 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Jul 16, 2025
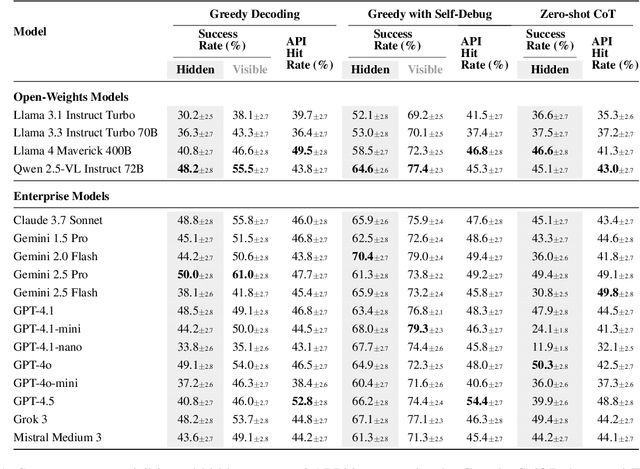
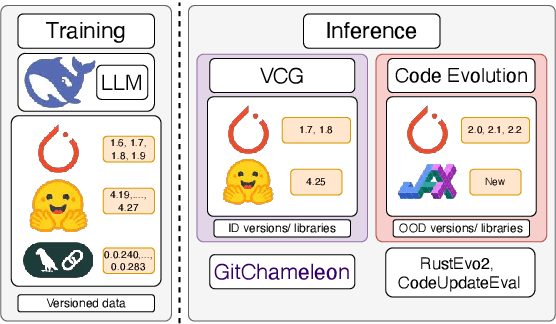
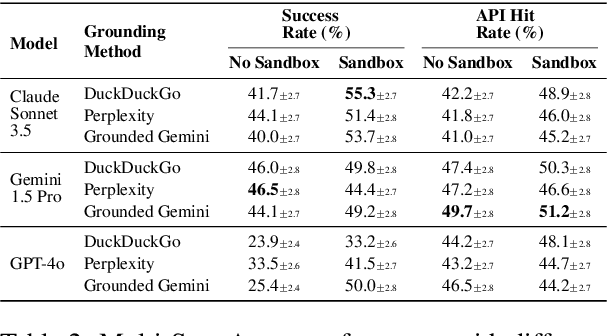
The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to perform version-conditioned code generation that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51\% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We make the dataset and evaluation code publicly available at https://github.com/mrcabbage972/GitChameleonBenchmark.
Channel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Feb 07, 2024



Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.
Simulated Annealing in Early Layers Leads to Better Generalization
Apr 10, 2023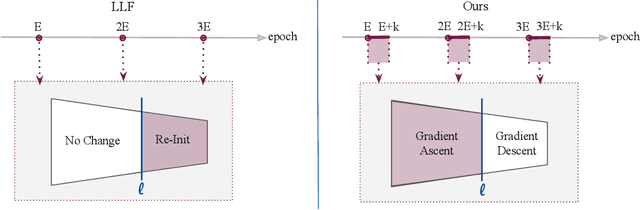
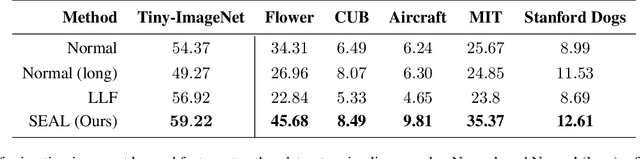
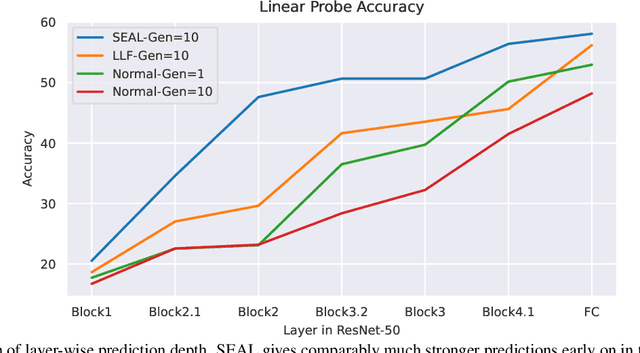
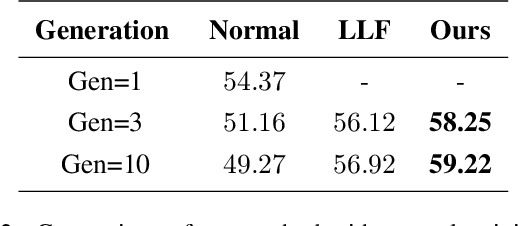
Recently, a number of iterative learning methods have been introduced to improve generalization. These typically rely on training for longer periods of time in exchange for improved generalization. LLF (later-layer-forgetting) is a state-of-the-art method in this category. It strengthens learning in early layers by periodically re-initializing the last few layers of the network. Our principal innovation in this work is to use Simulated annealing in EArly Layers (SEAL) of the network in place of re-initialization of later layers. Essentially, later layers go through the normal gradient descent process, while the early layers go through short stints of gradient ascent followed by gradient descent. Extensive experiments on the popular Tiny-ImageNet dataset benchmark and a series of transfer learning and few-shot learning tasks show that we outperform LLF by a significant margin. We further show that, compared to normal training, LLF features, although improving on the target task, degrade the transfer learning performance across all datasets we explored. In comparison, our method outperforms LLF across the same target datasets by a large margin. We also show that the prediction depth of our method is significantly lower than that of LLF and normal training, indicating on average better prediction performance.