 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Paper and Code
Jun 03, 2024

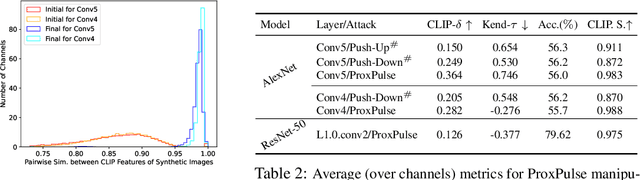
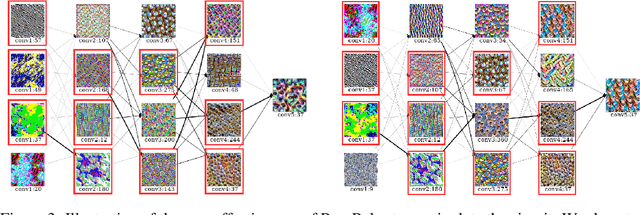
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.