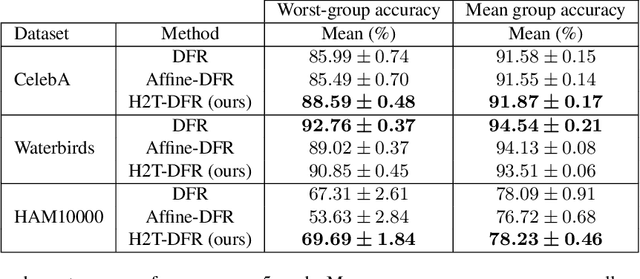
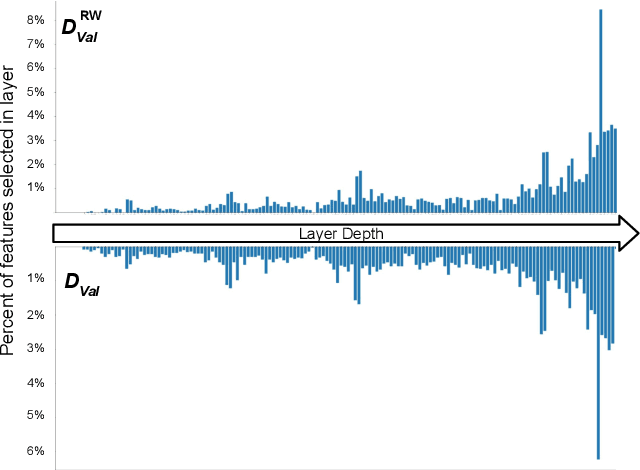
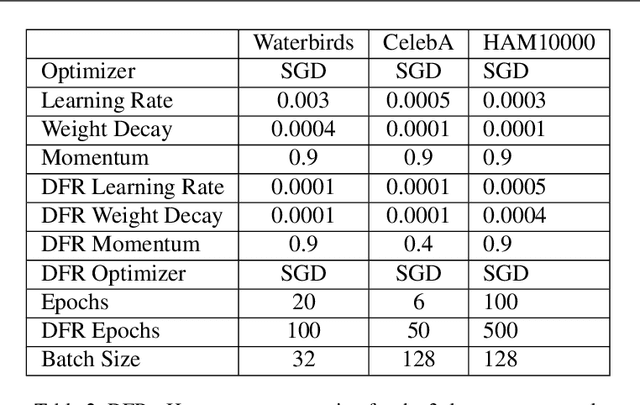
Spurious correlations are a major source of errors for machine learning models, in particular when aiming for group-level fairness. It has been recently shown that a powerful approach to combat spurious correlations is to re-train the last layer on a balanced validation dataset, isolating robust features for the predictor. However, key attributes can sometimes be discarded by neural networks towards the last layer. In this work, we thus consider retraining a classifier on a set of features derived from all layers. We utilize a recently proposed feature selection strategy to select unbiased features from all the layers. We observe this approach gives significant improvements in worst-group accuracy on several standard benchmarks.
From Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Jun 03, 2024

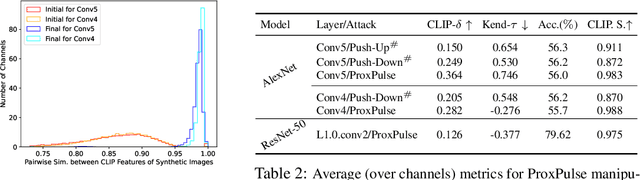
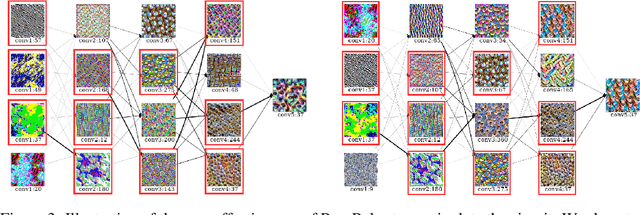
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.
Adversarial Attacks on the Interpretation of Neuron Activation Maximization
Jun 12, 2023The internal functional behavior of trained Deep Neural Networks is notoriously difficult to interpret. Activation-maximization approaches are one set of techniques used to interpret and analyze trained deep-learning models. These consist in finding inputs that maximally activate a given neuron or feature map. These inputs can be selected from a data set or obtained by optimization. However, interpretability methods may be subject to being deceived. In this work, we consider the concept of an adversary manipulating a model for the purpose of deceiving the interpretation. We propose an optimization framework for performing this manipulation and demonstrate a number of ways that popular activation-maximization interpretation techniques associated with CNNs can be manipulated to change the interpretations, shedding light on the reliability of these methods.
Squeeze-SegNet: A new fast Deep Convolutional Neural Network for Semantic Segmentation
Nov 15, 2017The recent researches in Deep Convolutional Neural Network have focused their attention on improving accuracy that provide significant advances. However, if they were limited to classification tasks, nowadays with contributions from Scientific Communities who are embarking in this field, they have become very useful in higher level tasks such as object detection and pixel-wise semantic segmentation. Thus, brilliant ideas in the field of semantic segmentation with deep learning have completed the state of the art of accuracy, however this architectures become very difficult to apply in embedded systems as is the case for autonomous driving. We present a new Deep fully Convolutional Neural Network for pixel-wise semantic segmentation which we call Squeeze-SegNet. The architecture is based on Encoder-Decoder style. We use a SqueezeNet-like encoder and a decoder formed by our proposed squeeze-decoder module and upsample layer using downsample indices like in SegNet and we add a deconvolution layer to provide final multi-channel feature map. On datasets like Camvid or City-states, our net gets SegNet-level accuracy with less than 10 times fewer parameters than SegNet.